
Abstract
We propose Human Pose Models that represent RGB and depth images of human poses independent of clothing textures, backgrounds, lighting conditions, body shapes and camera viewpoints. Learning such universal models requires training images where all factors are varied for every human pose. Capturing such data is prohibitively expensive. Therefore, we develop a framework for synthesizing the training data. First, we learn representative human poses from a large corpus of real motion captured human skeleton data. Next, we fit synthetic 3D humans with different body shapes to each pose and render each from 180 camera viewpoints while randomly varying the clothing textures, background and lighting. Generative Adversarial Networks are employed to minimize the gap between synthetic and real image distributions. CNN models are then learned that transfer human poses to a shared high-level invariant space. The learned CNN models are then used as invariant feature extractors from real RGB and depth frames of human action videos and the temporal variations are modelled by Fourier Temporal Pyramid. Finally, linear SVM is used for classification. Experiments on three benchmark human action datasets show that our algorithm outperforms existing methods by significant margins for RGB only and RGB-D action recognition.













Similar content being viewed by others

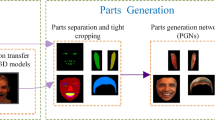

Notes
The code for this method will be made public.
The data synthesis script will be made public.
References
Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. In IEEE conference on computer vision and pattern recognition (Vol. 1, pp. 886–893).
Dalal, N., Triggs, B., & Schmid, C. (2006). Human detection using oriented histograms of flow and appearance. In European conference on computer vision (pp. 428–441).
Donahue, J., Anne Hendricks, L., Guadarrama, S., Rohrbach, M., Venugopalan, S., Saenko, K., et al. (2015). Long-term recurrent convolutional networks for visual recognition and description. In IEEE conference on computer vision and pattern recognition (pp. 2625–2634).
Du, Y., Wang, W., & Wang, L. (2015). Hierarchical recurrent neural network for skeletonbased action recognition. In IEEE conference on computer vision andpattern recognition (pp. 1110–1118).
Evangelidis, G., Singh, G., & Horaud, R. (2014). Skeletal quads: Human action recognition using joint quadruples. In International conference on pattern recognition (pp. 4513–4518).
Fan, R. E., Chang, K. W., Hsieh, C. J., Wang, X. R., & Lin, C. J. (2008). LIBLINEAR: A library for large linear classification. Journal of Machine Learning Research, 9, 1871–1874.
Farhadi, A., & Tabrizi, M. K. (2008). Learning to recognize activities from the wrong view point. In European conference on computer vision (pp. 154–166).
Farhadi, A., Tabrizi, M. K., Endres, I., & Forsyth, D. (2009). A latent model of discriminative aspect. In IEEE international conference on computer vision (pp. 948–955).
Feichtenhofer, C., Pinz, A., & Zisserman, A. (2016). Convolutional two-stream network fusion for video action recognition. In IEEE conference on computer vision and pattern recognition (pp. 1933–1941).
Gkioxari, G., & Malik, J. (2015). Finding action tubes. In IEEE conference on computer vision and pattern recognition (pp. 759–768).
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672–2680).
Gopalan, R., Li, R., & Chellappa, R. (2011). Domain adaptation for object recognition: An unsupervised approach. In IEEE international conference on computer vision (pp. 999–1006).
Gupta, A., Martinez, J., Little, J. J., & Woodham, R. J. (2014). 3D pose from motion for cross-view action recognition via non-linear circulant temporal encoding. In IEEE conference on computer vision and pattern recognition (pp. 2601–2608).
He, K., Zhang, X., Ren, S., & Sun, J. (2016a). Deep residual learning for image recognition. In IEEE conference on computer vision and pattern recognition (pp. 770–778).
He, Y., Shirakabe, S., Satoh, Y., & Kataoka, H. (2016b). Human action recognition without human. In European conference on computer vision workshops (pp. 11–17).
Hu, J. F., Zheng, W. S., Lai, J., & Zhang, J. (2015). Jointly learning heterogeneous features for RGB-D activity recognition. In IEEE conference on computer vision and pattern recognition (pp. 5344–5352).
Huang, Z., Wan, C., Probst, T., & Van Gool, L. (2016). Deep learning on lie groups for skeleton-based action recognition. In IEEE conference on computer vision and pattern recognition.
Ji, S., Xu, W., Yang, M., & Yu, K. (2013). 3D convolutional neural networks for human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1), 221–231.
Jia, C., Kong, Y., Ding, Z., Fu, Y. R. (2014a). Latent tensor transfer learning for RGB-D action recognition. In ACM international conference on multimedia (pp. 87–96).
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., & Darrell, T. (2014b). Caffe: Convolutional architecture for fast feature embedding. arXiv:1408.5093.
Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., Fei-Fei, L. (2014). Large-scale video classification with convolutional neural networks. In IEEE conference on computer vision and pattern recognition (pp. 1725–1732).
Kerola, T., Inoue, N., & Shinoda, K. (2017). Cross-view human action recognition from depth maps using spectral graph sequences. Computer Vision and Image Understanding, 154, 108–126.
Kong, Y., & Fu, Y. (2017). Max-margin heterogeneous information machine for RGB-D action recognition. International Journal of Computer Vision, 123(3), 350–371.
Krizhevsky, A., Sutskever, I., Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097–1105).
Li, B., Camps, O. I., & Sznaier, M. (2012) Cross-view activity recognition using hankelets. In IEEE conference on computer vision and pattern recognition (pp. 1362–1369).
Li, R., & Zickler, T. (2012). Discriminative virtual views for cross-view action recognition. In IEEE conference on computer vision and pattern recognition (pp. 2855–2862).
Li, Y., Li, W., Mahadevan, V., & Vasconcelos, N. (2016). VLAD3: Encoding dynamics of deep features for action recognition. In IEEE conference on computer vision and pattern recognition (pp. 1951–1960).
Liu, J., Shah, M., Kuipers, B., & Savarese, S. (2011). Cross-view action recognition via view knowledge transfer. In IEEE conference on computer vision and pattern recognition (pp. 3209–3216).
Liu, J., Shahroudy, A., Xu, D., & Wang, G. (2016). Spatio-temporal LSTM with trust gates for 3D human action recognition. In European conference on computer vision (pp. 816–833).
Luo, Z., Peng, B., Huang, D. A., Alahi, A., & Fei-Fei, L. (2017). Unsupervised learning of long-term motion dynamics for videos. In IEEE conference on computer vision and pattern recognition.
Lv, F., & Nevatia, R. (2007). Single view human action recognition using key pose matching and viterbi path searching. In IEEE conference on computer vision and pattern recognition (pp. 1–8).
McInnes, L., Healy, J., & Astels, S. (2017). HDBSCAN: Hierarchical density based clustering. The Journal of Open Source Software, 2, 205.
Ohn-Bar, E., & Trivedi, M. (2013). Joint angles similarities and HOG2 for action recognition. In IEEE conference on computer vision and pattern recognition workshops (pp. 465–470).
Oreifej, O., & Liu, Z. (2013). HON4D: Histogram of oriented 4D normals for activity recognition from depth sequences. In IEEE conference on computer vision and pattern recognition (pp. 716–723).
Parameswaran, V., & Chellappa, R. (2006). View invariance for human action recognition. International Journal of Computer Vision, 1(66), 83–101.
Pfister, T., Charles, J., & Zisserman, A. (2015). Flowing convnets for human pose estimation in videos. In IEEE international conference on computer vision (pp. 1913–1921).
Rahmani, H., & Mian, A. (2015). Learning a non-linear knowledge transfer model for cross-view action recognition. In IEEE conference on computer vision and pattern recognition (pp. 2458–2466).
Rahmani, H., & Mian, A. (2016). 3d action recognition from novel viewpoints. In IEEE conference on computer vision and pattern recognition (pp. 1506–1515).
Rahmani, H., Mahmood, A., Huynh, D., & Mian, A. (2016). Histogram of oriented principal components for cross-view action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(12), 2430–2443.
Rahmani, H., Mian, A., & Shah, M. (2017). Learning a deep model for human action recognition from novel viewpoints. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40, 667–681.
Rao, C., Yilmaz, A., & Shah, M. (2002). View-invariant representation and recognition of actions. International Journal of Computer Vision, 50(2), 203–226.
Shahroudy, A., Liu, J., Ng, T. T., & Wang, G. (2016a). NTU RGB+D: A large scale dataset for 3d human activity analysis. In IEEE conference on computer vision and pattern recognition (pp. 1010–1019).
Shahroudy, A., Ng, T. T., Yang, Q., & Wang, G. (2016b). Multimodal multipart learning for action recognition in depth videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(10), 2123–2129.
Shahroudy, A., Ng, T. T., Gong, Y., & Wang, G. (2017). Deep multimodal feature analysis for action recognition in RGB+D videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40, 1045–1058.
Shakhnarovich, G. (2005). Learning task-specific similarity. Ph.D. thesis, Massachusetts Institute of Technology.
Shrivastava, A., Pfister, T., Tuzel, O., Susskind, J., Wang, W., Webb, R. (2016). Learning from simulated and unsupervised images through adversarial training. arXiv:1612.07828.
Simonyan, K., & Zisserman, A. (2014). Two-stream convolutional networks for action recognition in videos. In Advances in neural information processing systems (pp. 568–576).
Soomro, K., Zamir, A. R., & Shah, M. (2012). UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv:1212.0402.
