
Abstract
It is well established that decay and interference are the two main causes of forgetting. In the present study, we specifically focus on the impact of interference on memory forgetting. To do so, we tested Guinea baboons (Papio papio) on a visuo-motor adaptation of the Serial Reaction Time task in which a target sequence is repeated, and a random sequence is interposed between repetitions, a similar situation as the one used in the Hebb repetition paradigm. In this task, one three-item sequence, the repeated sequence, was presented every second trial and interleaved with random sequences. Interference was implemented by using random sequences containing one item that was also part of the repeated sequence. In a first condition, the overlapping item was located at the same position as the repeated sequence. In a second condition, the overlapping item was located at one of the two other positions. In a third condition, there was no overlap between repeated and random sequences. Contrary to previous findings, our results reveal similar learning slopes across all three conditions, suggesting that interference did not affect sequence learning in the conditions tested. Findings are discussed in the light of previous research on sequence learning and current models of memory and statistical learning.
Similar content being viewed by others

Introduction
According to the influential model of statistical learning PARSER (Perruchet & Vinter, 1998), when a to-be-learned sequence of items is not frequently repeated, the memory trace of this percept rapidly vanishes as a consequence of spontaneous decay and interference with similar material. In the present study, we specifically focus on the impact of interference on the learning of sequential material. In other words, we examine whether and how similarities between random and repeated visuo-spatial sequences induce interference in active representations in working memory and in the creation of sequential long-term memory representations. Indeed, when learning sequences in everyday life (e.g., sequencing movements in typing or sports, when playing an instrument, or sequencing sounds in speech), there is generally more or less overlap between the to-be-learnt items composing a sequence (e.g., movements or sounds), which is likely to induce interference between sequences and consequently to affect learning.
The effect of interference on sequence learning has been studied in humans by Page et al. (2013) with the Hebb repetition paradigm. In that study, the authors examined to what extent item-overlap is likely to affect learning in adults. Participants were presented with a repeated Hebb sequence of seven single-syllable words that were interposed by either non-overlapping or fully overlapping filler sequences. The fully overlapping filler sequences were composed of exactly the same items as those contained in the Hebb sequence, but in different orders (e.g., Hebb sequence = “flea, vase, disc, moss, shed, curb, soup”; filler sequence = “shed, disc, flea, soup, moss, curb, vase”), while the non-overlapping filler sequences did not share any item with the Hebb sequence (e.g., Hebb sequence = “flea, vase, disc, moss, shed, curb, soup”; filler sequence = “cow, cart, wink, seam, coin, arch, grown”). Results revealed reliable learning in the non-overlapping condition, while no learning was observed in the fully overlapping condition, suggesting that interference significantly affected learning. However, in our view, full overlap between items is very rare in natural learning situations. Taking the example of vocabulary acquisition in infants, not all words of a given language are anagrams of each other (e.g., eat and tea) and rather do, in many cases, share at most some phonemes only (e.g., / kɒpi / [copy] versus / kɒfi / [coffee]). As a consequence, mouth movements during speech production of different words are not systematically permutations of the same movements. The same is true for the acquisition of non-linguistic sequences such as sequences of movements when tapping out a phone number, learning to drive a car, or when playing an instrument.
As far as we know, only one study in humans used a semi-overlapping design, meaning that random and repeated sequence shared some but not all items (Saint-Aubin et al., 2015). However, as the aim of that study was different from ours, the degree of item-overlap between sequences was not controlled for and therefore conclusions about the effect of interference on sequence learning cannot be drawn.
