
Abstract
With the rapid development of computer hardware and intelligent technology, the intelligent combat of unmanned aerial vehicle (UAV) cluster will become the main battle mode in the future battlefield. The UAV cluster as a multi-agent system (MAS), the traditional single-agent reinforcement learning (SARL) algorithm is no longer applicable. To truly achieve autonomous and cooperative combat of the UAV cluster, the multi-agent reinforcement learning (MARL) algorithm has become a research hotspot. Considering that the current UAV cluster combat is still in the program control stage, the fully autonomous and intelligent cooperative combat has not been realized. To realize the autonomous planning of the UAV cluster according to the changing environment and cooperate with each other to complete the combat goal, we propose a new MARL framework which adopts the policy of centralized training with decentralized execution, and uses actor-critic network to select the execution action and make the corresponding evaluation. By improving the structure of the learning network and refining the reward mechanism, the new algorithm can further optimize the training results and greatly improve the operation security. Compared with the original multi-agent deep deterministic policy gradient (MADDPG) algorithm, the ability of cluster cooperative operation gets effectively enhanced.










Similar content being viewed by others
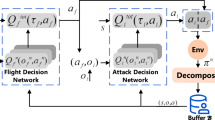
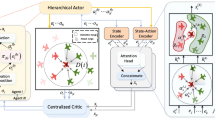
Availability of data and material
The data in our paper is availability. The experimental data in this paper is not loaded, and all data are directly output from simulation test, which is transparent.
Code availability
The research code is compiled with Python based on Tensorflow. The data can be availability, but I do not want to disclose it temporarily, because the code needs to make further research and improvement.
References
Babuska R, Busoniu L, Schutter BD (2006) Reinforcement learning for multi-agent systems. In: Proceedings of the 11th international conference on emerging technologies and factory automation. IEEE, Prague. http://www.dcsc.tudelft.nl
Busoniu L, Babuska R, Schutter BD (2010) Multi-agent reinforcement learning: an overview. In: Srinivasan D, Jain LC (eds) Innovations in multi-agent systems and applications—1. Studies in computational intelligence, vol 310, pp 183–221, Springer, Berlin. https://doi.org/10.1007/978-3-642-14435-6_7
Baker B, Gupta O, Naik N, Raskar R (2017) Designing neural network architectures using reinforcement learning. In: International conference on learning representations. arXiv:1611.02167v2
Duryea E, Ganger M, Hu W (2016) Exploring deep reinforcement learning with multi q-learning. Intell Control Autom 7(4):129–144. https://doi.org/10.4236/ica.2016.74012
Das-Stuart A, Howell KC, Folta D (2019) Rapid trajectory design in complex environments enabled by reinforcement learning and graph search strategies. Acta Astronaut 171:172–195. https://doi.org/10.1016/j.actaastro.2019.04.037
Fu XW, Pan J, Wang HX, Gao XG (2020) A formation maintenance and reconstruction method of UAV swarm based on distributed control. Aerosp Sci Technol. https://doi.org/10.1016/j.ast.2020.105981
Gupta JK, Egorov M, Kochenderfer M (2017) Cooperative multi-agent control using deep reinforcement learning. In: Sukthankar G., Rodriguez-Aguilar J (eds) International conference on autonomous agents and multiagent systems, lecture notes in computer science, vol 10642, pp 66–83, Springer, Cham. https://doi.org/10.1007/978-3-319-71682-4_5
Goecks VG, Leal PB, White T, Valasek J, Hartl DJ (2018) Control of morphing wing shapes with deep reinforcement learning. In: 2018 AIAA information systems-AIAA Infotech @ Aerospace, Janu, Kissimmee, Florida. https://doi.org/10.2514/6.2018-2139
Hausknecht M, Stone P (2017) Deep recurrent q-learning for partially observable MDPs. Comput Sci. arXiv:1507.06527v4
Imanberdiyev N, Fu C, Kayacan E, Chen IM (2016) Autonomous navigation of UAV by using real-time model-based reinforcement learning. In: 14th international conference on control, automation, robotics and vision. https://doi.org/10.1109/ICARCV.2016.7838739
Jordan MI, Mitchell TM (2015) Machine learning: trends, perspectives, and prospects. Science 349:255–260. https://doi.org/10.1126/science.aaa8415
Jiang JX, Zeng XY, Guzzetti D, You YY (2020) Path planning for asteroid hopping rovers with pre-trained deep reinforcement learning architectures. Acta Astronaut 171:265–279. https://doi.org/10.1016/j.actaastro.2020.03.007
Kersandt K (2018) Deep reinforcement learning as control method for autonomous UAVs. Universitat Politecnica de Catalunya. http://hdl.handle.net/2117/113948
Littman ML (1994) Markov games as a framework for multi-agent reinforcement learning. In: Proceedings of the 11th international conference on machine learning, Rutgers University, New Brunswick, pp 157–163. https://doi.org/10.1016/B978-1-55860-335-6.50027-1
Lillicrap TP, Hunt JJ, Pritzel A, Heess N, Wierstra D (2015) Continuous control with deep reinforcement learning. Int Conf Learn Represent. https://doi.org/10.1016/S1098-3015(10)67722-4
Liu QH, Liu XF, Cai GP (2018) Control with distributed deep reinforcement learning: learn a better policy. arXiv:1811.10264v2
Liu YX, Liu H, Tian YL, Sun C (2020) Reinforcement learning based two-level control framework of UAV swarm for cooperative persistent surveillance in an unknown urban area. Aerosp Sci Technol. https://doi.org/10.1016/j.ast.2019.105671
