
Abstract
Many academic surveys administered online include a banner along the top of the survey displaying the name or logo of the researcher’s university. These banners may unintentionally influence respondents’ answers since subtle contextual cues often have great impact on survey responses. Our study aims to determine whether these banners influence survey respondents’ answers, that is, whether they induce sponsorship effects. For this purpose, we field three different studies on Amazon’s MTurk where we randomly assign the sponsoring institution. Our outcome measures include survey questions about social conservatism, religious practices, group affect, and political knowledge. We find that respondents provide similar answers and exhibit similar levels of effort regardless of the apparent sponsor.
Similar content being viewed by others

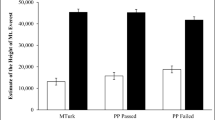
Data Availability
Data and replication code are available at https://doi.org/10.7910/DVN/ZWAGXZ.
Notes
We contacted Qualtrics to determine how frequently universities placed their name or logo in their default survey header. Andrew Camp, a Qualtrics Product Specialist, responded through email on 2018-03-14. He confirmed that universities typically work with Qualtrics to create custom, branded survey formats, or themes, but licensing terms prevented him from disclosing descriptive statistics. He did attest that “universities do tend to prefer to set these custom themes as a default to encourage their users to use said theme.” We also searched the EGAP registry for pre-analysis plans that included the terms ‘qualtrics’ (\(n = 53\)), MTurk’ (\(n = 31\)), or ‘mechanical turk’ (\(n = 66\)). Of the 126 un-gated plans, there were 4 that showed screenshots of the actual survey instrument, 2 of which (\(50\%\)) included a university logo.
Researchers have noted a recent wave of low-quality, bot-like responses in surveys administered to MTurk workers. Most of these problematic responses come from duplicated GPS coordinates, which we drop before analysis. Using alternative indicators, we find only negligible evidence of bot-like behavior. For details, see Note 1 on page 25 of the online supplemental information (SI).
In many cases, researchers display multiple questions per page. By only displaying a single question on each page we maximize the chance that participants notice the banner while responding. This stronger-than-usual treatment implies that our inferences about the absence of sponsorship effects are likely to be conservative, making it less likely that sponsorship effects exist “in the wild.”
Pre-registration documents can be accessed at https://osf.io/pfqtb/ (Study 1, fielded October 28–29, 2017), https://osf.io/9sw2k (Study 2, fielded December 18, 2017–January 2, 2018), and https://osf.io/hpbqw (Study 3, fielded March 5–April 11, 2018).
Online Figure A1 in the SI displays the consent form and debrief text used for all three studies.
See Online Tables A2–A5 for the question wording and response options.
We followed this procedure to prevent the same individual from participating in our survey several times using different MTurk IDs. This approach is more conservative than simply dropping repeated IP addresses since respondents might access the survey using several devices.
Ohio State and Notre Dame differ on other dimensions in addition to religious affiliation. More generally, any two universities will differ along many dimensions so additional work would be required to identify which dimensions drive differences in response patterns. Note, however, that this question is separate from the question we consider here, which is whether the bundle of traits represented by specific university logos affects survey responses.
An exact randomization inference balance test (approximated using one million randomizations) of the null hypothesis that the mean vote share of Donald Trump in the 2016 Presidential elections is the same across all three treatment groups yields a p-value of 0.18. For each subject, we looked up county-level vote shares based on the respondent’s IP address. In the interest of full disclosure we note that balance tests were not pre-registered.
As in Young (2019), we stack the squared test statistics for each comparison and compute the test statistic \({\varvec{\beta }}^{\text {T}} {\varvec{\Omega }} {\varvec{\beta }}\), where \({\varvec{\beta }}\) is the vector of stacked squared test statistics and \({\varvec{\Omega }}\) is the inverse of the covariance matrix of the stacked test statistics based on 1 million randomly chosen treatment assignments.
A balance test analogous to the one for Study 1 yields a p-value of 0.70.
An anonymous reviewer suggested to also examine treatment effect heterogeneity for the feeling thermometer scales for Muslims, people on welfare, atheists, and feminists using affective ideological polarization (Mason 2018), the difference in liberal and conservative thermometer scales. This analysis is only valid under the assumption that the difference in liberal and conservative thermometer scales is not affected by the treatments. We have included this exploratory analysis in Table A7 in the SI. We find no evidence of treatment effect heterogeneity.
A balance test analogous to the ones for the other two studies yields a p-value of 0.86.
The Chief Justice, Theresa May, federal spending, and senate term length questions are variants of items from the 2012 ANES political knowledge battery, chosen because they were some of the most difficult items and because they could be readily extended to four response options plus “Don’t know.” The questions about the Secretary of State and Attorney General were taken from Ahler and Goggin (2017). On March 13, 2018, Donald Trump fired Secretary of State Rex Tillerson, making the question about the current Secretary of State meaningless. After the news broke, we deleted all 94 responses received after March 12, 2018 and replaced this item with a new question which asks which individual is currently a senator from Florida. Exact question wordings and response options are displayed in Online Tables A8–A14.
