
Abstract
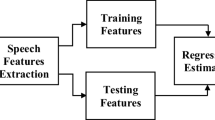
In the present study, we propose a regression-based scheme for the direct estimation of the height of unknown speakers from their speech. In this scheme every speech input is decomposed via the openSMILE audio parameterization to a single feature vector that is fed to a regression model, which provides a direct estimation of the persons’ height. The focus in this study is on the evaluation of the appropriateness of several linear and non-linear regression algorithms on the task of automatic height estimation from speech. The performance of the proposed scheme is evaluated on the TIMIT database, and the experimental results show an accuracy of 0.053 meters, in terms of mean absolute error, for the best performing Bagging regression algorithm. This accuracy corresponds to an averaged relative error of approximately 3%. We deem that the direct estimation of the height of unknown people from speech provides an important additional feature for improving the performance of various surveillance, profiling and access authorization applications.
Similar content being viewed by others

References
Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19(6), 716–723.
Batliner, A., & Huber, R. (2007). Speaker characteristics and emotion classification. In C. Műller (Ed.), LNAI : Vol. 4343. Speaker classification I (pp. 138–151). Berlin: Springer.
Beigi, H. (2010). Fundamentals of speaker recognition. Berlin: Springer. ISBN-13:978-0387775913.
Blomberg, M., & Elenius, D. (2009). Estimating speaker characteristics for speech recognition. In Proc. of the XXIIth Swedish phonetics conference (FONETIK, 2009) (pp. 154–158).
Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2), 123–140.
Campbell, J. P. (1997). Speaker recognition: a tutorial. Proceedings of the IEEE, 85(9).
Chang, C. C., & Lin, C. J. (2002). Training v-support vector regression: theory and algorithms. Neural Computation, 14(8), 1959–1977.
Chester, D. L. (1990). Why two hidden layers are better than one. In Proc. of the international joint conference on neural networks (Vol. 1, pp. 265–268).
Cole et al. (1998). Survey of the state of the art in human language technology (studies in natural language processing). Cambridge: Cambridge University Press. R. Cole, J. Mariani, H. Uszkoreit, G. Battista Varile, A. Zaenen, & A. Zampolli (Eds.). ISBN-13:978-0521592772.
Collins, S. A. (2000). Men’s voices and women’s choices. Animal Behaviour, 60, 773–780.
Cowie, R., & Douglas-Cowie, E. (1995). Speakers and hearers are people: reflections on speech deterioration as a consequence of acquired deafness. In K.-E. Spens & G. Plant (Eds.), Profound deafness and speech communication (pp. 510–527). London: Whurr.
Cowie, R., Douglas-Cowie, E., Tsapatsoulis, N., Votsis, G., Kollias, S., Fellenz, W., & Taylor, J. G. (2001). Emotion recognition in human-computer interaction. IEEE Signal Processing Magazine, 18(1), 32–80.
Davis, S. B., & Mermelstein, P. (1980). Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions Acoustics, Speech and Signal Processing, 28(4), 357–366.
Dusan, S. (2005). Estimation of speaker’s height and vocal tract length from speech signal. In Proc. of the 9th European conference on speech communication and technology (Interspeech 2005) (pp. 1989–1992).
Esposito, A., Bratanic, M., Keller, E., & Marinaro, M. (2007). NATO security through science series E: Human and societal dynamics : Vol. 18. Fundamentals of verbal and nonverbal communication and the biometric issue. Utrecht: IOS Press.
Eyben, F., Wöllmer, M., & Schuller, B. (2009). OpenEAR—introducing the Munich open-source emotion and affect recognition toolkit. In Proc. of the 4th international HUMAINE association conference on affective computing and intelligent interaction (ACII 2009).
Fant, G. (1960). Acoustic theory of speech production. The Hague: Mouton.
Fitch, W. T. (1997). Vocal tract length and formant frequency dispersion correlate with body size in rhesus macaque. Journal of Acoustical Society of America (JASA), 102(2), 1213–1222.
