
Abstract
I examine the relationship between economic position relative to local neighbors and life satisfaction in rural Bangladesh. In particular, I exploit a novel household level census of three villages that includes the geospatial coordinates of every household and a perception measure of economic position relative to neighbors. This allows for exploring the sensitivity of the aforementioned relationship to (1) different objective definitions of neighborhood, and (2) the type of positional measure used, objective or perceived. I find that a higher perceived position improves life satisfaction while objective position has no statistically significant effect. This difference stems from a very low correlation between the objective and perceived positional measures. The low correlation can be explained by individual specific heterogeneity in definitions of neighbor. However, observable socioeconomic and demographic variables cannot explain the difference.






Similar content being viewed by others

Notes
However, there is little empirical evidence for such a causal relationship (Rosenzweig 1988).
Indeed, psychologists and behavioral scientists have documented numerous instances where individuals’ reported perceptions deviate systematically from objective realities (Kahneman 2011).
It is possible that some of the households got mislabeled into the wrong village which may explain the lower number of households in S and higher number of households in B.
Principal component analysis indicates that there is only one underlying factor with an eigenvalue greater than 1 explaining about 37% of the total variance of these eight factors. All eight components are positively correlated with the composite index with household type, number of rooms, ownership of television and ownership of fridge being the most important components.
The HES of household i (\(HES_i\)) is generated using the formula \(HES_i =\frac{CI_i - {\text {min}}(CI)}{{\text {max}}(CI) - {\text {min}}(CI)}\) where \(CI_i\) is the composite index (CI) of household i and \({\text {max}}(CI)\) and \({\text {min}}(CI)\) are the maximum and minimum values of CI in the data, respectively. Roughly eight percent of the households (112 households) have \(HES_i=0\) which is set to 2.
Figure 1b illustrates such a case where household B and household C have 5 and 2 neighbors, respectively, for the same DB.
Calculation of economic position has some limitations related to missing information from neighbors due to non-response and the location of neighboring households outside the three villages surveyed. Given the refusal rate of participation in the TS is less than one percent, the first issue is at most marginal. The second issue is more problematic since the three villages surveyed share a border with other non-surveyed villages.
Mean comparison tests of HES between the 1301 respondents who answered the perceived position question versus the 94 who did not, does not raise reason for concern. In particular, the null hypothesis that the difference in mean HES between the two groups is zero cannot be rejected at the 95% confidence interval.
I included household size and employment status in my preliminary analysis but eventually dropped them because they are not significant and do not change the main results.
Religiosity is measured as a response to the question, “How religious are you?” on the 3-point scale of 1-not, 2-moderately, 3-very while health condition is based on responses to the question, “How satisfied are you with your current health” on the scale 1-not at all, 2, 3, 4, 5-completely satisfied.
Boes and Winkelmann (2004) underscore the importance of using generalized choice models instead of standard Ologits in estimating life satisfaction regressions. Indeed they find the relationship between life satisfaction and absolute income varies considerably when a GOlogit is used instead of an Ologit.
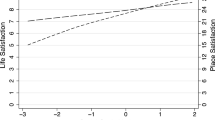
For OLS and Ologit the least life satisfaction age are 40.6 and 39.6 years respectively. For GOlogitF, this age varies between 35.8 and 42.2 years based on reported life satisfaction category.
Although it is possible that education affects life satisfaction indirectly by improving economic well-being, health status, and etc.
Results from the baseline regressions run on the constrained sample have not been included here but will be made available for those interested.
All the signs and approximate magnitude of the odds ratio also remain the same.
Interestingly, the proportionality odds constraint is violated for the perceived position variable
With the exception of age and squared-age, the variance inflation factor for all regressors, including logarithm of HES, in the perception regressions is less than 2 suggesting multi-collinearity is not responsible for this insignificance.
Note that a smaller number of clusters imply a bigger reference group.
Marital status and gender seems to affect perceived position in some categories of the GOlogitPs. Measures of fit do not improve much either when compared to the regression of perceived position on objective position only.
I do not present the more than 9000 regression results (one for each objective measure) here but can provide the result for those interested.
I choose this broad measure out of the six possible considered in this paper, since it offers the highest correlation between objective and perceived measures.