“In a paragraph, please tell us what being a good citizen means to you.”
Krupnikov and Levine (2014) suggest that MTurk samples sometimes yield results that differ from national samples in other important ways. The authors, however, issued a correction to their original findings (Krupnikov and Levine 2019), noting that many of the cross-sample differences they found lack statistical significance.
Our findings leave open the possibility that respondents are simply unfamiliar with universities such as Harvard, UC Berkeley, or Notre Dame and unaware of their reputations as elite, or liberal, or Catholic institutions. However, if these well-known universities indeed lack the cultural resonance required to produce sponsorship effects, it is hard to imagine that other universities would be more culturally resonant among U.S.-based survey respondents. Finally, even if respondents indeed lack knowledge of university reputations, our results would still suggest that including university logos does not bias survey responses.
References
Ahler, D. J., Goggin, S. N. (2017). Assessing political knowledge: Problems and solutions in online surveys. SSRN Working paper.
Andersen, D. J., & Lau, R. R. (2018). Pay rates and subject performance in social science experiments using crowdsourced online samples. Journal of Experimental Political Science, 5(3), 217–229.
Bartneck, C., Duenser, A., Moltchanova, E., & Zawieska, K. (2015). Comparing the similarity of responses received from studies in amazons mechanical turk to studies conducted online and with direct recruitment. PLoS ONE, 10(4), e0121595.
Behrend, T. S., Sharek, D. J., Meade, A. W., & Wiebe, E. N. (2011). The viability of crowdsourcing for survey research. Behavior Research Methods, 43(3), 800.
Berinsky, A. J., & Lavine, H. (2012). Self-monitoring and political attitudes. In J. Aldrich & M. Kathleen (Eds.), Improving public opinion surveys: Interdisciplinary innovation and the American National Election Studies. Princeton: Princeton University Press.
Bischoping, K., & Schuman, H. (1992). Pens and polls in Nicaragua: An analysis of the 1990 preelection surveys. American Journal of Political Science, 36(2), 331–350.
Burdein, I., Lodge, M., & Taber, C. (2006). Experiments on the automaticity of political beliefs and attitudes. Political Psychology, 27(3), 359–371.
Chandler, J., Rosenzweig, C., Moss, A. J., Robinson, J., & Litman, L. (2019). Online panels in social science research: Expanding sampling methods beyond Mechanical Turk. Behavior Research Methods, 51(5), 2022–2038.
Clifford, S., Jewell, R. M., & Waggoner, P. D. (2015). Are samples drawn from mechanical Turk valid for research on political ideology? Research & Politics, 2(4), 1–9.
Clifford, S., & Piston, S. (2017). Explaining public support for counterproductive homelessness policy: The role of disgust. Political Behavior, 39(2), 503–525.
Clifford, S., & Wendell, D. G. (2016). How disgust influences health purity attitudes. Political Behavior, 38(1), 155–178.
Connors, E. C., Krupnikov, Y., & Ryan, J. B. (2019). How transparency affects survey responses. Public Opinion Quarterly, 83(S1), 185–209.
Coppock, A. (2019). Generalizing from survey experiments conducted on mechanical turk: A replication approach. Political Science Research and Methods, 7(3), 613–628.
Cotter, P. R., Cohen, J., & Coulter, P. B. (1982). Race-of-interviewer effects in telephone interviews. Public Opinion Quarterly, 46(2), 278–284.
Druckman, J. N., & Leeper, T. J. (2012). Learning more from political communication experiments: Pretreatment and its effects. American Journal of Political Science, 56(4), 875–896.
Edwards, M. L., Dillman, D. A., & Smyth, J. D. (2014). An experimental test of the effects of survey sponsorship on internet and mail survey response. Public Opinion Quarterly, 78(3), 734–750.
Fisher, R. A. (1935). The design of experiments. Edinburg: Oliver and Boyd.
Franco, A., Malhotra, N., & Simonovits, G. (2015). Underreporting in political science survey experiments: Comparing questionnaires to published results. Political Analysis, 23(2), 306–312.
Franco, A., Malhotra, N., Simonovits, G., & Zigerell, L. J. (2017). Developing standards for post-hoc weighting in population-based survey experiments. Journal of Experimental Political Science, 4(2), 161–172.
Freedman, D. A. (2008a). On regression adjustments in experiments with several treatments. Annals of Applied Statistics, 2(1), 176–196.
Freedman, D. A. (2008b). On regression adjustments to experimental data. Advances in Applied Mathematics, 40(2), 180–193.
Galesic, M., Tourangeau, R., Couper, M. P., & Conrad, F. G. (2008). Eye-tracking data: New insights on response order effects and other cognitive shortcuts in survey responding. Public Opinion Quarterly, 72(5), 892–913.