The aim of the present study was thus to examine the impact of interference on sequential statistical learning by proposing a semi-overlapping design, which is more similar to what is usually observed in natural learning situations. To do so, we created an adaptation of the Serial Reaction Time task (Nissen & Bullemer, 1987) combined with the advantage of the Hebb repetition paradigm allowing to measure the impact of interference by inserting semi-overlapping random sequences between repeated sequences. In the present study, we tested a population of Guinea baboons in order to examine the impact of interference on sequence learning by controlling for language-related refreshing mechanisms, which are absent in non-human primates. Baboons were presented with sequences of three target locations on the touch screens. One random sequence was inserted between the presentations of the repeated sequence. In a first condition (Condition 1), the random sequences contained one location that was part of the repeated sequence, and this location was always presented at the same position (e.g., repeated sequence = 7 6 2, random sequence = 7 9 1 or 9 6 1 or 1 9 2, etc., random sequences were presented in random order). In a second condition (Condition 2), random sequences again contained one item of the repeated sequence but this time, it was located at one of the two remaining positions compared to the repeated sequence (e.g., repeated sequence = 7 6 2, random sequence = 9 7 1 or 9 1 7, etc., and the same for the two other locations 6 and 2, again presented in random order). In the third condition (Condition 3), we used a non-overlapping design, meaning that different locations were used for the repeated and the random sequences (e.g., repeated sequence = 7 6 2, random sequence = 4 9 1). In the present study, we hypothesize that the representation of the items of the repeated sequence and the connections between these items within the sequence (Burgess & Hitch, 2006) may interfere with the item representations of the overlapping random sequences (in Conditions 1 and 2) as a consequence of overwriting of features shared by these sequences (Oberauer & Kliegel, 2006). More precisely and according to previous studies (Page et al., 2013; Smalle et al., 2016), we expected to observe weaker or even no reliable learning in the two overlapping conditions but reliable learning in the non-overlapping condition. Moreover, we expected stronger interference in the “same-position” condition (Condition 1) compared to Condition 2. Indeed, imagine the following repeated sequence: 7 6 2, the co-occurrence between e.g., 7 and 6 should be more affected when being alternately presented with the following random sequence: 7 1 9 (Condition 1) compared to e.g., 1 9 7 (Condition 2), because 7 at the first position can here be associated to 6 or to 1, leading to an unstable representation of this association.
Methods
Participants
We tested 25 Guinea baboons (Papio papio, 16 females) living in a social group at the CNRS primate facility in Rousset (France). The baboons were housed in a 700 m2 outdoor enclosure with access to indoor housing.
Apparatus
Baboons had free access to 14 Automated Learning Devices for Monkeys (ALDMs, Fagot & Bonté, 2010; Fagot & Paleressompoulle, 2009) equipped with touch screens and a food dispenser. When entering the ALDM test box, baboons were identified by microchips implanted in each arm. The system saved the last trial the baboon had achieved before leaving the box, allowing him/her to continue the task later on where it had stopped. The experiment was controlled by E-Prime 2.0 software (Psychology Software Tools, Pittsburgh, PA, USA). All the baboons were familiar with touch-screen experimentation.
Materials and procedure
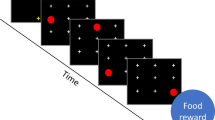
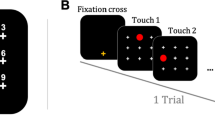
To begin a trial, baboons must press the yellow fixation crossFootnote 1 centered at the bottom of the screen. After pressing the cross, they saw a black screen that was divided into an invisible matrix of (3 × 3) cells, each containing a white cross in their center (see Fig. 1a and b). In this task, baboons needed to touch sequentially one red circle that moved on the screen in sequences of three target locations. When the baboon touched the first target position, it disappeared and was replaced by the white cross. The red circle then appeared at the second position and must again be touched before being presented with the last position of the sequence, where a last touch was required. Reward (grains of dry wheat) was delivered at the end of each sequence of three correct touches. In case of an error (i.e., the participant touched another location than the target one or failed to touch the screen within 5,000 ms), a green screen was displayed for 3,000 ms as a marker of failure.

a Representation of the touch screen with the nine locations and example of the experimental display and stimuli presentation for repeated and random sequences in Condition 1 (overlap at the same position). b Representation of the touch screen with the nine locations and example of the experimental display and stimuli presentation for repeated and random sequences in Condition 2 (overlap at a different position)
The experiment therefore consisted of three conditions: Two overlapping conditions (Conditions 1 and 2) and one non-overlapping condition (Condition 3). Each baboon completed all three conditions and the order of Conditions 1 and 2 was randomized. Thirteen baboons began with the first condition and subsequently completed the second one, while 12 baboons completed the second and then the first condition. The non-overlapping condition was part of a previous study conducted in our lab (Ordonez Magro et al., revision submitted). Each condition began with a random phase during which baboons were presented with three blocks of 100 random sequences of three positions. This phase was used as a familiarization phase at the beginning of the experiment as well as a phase allowing to “clean up” the memory trace of the previously learned repeated sequence to avoid interference between to-be-learned repeated sequences across conditions. The test phase began when the baboon achieved a performance higher than 80% correct within three consecutive blocks of 100 random trials. Response times (RTs) between the appearance of the red circle and the participant’s touch of each of the three positions for each sequence was recorded and served as a dependent variable. The present task follows a one-filler design, meaning that the presentations of the repeated sequence were spaced by one random sequence (i.e., random-repeated-random-repeated-…). Baboons performed five blocks of 100 trials, resulting in 250 presentations of the repeated sequence plus 250 presentations of the random sequence. To perform the 500 trials, baboons visited the test boxes in Condition 1 about 8.70 times on average, with an average of 65.96 trials per visit. In Condition 2, they visited the test boxes about 7.35 times with an average of 74.35 trials per visit. Finally, in Condition 3, baboons visited the test boxes about 8.12 times with an average of 69.85 trials per visit.