Fitch, W. T., & Giedd, J. (1999). Morphology and development of human vocal tract: a study using magnetic resonance imaging. Journal of Acoustical Society of America (JASA), 106(3), 1511–1522.
Friedman, J. H. (2002). Stochastic gradient boosting. Computational Statistics and Data Analysis, 38(4), 367–378.
Garofolo, J. (1988). Getting started with the DARPA-TIMIT CD-ROM: an acoustic phonetic continuous speech database. National Institute of Standards and Technology (NIST), Gaithersburgh, MD, USA.
Gonzalez, J. (2003). Estimation of speaker’s weight and height from speech: a re-analysis of data from multiple studies by Lass and colleagues. Perceptual and Motor Skills, 96, 297–304.
González, J. (2006). Research in acoustics of human speech sounds: correlates and perception of speaker body size. In S. G. Pandalai (Ed.), Recent research developments in applied physics, Vol. 9. Kerala: Transworld Research Network. ISBN:81-7895-213-0.
Gunter, C. D., & Manning, W. H. (1982). Listener estimations of speaker height and weight in unfiltered and filtered conditions. Journal of Phonetics, 10, 251–257.
Hogg, R., McKean, J., & Craig, A. (2005). Introduction to mathematical statistics. Upper Saddle River: Pearson Prentice Hall, pp. 359–364.
Huang, R., Hansen, J. H. L., & Angkititrakul, P. (2007). Dialect/accent classification using unrestricted audio. IEEE Transactions on Audio, Speech, and Language Processing, 15(2), 453–464.
Jain, A. K., Dass, S. C., & Nandakumar, K. (2004). Can soft biometric traits assist user recognition? In A. K. Jain & N. K. Ratha (Eds.), Biometric technology for human identification. Proceedings of the SPIE 2004 (Vol. 5404, pp. 561–572).
Junqua, J.-C., & Haton, J.-P. (1995). Robustness in automatic speech recognition—fundamental and applications. Dordrecht: Kluwer Academic. ISBN-13:978-0792396468.
Kispál, I., & Jeges, E. (2008). Human height estimation using a calibrated camera. In Proc. of the computer vision and pattern recognition (CVPR 2008).
Kunzel, H. J. (1989). How well does average fundamental frequency correlate with speaker height and weight? Phonetica, 46, 117–125.
Kuroiwa, S., Naito, M., Yamamoto, S., & Higuchi, N. (1999). Robust speech detection method for telephone speech recognition system. Speech Communication, 27, 135–148.
Lass, N. J., & Brown, W. S. (1978). Correlation study of speaker’s heights, weights, body surface areas, and speaking fundamental frequencies. Journal of Acoustical Society of America (JASA), 63(4), 700–703.
Lass, N. J., & Davis, M. (1976). An investigation of speaker height and weight identification. Journal of Acoustical Society of America (JASA), 60(3), 700–703.
Lass, N. J., Phillips, J. K., & Bruchey, C. A. (1980). The effect of filtered speech on speaker height and weight identification. Journal of Phonetics, 8, 91–100.
Lass, N. J., Scherbick, K. A., Davies, S. L., & Czarnecki, T. D. (1982). Effect of vocal disguise on estimations of speakers’ heights and weights. Perceptual and Motor Skills, 54, 643–649.
Makhoul, J. (1975). Linear prediction: a tutorial review. Proceedings of the IEEE, 63(5), 561–580.
Metze, F., Ajmera, J., Englert, R., Bub, U., Burkhardt, F., Stegmann, J., Müller, C., Huber, R., Andrassy, B., Bauer, J., & Littel, B. (2007). Comparison of four approaches to age and gender recognition for telephone applications. In Proc. of the 2007 IEEE international conference on acoustics, speech, and signal processing (ICASSP 2007) (Vol. 4, pp. 1089–1092).
Mporas, I., Ganchev, T., & Fakotakis, N. (2010). Speech segmentation using regression fusion of boundary predictions. Computer Speech and Language, 24(2), 273–288.