Gerber, A., Arceneaux, K., Boudreau, C., Dowling, C., Hillygus, S., Palfrey, T., et al. (2014). Reporting guidelines for experimental research: A report from the experimental research section standards committee. Journal of Experimental Political Science, 1(1), 81–98.
Hauser, D. J., & Schwarz, N. (2016). Attentive turkers: MTurk participants perform better on online attention checks than do subject pool participants. Behavior Research Methods, 48(1), 400–407.
Holbrook, A. L., Green, M. C., & Krosnick, J. A. (2003). Telephone versus face-to-face interviewing of national probability samples with long questionnaires: Comparisons of respondent satisficing and social desirability response bias. Public Opinion Quarterly, 67(1), 79–125.
Huddy, L., Billig, J., Bracciodieta, J., Hoeffler, L., Moynihan, P. J., & Pugliani, P. (1997). The effect of interviewer gender on the survey response. Political Behavior, 19(3), 197–220.
Imbens, G. W., & Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences. Cambridge: Cambridge University Press.
Jessee, S. A. (2017). “Don’t know” responses, personality, and the measurement of political knowledge. Political Science Research and Methods, 5(4), 711–731.
Kinder, D. R., & Sanders, L. M. (1990). Mimicking political debate with survey questions: The case of white opinion on affirmative action for blacks. Social Cognition, 8(1), 73–103.
Krosnick, J. A., & Presser, S. (2010). Question and questionnaire design. In P. V. Marsden & J. D. Wright (Eds.), Handbook of survey research. Bingley: Emerald Group Publishing.
Krupnikov, Y., & Bauer, N. M. (2014). The relationship between campaign negativity, gender and campaign context. Political Behavior, 36(1), 167–188.
Krupnikov, Y., & Levine, A. S. (2014). Cross-sample comparisons and external validity. Journal of Experimental Political Science, 1(1), 59–80.
Krupnikov, Y., & Levine, A. S. (2019). Cross-sample comparisons and external validity: Corrigendum. Journal of Experimental Political Science. https://doi.org/10.1017/XPS.2019.7.
Leeper, T. J., & Thorson, E. A. (2019). Should we worry about sponsorship-induced bias in online political science surveys? Journal of Experimental Political Science. https://doi.org/10.7910/DVN/KKFS8Y.
Mason, L. (2018). Ideologues without issues: The polarizing consequences of ideological identities. Public Opinion Quarterly, 82(S1), 866–887.
Mason, W. & Watts, D. J. (2009). Financial incentives and the “performance of crowds”. In Proceedings of the ACM SIGKDD Workshop on Human Computation. HCOMP ’09 Paris, France: Association for Computing Machinery pp 77–85.
Mullinix, K. J., Leeper, T. J., Druckman, J. N., & Freese, J. (2015). The generalizability of survey experiments. Journal of Experimental Political Science, 2(2), 109–138.
Mummolo, J., & Peterson, E. (2019). Demand effects in survey experiments: An empirical assessment. American Political Science Review, 113(2), 517–529.
Roethlisberger, F. J., & Dickson, W. J. (1939). Management and the Worker. Cambridge: Harvard University Press.
Sigelman, L. (1981). Question-order effects on presidential popularity. Public Opinion Quarterly, 45(2), 199–207.
Tourangeau, R., Groves, R. M., Kennedy, C., & Yan, T. (2009). The presentation of a web survey, nonresponse and measurement error among members of web panel. Journal of Official Statistics, 25(3), 299–321.
Tourangeau, R., Presser, S., & Sun, H. (2014). The impact of partisan sponsorship on political surveys. Public Opinion Quarterly, 78(2), 510–522.
West, B. T., & Blom, A. G. (2017). Explaining interviewer effects: A research synthesis. Journal of Survey Statistics and Methodology, 5(2), 175–211.
White, A., Strezhnev, A., Lucas, C., Kruszewska, D., & Huff, C. (2018). Investigator characteristics and respondent behavior in online surveys. Journal of Experimental Political Science, 5(1), 56–67.
Young, A. (2019). Channeling fisher: Randomization tests and the statistical insignificance of seemingly significant experimental results. The Quarterly Journal of Economics, 134(2), 557–598.
Acknowledgements
We thank Hans Hassell, Lauren Ratliff Santoro, and audiences at Florida State University and the 2018 Midwest Political Science Association meeting for useful feedback. All errors remain our own. The research reported here was approved by FSU’s Human Subjects Committee (HSC 2017.22511 and 2018.25529)
Funding
None.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
None.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Crabtree, C., Kern, H.L. & Pietryka, M.T. Sponsorship Effects in Online Surveys. Polit Behav 44, 257–270 (2022). https://doi.org/10.1007/s11109-020-09620-7
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11109-020-09620-7