To avoid learning effects across conditions, participants were presented with a different repeated sequence in each condition (see Table 1 for an example). Repeated sequences were matched across positions for motor difficulty. To do so, a random phase of sequence production of six positions for 1,000 trials was conducted on 13 baboons. Based on these random trials, a baseline measure for all possible transitions from one location to another was computed by calculating mean RTs for each transition (e.g., from position 1 to 9), leading to a 9 × 9 matrix of mean RTs (see Appendix 1).
In this experiment, and in accordance with the serial recurrent network (SRN; Elman, 1990) model, learning was measured by comparing RTs between the three positions of the sequence. In a repeating three-position sequence such as e.g., 7 6 2, location 7 is always followed by location 6 and location 6 is always followed by location 2. Thus, location 7 (Position 1) is less predictable over trials, because of the previously presented random sequences, compared to locations 6 (Position 2) and 2 (Position 3), which benefit from the systematic presence of 7 or 7 6 presented just before. Thus, if learning takes place, we should observe faster RTs for Positions 2 and 3 compared to Position 1.
To be able to assess learning accurately, the mean RTs of the transition between Positions 1 and 2 (transition 1) and the transition between Positions 2 and 3 (transition 2) of the repeated sequences should be comparable. In our previous, study (Ordonez Magro et al., revision submitted), we created our repeated sequences by computing the RTs for the first and the second transition of all possible 504 triplets of the matrix and retained the triplets with the smallest difference of RTs (going from 2.06 ms to 15.55 ms), by making sure to choose sequences that were not too similar to each other (e.g., avoiding that all sequences begin with the same location). For the present study, we used novel sequences and thus retained the next five triplets of the list with the smallest difference of RTs (going from 6.97 ms to 18.22 ms), again making sure that they are not too similar too each other.
To create the random sequences of Condition 1, we computed, for each location, all sequences containing the given location at the same position and retained only those that did not contain the two remaining locations. For example, taking the repeated sequence 7 6 2, we computed all sequences starting with 7 and retained those that did not contain 6 and 2. We did the same for the location 6 and the location 2. This gave us a total of 90 different random sequences for Condition 1. Regarding Condition 2, we computed, for each location, all sequences that did contain the given location but at a different position and again retained those that did not contain the two remaining locations of the repeated sequence. Taking the example of the repeated sequence 7 6 2, we computed all random sequences containing the location 7 at position two or three and retained those that did not contain 6 and 2. We did the same for locations 6 and 2. This gave us a total of 180 different random sequences for Condition 2. The presentation order of the random sequences was randomized across trials.
Analyses
The ability of monkeys to learn the sequence was assessed by looking at the evolution of RTs on the three positions by computing linear regression analyses. The slope of the repeated sequence for the less predictable Position 1 and the mean slope of the predictable Positions 2 and 3 of the linear regression was used as an index of learning (see Fig. 2 for an example. To see the learning slopes for each baboon, each position, and each condition, see https://osf.io/6cpfm/?view_only=35017b02cc2947688636ee7620e1906f).