I also constructed the HES index by adding households’ reported income as an additional factor. The two HES measures shared a correlation of 0.95; however, there is a significant drop in observations when household income is used as a factor.
This method is called the “average link” method and involves taking an arithmetic mean of all distances between each pair of households situated in the two clusters.
For a detailed explanation and a discussion of the pros and cons of hierarchical clustering see Chapter 8 of Tan et al. (2006).
Note that the average HES of neighbors or the reference economic state used here is the same for everyone when \(J=1\).
The \((M-1)\) associated odds ratios indicate how the odds of falling into higher y categories compared to lower categories go up when \(\theta\) goes up by a unit. For instance, if the third odds ratio related to \(\theta\) is 2, it implies that when \(\theta\) increases by one, the odds of \(y>3\) compared to \(y\le 3\) doubles.
References
Bhuiyan, M. F. (2013). Relative consumption: A model of peers, status, and labor supply. American Journal of Agricultural Economics, 95(2), 368–375.
Bhuiyan, M. F., & Lackie, P. (2016). Mitigating survey fraud and human error: Lessons learned from a low budget census in Bangladesh. IASSIST Quarterly, 40(3), 20–26.
Bhuiyan, M. F., & Szulga, R. (2013). The Tangail Survey: Household level census of subjective well-being, perceptions of relative economic position, and international migration: 2013 [Tangail, Bangladesh]. doi:10.3886/E61146V1.
Bhuiyan, M. F., & Szulga, R. S. (2017). Extreme bounds of subjective well-being: Economic development and micro determinants of life satisfaction. Applied Economics, 49(14), 1351–1378.
Bjornskov, C., Dreher, A., & Fischer, J. A. V. (2008). Cross-country determinants of life satisfaction: Exploring different determinants across groups in society. Social Choice and Welfare, 30(1), 119–173.
Blanchflower, D. G., & Oswald, A. J. (2004). Well-being over time in Britain and the USA. Journal of Public Economics, 88(7–8), 1359–1386.
Boes, S., & Winkelmann, R. (2004). Income and happiness: New results from generalized threshold and sequential models. IZA Discussion paper.
Brant, R. (1990). Assessing proportionality in the proportional odds model for ordinal logistic-regression. Biometrics, 46(4), 1171–1178.
Bruni, L., & Stanca, L. (2008). Watching alone: Relational goods, television and happiness. Journal of Economic Behavior and Organization, 65(3–4), 506–528.
Charness, G., & Grosskopf, B. (2001). Relative payoffs and happiness: An experimental study. Journal of Economic Behavior and Organization, 45(3), 301–328.
Clark, A. E., & Oswald, A. J. (1996). Satisfaction and comparison income. Journal of Public Economics, 61(3), 359–381.
Clark, A. E., Westergard-Nielsen, N., & Kristensen, N. (2009). Economic satisfaction and income rank in small neighbourhoods. Journal of the European Economic Association, 7(2/3), 519–527.
Cruces, G., Perez-Truglia, R., & Tetaz, M. (2013). Biased perceptions of income distribution and preferences for redistribution: Evidence from a survey experiment. Journal of Public Economics, 98, 100–112.
Dittmann, J., & Goebel, J. (2010). Your house, your car, your education: The socioeconomic situation of the neighborhood and its impact on life satisfaction in Germany. Social Indicators Research, 96(3), 497–513.
Dowling, J. M., & Yap, C. F. (2012). Happiness and Poverty in Developing Countries: A Global Perspective. New York, NY: Palgrave Macmillan.
Duesenberry, J. S. (1949). Income, saving, and the theory of consumer behavior. Cambridge, MA: Harvard University Press.
Dynan, K. E., & Ravina, E. (2007). Increasing income inequality, external habits, and self-reported happiness. American Economic Review, 97(2), 226–231.
Easterlin, R. A. (1995). Will raising the incomes of all increase the happiness of all. Journal of Economic Behavior and Organization, 27(1), 35–47.
Easterlin, R. A. (2001). Income and happiness: Towards an unified theory. Economic Journal, 111(473), 465–484.
Fafchamps, M., & Shilpi, F. (2008). Subjective welfare, isolation, and relative consumption. Journal of Development Economics, 86(1), 43–60.
Fernandez, R. M., & Kulik, J. C. (1981). A multilevel model of life satisfaction: Effects of individual characteristics and neighborhood composition. American Sociological Review, 46, 840–850.