Necioglu, B. F., Clements, M. A., & Barnwell III, T. P. (2000). Unsupervised estimation of the human vocal tract length over sentence level utterances. In Proc. of the 2000 IEEE international conference on acoustics, speech, and signal processing (ICASSP 2000) (Vol. 3, pp. 1319–1322).
Pellom, B. L., & Hansen, J. H. L. (1997). Voice analysis in adverse conditions: the centennial Olympic park bombing 911 call. In Proc. of the 40th Midwest symposium on circuits and systems (MWSCAS 1997) (Vol. 2, pp. 873–876).
Pressman, J. J., & Keleman, G. (1970). Physiology of the Larynx (Rev. by J. A. Krichner). Rochester: American Academy of Ophthalmology and Otolaryngology.
Quilan, J. R. (1992). Learning with continuous classes. In Proc. of the 5th Australian joint conference on artificial intelligence (pp. 343–348). Singapore: World Scientific.
Rendall, D., Kollias, S., & Ney, C. (2005). Pitch (F0) and formant profiles of human vowels and vowel-like baboon grunts: the role of vocalizer body size and voice-acoustic allometry. Journal of Acoustical Society of America (JASA), 117(2), 1–12.
Richmond, K. (1999). Estimating velum height from acoustics during continuous speech. In Proc. of the 6th European conference on speech communication and technology (Eurospeech 1999) (Vol. 1, pp. 149–152).
Robnik-Sikonja, M., & Kononenko, I. (1997). An adaptation of Relief for attribute estimation in regression. In Proc. of the 14th international conference on machine learning (pp. 296–304).
Scholkopf, B., Smola, A., Williamson, R., & Bartlett, P. L. (2000). New support vector algorithms. Neural Computation, 12(5), 1207–1245.
Schuller, B., Steidl, S., & Batliner, A. (2009). The Interspeech 2009 emotion challenge. In Proc. of the 10th annual conference of the international speech communication association (Interspeech 2009) (pp. 312–315).
Smith, L. H., & Nelson, D. J. (2004). An estimate of physical scale from speech. In Proc. of the 2004 IEEE international conference on acoustics, speech, and signal processing (ICASSP 2004) (Vol. 1, pp. 561–564).
van Dommelen, W. A. (1993). Speaker height and weight identification: re-evaluation of some old data. Journal of Phonetics, 21, 337–341.
van Dommelen, W. A., & Moxness, B. H. (1995). Acoustic parameters in speaker height and weight identification: sex-specific behaviour. Language and Speech, 38, 267–287.
van Oostendorp, M. (1998). Schwa in phonological theory. GLOT International, 3, 3–8.
Vapnik, V. (1998). Statistical learning theory. New York: Wiley.
Vislocky, R. L., & Fritsch, J. M. (1995). Generalized additive models versus linear regression in generating probabilistic MOS forecasts of aviation weather parameters. Weather and Forecasting, 10(4), 669–680.
Wang, Y., & Witten, I. H. (1997). Inducing model trees for continuous classes. In Proc. of the 9th European conference on machine learning (pp. 128–137).
Witten, H. I., & Frank, E. (2005). Data mining: practical machine learning tools and techniques. San Mateo: Morgan Kaufmann.
Yamagishia, J., Kawaia, H., & Kobayashib, T. (2008). Phone duration modeling using gradient tree boosting. Speech Communication, 50(5), 405–415.
Young, S., Evermann, G., Gales, M., Hain, T., Kershaw, D., Liu, X., Moore, G., Odell, J., Ollason, D., Povey, D., Valtchev, V., & Woodland, P. (2006). The HTK book (for HTK version 3.4). Cambridge: Cambridge University Engineering Department.
Zeng, Y., Wu, Z., Falk, T. H., & Chan, W.-Y. (2006). Robust GMM-based gender classification using pitch and RASTA-PLP parameters of speech. In Proc of intl. conf. on machine learning and cybernetics 2006.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Mporas, I., Ganchev, T. Estimation of unknown speaker’s height from speech. Int J Speech Technol 12, 149–160 (2009). https://doi.org/10.1007/s10772-010-9064-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-010-9064-2