Evolution of response times (RTs) for all three positions of the repeated sequence and mean slopes for one individual (Mako) across the 250 trials for Condition 1
Results
We retained the 17 baboons (13 females, age range 3.58–25.16 y) who completed all three conditions (for the full data set, see https://osf.io/6cpfm/?view_only=35017b02cc2947688636ee7620e1906f). As in previous studies on regularity extraction in non-human primates (Malassis et al., 2018; Minier et al., 2016; Rey et al., 2019, 2022; Tosatto et al., 2022), analyses were only conducted on the repeated sequences (but see Appendix 3, for some analyses on the random sequences). For these sequences, baboons obtained a mean accuracy level of 99.0% (SD = 19.0%) in Condition 1 (item-overlap at the same position), of 99.1% (SD = 15.8%) in Condition 2 (item-overlap at a different position), and of 98.4% (SD = 15.7%) in Condition 3 (no overlap)Footnote 2. Incorrect trials were removed from the data set. We then removed RTs greater than 800 ms and subsequently conducted a recursive trimming procedure excluding RTs greater than two standard deviations from the mean for each of the three possible positions in a block of 50 trials and for each baboon (see Appendix 2 for the mean RTs for both repeated and random sequences as a function of block and condition). To measure learning of the repeated sequence, we looked at the evolution of RTs at each of the three positions in the sequence. Previous studies have shown that learning of the sequence leads to faster RTs on the predictable positions (i.e., Positions 2 and 3) compared to the less predictable position (i.e., Position 1) due to stronger contextual information (Elman, 1990; Malassis et al., 2018; Minier et al., 2016; Rey et al., 2019, 2020).
More precisely, as a measure of learning we computed, for each baboon, a slope on the RTs for each of the three positions of the repeated sequence and for each condition. We averaged the slopes of Positions 2 and 3 for which learning was possible and compared them with the slope of the less predictable Position 1Footnote 3. We ran a 3 (Condition: Condition 1, Condition 2, and Condition 3) × 2 (Position: Position 1 vs. mean of (Position 2 + 3)) repeated measures ANOVA on the learning slopes (see Fig. 3). Bayesian Factors (BF) are also reported, a major advantage of a Bayesian statistical framework is that it allows to quantify evidence in favor of, but also against, the presence of an effect, and hence both positive and null effects can be reliably interpreted (Kruschke et al., 2012; Wagenmakers, 2007). The Bayesian model comparison approach directly compares the null hypothesis to the alternative hypothesis (i.e., the effect of interest) and assesses evidence for the null effect and the effect of interest simultaneously (Dienes, 2014). Results are interpreted using the Bayes factor (BF), which reflects the likelihood ratio of two compared models. The BF10 is used to determine the likelihood ratio of the alternative model relative to the null model. A BF10 > 3 provides anecdotal evidence; a BF10 > 10 provides strong evidence, and a BF10 > 100 provides decisive evidence for the alternative hypothesis, while a BF01 < 0.33 provides anecdotal evidence; a BF01 < 0.10 provides strong evidence, and a BF01 < 0.01 provides decisive evidence for the null hypothesis (Jeffreys, 1961). The analyses were conducted with the JASP software package (JASP Team, 2021), using default settings for Cauchy prior distribution and the Monte Carlo Markov Chain Method for parameter estimation (Wagenmakers et al., 2018). Analyses revealed no significant main effect of Condition (F(2,32) = 0.367, p = .696, η2 = .022, BF01 = 8.12), a significant main effect of Position (F(1,16) = 27.184, p < .001, η2 = .629, BF10 > 100) with a steeper mean learning slope for Positions 2 and 3 (Mean = -.139, SD = .114) compared to Position 1 (Mean = -.020, SD = .108), and no significant interaction between Condition and Position (F(2,32) = 1.599, p = .218, η2 = .091, BF01 = 0.33). Thus, our findings showed faster mean RTs for the predictable Positions 2 and 3 compared to the less predictable Position 1 for all three conditions, and crucially, the mean RTs of the predictable Positions 2 and 3 were significantly different from 0 (Condition 1: Mean = -0.151, CI [-0.103, -0.199]; Condition 2: Mean = -0.144, CI [-0.097, -0.191]; Condition 3: Mean = -0.122, CI [-0.055, -0.189]), while this was not the case for Position 1 (Condition 1: Mean = 0.011, CI [0.058, -0.036]; Condition 2: Mean = -0.045, CI [0.004, -0.086]; Condition 3: Mean = -0.026, CI [0.036, -0.088]). Thus, findings revealed that learning occurred for all three conditions and the absence of a main effect of Condition as well as of an interaction between Condition and Position indicates that learning was similar across all conditions. In sum, it seems that interference did not affect learning significantly in the conditions tested in the present study using a semi-overlapping design.