Su, B., Zhou, J., Ding, X., Wang, H., & Wu, Y. (2016). Hierarchical dynamic parsing and encoding for action recognition. In European conference on computer vision (pp. 202–217).
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). Going deeper with convolutions. In IEEE conference on computer vision and pattern recognition (pp. 1–9).
Tran, D., Bourdev, L., Fergus, R., Torresani, L., & Paluri, M. (2015). Learning spatiotemporal features with 3D convolutional networks. In IEEE international conference on computer vision (pp. 4489–4497).
Varol, G., Laptev, I., & Schmid, C. (2017a). Long-term temporal convolutions for action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40, 1510–1517.
Varol, G., Romero, J., Martin, X., Mahmood, N., Black, M. J., Laptev, I., et al. (2017b). Learning from Synthetic Humans. In IEEE conference on computer vision and pattern recognition.
Vemulapalli, R., Arrate, F., & Chellappa, R. (2014). Human action recognition by representing 3D skeletons as points in a lie group. In IEEE conference on computer vision and pattern recognition (pp. 588–595).
Wang, H., & Schmid, C. (2013). Action recognition with improved trajectories. In IEEE international conference on computer vision (pp. 3551–3558).
Wang, H., Kläser, A., Schmid, C., & Liu, C. L. (2011). Action recognition by dense trajectories. In IEEE conference on computer vision and pattern recognition (pp. 3169–3176).
Wang, H., Kläser, A., Schmid, C., & Liu, C. L. (2013a). Dense trajectories and motion boundary descriptors for action recognition. International Journal of Computer Vision, 103(1), 60–79.
Wang, J., Liu, Z., Wu, Y., & Yuan, J. (2013b). Learning actionlet ensemble for 3D human action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36, 914–927.
Wang, J., Nie, X., Xia, Y., Wu, Y., & Zhu, S. C. (2014). Cross-view action modeling, learning and recognition. In IEEE conference on computer vision and pattern recognition (pp. 2649–2656).
Wang, L., Qiao, Y., & Tang, X. (2015). Action recognition with trajectory-pooled deep-convolutional descriptors. In IEEE conference on computer vision and pattern recognition (pp. 4305–4314).
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., et al. (2016a). Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision (pp. 20–36).
Wang, P., Li, Z., Hou, Y., & Li, W. (2016b). Action recognition based on joint trajectory maps using convolutional neural networks. In ACM on multimedia conference (pp. 102–106).
Wang, Y., & Hoai, M. (2016). Improving human action recognition by non-action classification. In IEEE conference on computer vision and pattern recognition (pp. 2698–2707).
Weinland, D., Ronfard, R., & Boyer, E. (2006). Free viewpoint action recognition using motion history volumes. Computer Vision and Image Understanding, 104(2), 249–257.
Weinland, D., Boyer, E., & Ronfard, R. (2007). Action recognition from arbitrary views using 3D exemplars. In IEEE international conference on computer vision (pp. 1–7).
Yang, X., & Tian, Y. (2014). Super normal vector for activity recognition using depth sequences. In IEEE conference on computer vision and pattern recognition (pp. 804–811).
Yilmaz, A., & Shah, M. (2005). Actions sketch: A novel action representation. In IEEE conference on computer vision and pattern recognition (Vol. 1, pp. 984–989).
Yu, F., Zhang, Y., Song, S., Seff, A., & Xiao, J. (2015). LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop. CoRR.
Yu, M., Liu, L., & Shao, L. (2016). Structure-preserving binary representations for RGB-D action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(8), 1651–1664.
Zhang, B., Wang, L., Wang, Z., Qiao, Y., & Wang, H. (2016). Real-time action recognition with enhanced motion vector CNNs. In IEEE conference on computer vision and pattern recognition (pp. 2718–2726).
Zhang, Z., Wang, C., Xiao, B., Zhou, W., Liu, S., & Shi, C. (2013). Cross-view action recognition via a continuous virtual path. In IEEE conference on computer vision and pattern recognition (pp. 2690–2697).
Zheng, J., & Jiang, Z. (2013). Learning view-invariant sparse representations for cross-view action recognition. In IEEE international conference on computer vision (pp. 3176–3183).
Zhu, W., Hu, J., Sun, G., Cao, X., & Qiao, Y. (2016). A key volume mining deep framework for action recognition. In IEEE conference on computer vision and pattern recognition (pp. 1991–1999).
Acknowledgements
This research was sponsored by the Australian Research Council Grant DP160101458. The Tesla K-40 GPU used for this research was donated by the NVIDIA Corporation.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Ivan Laptev.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Liu, J., Rahmani, H., Akhtar, N. et al. Learning Human Pose Models from Synthesized Data for Robust RGB-D Action Recognition. Int J Comput Vis 127, 1545–1564 (2019). https://doi.org/10.1007/s11263-019-01192-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01192-2