La HM, Nguyen T, Le TD, Jafari M (2017) Formation control and obstacle avoidance of multiple rectangular agents with limited communication ranges. IEEE Trans Control Netw Syst 4(4):680–691. https://doi.org/10.1109/TCNS.2016.2542978
La HM, Sheng W (2012) Dynamic target tracking and observing in a mobile sensor network. Robot Auton Syst 60(7):996–1009. https://doi.org/10.1016/j.robot.2012.03.006
Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, Mordatch I (2017) Multi-agent actor-critic for mixed cooperative-competitive environments. In: Proceedings of the neural information processing systems. arXiv:1706.02275v3
Lowe R, Wu Y, Tamar A, Harb J (2018) Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv:1706.02275v3
Li CG, Wang M, Yuan QN (2008) A mulit-agent reinforcement learning using actor-critic methods. In: Proceedings of the 7th international conference on machine learning and cybernetics, IEEE, vol 2. https://doi.org/10.1109/ICMLC.2008.4620528
Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, Hassabis D (2015) Human-level control through deep reinforcement learning. Nature 518:529–533. https://doi.org/10.1038/nature14236
Musavi N, Onural D, Gunes K, Yildiz Y (2017) Unmanned aircraft systems airspace integration: a game theoretical framework for concept evaluations. J Guid Control Dyn 40(1):96–109. https://doi.org/10.2514/1.G000426
Nagabandi A, Kahn G, Fearing RS, Levine S (2017) Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. arXiv:1708.02596v2
Nguyen TT, Nguyen ND, Nahavandi S (2019) Deep reinforcement learning for multi-agent systems: a review of challenges, solutions and applications. arXiv:1812.11794v2
Peters J, Schaal S (2007) Policy gradient methods for robotics. Int Conf Intell Robots Syst IEEE. https://doi.org/10.1109/IROS.2006.282564
Petar K, Sylvain C, Darwin C (2013) Reinforcement learning in robotics: applications and real-world challenges. Robotics 2(3):122–148. https://doi.org/10.3390/robotics2030122
Silver D, Lever G, Heess N, Degris T, Wierstra D, Riedmiller M (2014) Deterministic policy gradient algorithms. In: Proceedings of the 31st international conference on machine learning, Beijing, 21–26 June 2014, pp 387–395
Schmidhuber J (2015) Deep learning in neural networks: an overview. Neural Netw 61:85–117. https://doi.org/10.1016/j.neunet.2014.09.003
Wang ZY, Freitas ND, Lanctot M (2016) Dueling network architectures for deep reinforcement learning. In: Proceedings of the international conference on machine learning, New York, pp 1995–2003. arXiv:1511.06581v3
Wen N, Liu ZH, Zhu LP, Sun Y (2017) Deep reinforcement learning and its application on autonomous shape optimization for morphing aircrafts. J Astronaut 38:1153–1159. https://doi.org/10.3873/j.issn.1000-1328.2017.11.003
Wu YH, Yu ZC, Li CY, He MJ, Chen ZM (2020) Reinforcement learning in dual-arm trajectory planning for a free-floating space robot. Aerosp Sci Technol. https://doi.org/10.1016/j.ast.2019.105657
Xu D, Hui Z, Liu YQ, Chen G (2019) Morphing control of a new bionic morphing UAV with deep reinforcement learning. Aerosp Sci Technol 92:232–243. https://doi.org/10.1016/j.ast.2019.05.058
Yann LC, Bengio Y, Hinton G (2015) Deep learning. Nature 521:436–444. https://doi.org/10.1038/nature14539
Yang Z, Merrick K, Abbass H, Jin L (2017) Multi-task deep reinforcement learning for continuous action control. In: Proceedings of the 26th international joint conference on artificial intelligence, pp 3301–3307. https://doi.org/10.24963/ijcai.2017/461
Yao P, Wang HL, Ji HX (2016) Multi-UAVs tracking target in urban environment by model predictive control and improved grey wolf optimizer. Aerosp Sci Technol 55:131–143. https://doi.org/10.1016/j.ast.2016.05.016
Yao P, Wang HL, Su ZK (2016) Cooperative path planning with applications to target tracking and obstacle avoidance for multi-UAVs. Aerosp Sci Technol 54:10–22. https://doi.org/10.1016/j.ast.2016.04.002
Yang XX, Wei P (2020) Scalable multi-agent computational guidance with separation assurance for autonomous urban air mobility. J Guid Control Dyn 43(8):1473–1486. https://doi.org/10.2514/1.G005000
Zhen ZY, Xing DJ, Gao C (2018) Cooperative search-attack mission planning for multi-UAV based on intelligent self-organized algorithm. Aerosp Sci Technol 76:402–411. https://doi.org/10.1016/j.ast.2018.01.035
Funding
This work was partially supported by the National Natural Science Foundation of China (Nos. 11872293, 11672225), and the Program of Introducing Talents and Innovation of Disciplines (No. B18040).
Author information
Authors and Affiliations
Contributions
The research code is compiled mainly by the first author Dan Xu. The paper is written by Dan Xu. The research significance and practicality are produced by Gang Chen and the funding is also from him.
Corresponding author
Ethics declarations
Conflict of interest
To the best of our knowledge, the named authors have no conflict of interest, financial or otherwise.
Ethics approval
All the authors have no religious beliefs, we do not have racial discrimination, we pursuit fairness.
Consent to participate
All the authors consent to participate.
Consent for publication
All the authors consent for publication.
Rights and permissions
About this article

Cite this article
Xu, D., Chen, G. The research on intelligent cooperative combat of UAV cluster with multi-agent reinforcement learning. AS 5, 107–121 (2022). https://doi.org/10.1007/s42401-021-00105-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42401-021-00105-x