Ferrer-i-Carbonell, A. (2005). Income and well-being: An empirical analysis of the comparison income effect. Journal of Public Economics, 89(5–6), 997–1019.
Firebaugh, G., & Schroeder, M. B. (2009). Does your neighbor’s income affect your happiness? American journal of sociology, 115(3), 805–831.
Frank, R. H. (1985a). The demand for unobservable and other nonpositional goods. American Economic Review, 75(1), 101–116.
Frank, R. H. (1985b). On choosing the right pond: Human behavior and the quest for status. New York: Oxford University Press.
Galster, G. (2008). Quantifying the effect of neighbourhood on individuals: Challenges, alternative approaches, and promising directions. Schmollers Jahrbuch, 128(1), 7–48.
Kahneman, D. (2011). Thinking, fast and slow (1st ed.). New York: Farrar, Straus and Giroux.
Kahneman, D., & Krueger, A. B. (2006). Developments in the measurement of subjective well-being. The Journal of Economic Perspectives, 20(1), 3–24.
Karadja, M., Mollerstrom, J., & Seim, D. (2015). Richer (and holier) than thou? the effect of relative income improvements on demand for redistribution. The Effect of Relative Income Improvements on Demand for Redistribution (February 14, 2015). George Mason Law & Economics Research Paper 15-10 .
Kingdon, G. G., & Knight, J. (2007). Community, comparisons and subjective well-being in a divided society. Journal of Economic Behavior and Organization, 64(1), 69–90.
Knabe, A., Ratzel, S., Schob, R., & Weimann, J. (2010). Dissatisfied with life but having a good day: Time-use and well-being of the unemployed. Economic Journal, 120(547), 867–889.
Knies, G., Burgess, S., & Propper, C. (2008). Keeping up with the schmidt’s: An empirical test of relative deprivation theory in the neighbourhood context. Schmollers Jahrbuch, 128(1), 75–108.
Larsen, R. J., Diener, E., & Emmons, R. A. (1985). An evaluation of subjective well-being measures. Social Indicators Research, 17(1), 1–17.
Lepper, H. (1998). Use of other-reports to validate subjective well-being measures. Social Indicators Research, 44(3), 367–379.
Ligon, E., Thomas, J. P., & Worrall, T. (2002). Informal insurance arrangements with limited commitment: Theory and evidence from village economies. Review of Economic Studies, 69(1), 209–244.
Luttmer, E. F. P. (2005). Neighbors as negatives: Relative earnings and well-being. Quarterly Journal of Economics, 120(3), 963–1002.
Macunovich, D. J. (1996). Relative income and price of time: Exploring their effects on us fertility and female labor force participation. Population and Development Review, 22, 223–257.
Mayraz, G., Schupp, J., & Wagner, G. G. (2009). Life satisfaction and relative income: Perceptions and evidence. CEP Discussion Papers, Centre for Economic Performance, LSE.
Neumark, D., & Postlewaite, A. (1998). Relative income concerns and the rise in married women’s employment. Journal of Public Economics, 70(1), 157–183.
Ng, Y. (1997). A case for happiness, cardinalism, and interpersonal comparability. Economic Journal, 107(445), 1848–1858.
Norton, M. I., & Ariely, D. (2011). Building a better America: One wealth quintile at a time. Perspectives on Psychological Science, 6(1), 9–12.
Persky, J., & Tam, M. Y. (1990). Local status and national social-welfare. Journal of Regional Science, 30(2), 229–238.
Pigou, A. C. (1903). Some remarks on utility. The Economic Journal, 13(49), 58–68.
Rayo, L., & Becker, G. S. (2007). Evolutionary efficiency and happiness. Journal of Political Economy, 115(2), 302–337.
Rosenzweig, M. R. (1988). Risk, implicit contracts and the family in rural-areas of low-income countries. Economic Journal, 98(393), 1148–1170.
Sandvik, E., Diener, E., & Seidlitz, L. (2009). Subjective well-being: The convergence and stability of self-report and non-self-report measures (Vol. 39). Dordrecht: Springer.
Smith, A. (1776). An inquiry into the nature and causes of the wealth of nations. Dublin: Whitestone.
Stutzer, A. (2004). The role of income aspirations in individual happiness. Journal of Economic Behavior and Organization, 54(1), 89–109.
Tan, P. N., Steinbach, M., & Kumar, V. (2006). Introduction to data mining (1st ed.). Boston: Pearson Addison Wesley.
Veblen, T. (1899). The theory of the leisure class. New York: Modern Library.
Verme, P. (2009). Happiness, freedom and control. Journal of Economic Behavior and Organization, 71(2), 146–161.
Williams, R. (2007). gologit2 documentation. Department of Sociology, University of Notre Dame. http://www.stata.com/meeting/4nasug/gologit2.pd. Retrieved 2 Jan 2015.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Brief Explanation of Hierarchical Clustering with an Average Link
I choose the hierarchical clustering procedure since it is a popular method of clustering with a long history in the literature. It also provides some objectivity by not requiring me to make any subjective choice of initial seeding that some other clustering techniques necessitate (e.g. K-means). Assuming there are N distinct households, the hierarchical clustering technique involves N iterative steps with each step producing a unique way of dividing all the households into separate clusters. The first step defines each of the N household as a cluster. The second step calculates the distance between every pair of households (or clusters) and then identifies the two households with the shortest distance between them as a single cluster while the rest of the households continue being treated as their own cluster (leading to \((N-1)\)-cluster neighbors). In the third step, the “average” distance between every cluster is calculated and the two clusters with the shortest average distance between them merged into one cluster.Footnote 24 This process is repeated until all households form a single cluster in the Nth step. Thus, the J-cluster neighbors refer to neighbors defined in the \((N-J+1)\)th step and comprising of J clusters.Footnote 25
There are 1395 possible J-cluster neighbors (where \(J = 1,2,\ldots ,1395\)) associated with the hierarchical iterative process explained before in the data used for this paper. However, for higher values of J these are not very useful because there are too many single household clusters. Hence, I do not consider J-clusters where \(J > 200\). Under the 200-cluster neighbors, there are 27 households that form singleton clusters while 43% of the households are located in clusters with less than 10 households. I also do not use 1-cluster because this makes HES and the ratio of HES to average neighbors’ HES perfectly collinear.Footnote 26
Appendix 2: Generalized Ordered Logits
Equation (3) summarizes the GOlogit associated with Eq. (1):
Note that the model parameters \(\rho _0,\rho _1,\ldots ,\rho _K\) from Eq. (1) have an additional subscript of j in Eq. (3). This embodies the generalization that the parameters may vary across reported \(y_i\) i.e. the “proportional-odds” assumption that is standard in ordered logits (Ologits) is relaxed. Indeed, relaxing the proportional-odds constraints (POCs) is equivalent to assuming the threshold cut-offs in ordered logits are heterogeneous and are weighted linear combinations of the independent variables. If the POCs are imposed for all variables, it becomes the standard Ologit. The interpretation of the regression coefficients and related odds ratio of GOlogits can be a bit tricky. Without loss of generality, for each regressor \(\theta\), the GOlogit estimates \((M-1)\) different regression coefficients.Footnote 27
Generally, if the dataset has a large number of observations using a GOlogit without imposing any POCs (GOlogitF) is preferred to implementing the more parametrically parsimonious Ologit. Given the TS has a limited number of observations, running a GOlogitF entails estimation of additional parameters that may reduce efficiency unnecessarily if the true data generating process (DGP) imposes all of the POCs. However, if the true DGP is one where some of the POCs do not hold, then Ologits produce biased estimates.
A GOlogit which relaxes only those POCs that are violated (GOlogitP) is a practical compromise between an Ologit and a GOlogitF. Brant (1990) proposes using Wald tests to identify which POCs do not hold. I use the iterative autofit process developed by Williams (2007), an extension of the “Brant” test, to choose which POCs to relax when running the GOlogitPs. In particular, running the baseline regressions and the perception regressions with autofit reveal that only POCs associated with the village dummies and the perceived position variables are violated. Consequently, I relax the POCs for only the village dummies and the objective position measures when running the objective regressions.
Rights and permissions
About this article

Cite this article
Bhuiyan, M.F. Life Satisfaction and Economic Position Relative to Neighbors: Perceptions Versus Reality. J Happiness Stud 19, 1935–1964 (2018). https://doi.org/10.1007/s10902-017-9904-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10902-017-9904-8