Mean slopes for Position 1 and the average for Positions 2 and 3 for each condition: Condition 1 (overlapping item located at the same position), Condition 2 (overlapping item located at a different position), and Condition 3 (no overlap between random and repeated sequences). Error bars represent 95% confidence intervals
Discussion
In the present study, we examined the impact of interference on the learning of item sequences. According to the influential model of statistical learning PARSER (Perruchet & Vinter, 1998) and previous experimental studies on sequence learning (Page et al., 2013; Smalle et al., 2016), the learning of sequences of items is significantly hindered in situations in which interference is caused by the presentation of similar sequences. Note that most studies in humans use either fully overlapping random and repeated sequences (e.g., Attout et al., 2020; Bogaerts et al., 2016; Hebb, 1961; Szmalec et al., 2011), meaning that random sequences contain all items of the repeated sequence, but in a different order, or non-overlapping sequences (e.g., Hitch et al., 2009; Ordonez Magro et al., 2018, 2020, 2021;Page et al., 2013 ; Smalle et al., 2016), meaning that the repeated and the random sequences are composed of different items. To our knowledge, only one study in humans uses a semi-overlapping design, meaning that random and repeated sequence share some but not all items (Saint-Aubin et al., 2015). Moreover, previous studies in non-human primates examining the nature of regularity extraction in sequence learning (Malassis et al., 2018; Minier et al., 2016; Rey et al., 2019, 2022; Tosatto et al., 2022) usually use a design similar to the one introduced by Saffran et al. (1996), where baboons are repeatedly exposed to one and the same sequence of locations. This design, however, does not allow researchers to measure the impact of interference on sequence learning. The present study therefore proposes a learning paradigm mixing repeated and random sequences with a semi-overlapping design in non-human primates. In our semi-overlapping design, repeated and random sequences shared only one item, either located at the same position (Condition 1) or on one of the two other positions (Condition 2). This design is, in our opinion, more representative of what generally occurs in natural learning situations like, for instance, learning to play an instrument, the acquisition of sports, learning to drive a car, sequencing speech sounds, etc. Moreover, the present study is the first one to use a semi-overlapping learning paradigm in non-human primates, allowing us to measure interference in memory while controlling for language-related factors.
In contrast to previous studies (Page et al., 2013; Smalle et al., 2016) and to what we predicted on the basis of these studies, we did not observe a negative impact of interference on sequence learning. Indeed, our analyses showed that learning slopes were comparable across conditions. One potential explanation for this finding may be the fact that we used a semi-overlapping design rather than the fully overlapping design used in the previous studies. Indeed, a full overlap between all items of a sequence undeniably causes more interference as compared to partial overlap. However, our findings, even if unexpected, are not totally surprising, given that such interference would be a major handicap for learning in natural situations (for a discussion, see also Page et al., 2013).
Moreover, according to PARSER (Perruchet & Vinter, 1998), the impact of interference may become practically negligible for a percept, once it has been encountered repeatedly and its representation in long-term memory has become relatively robust. Thus, our finding that interference does not affect learning is compatible with the predictions of PARSER and with what is observed in natural learning situations involving a high level of interference.
The absence of a significant difference in learning the semi-overlapping repeated sequences (Conditions 1 and 2) compared to the non-overlapping repeated sequences (Condition 3) can also be explained in terms of frequency of occurrence. Indeed, in our semi-overlapping conditions the random sequences contained an item that was also part of the repeated sequence, which certainly increased the frequency of occurrence (during the experiment) of this given overlapping item. Thus, it is possible that the repetition of the same item in the random sequence might have strengthened its representation in long-term memory, which in turn would have facilitated the learning of item-item associations (i.e., co-occurrences between the three positions), via associative learning mechanisms (Majerus et al., 2012; Perruchet & Pacton, 2006; Perruchet & Vinter, 1998). This hypothesis is in line with sequence learning models (Page & Norris, 1998; Perruchet & Vinter, 1998), according to which learning is strongly dependent on repetition, a major component determining consolidation in long-term memory. There is indeed some evidence in our data that supports this hypothesis (see Fig. 3). Even if the difference between conditions is not significant, there was a slightly steeper learning slope for Positions 2 and 3 for the overlapping conditions (Conditions 1 and 2, -0.151 and -0.141, respectively) compared to the non-overlapping condition (Condition 3, -0.122) suggesting that the presentation of an overlapping item in the random sequences may have facilitated, rather than perturbed, the learning of the repeated sequence. Moreover, the observed absence of interference between random and repeated sequences can also be explained in terms of context signals. Indeed, according to the model of long-term learning proposed by Burgess and Hitch (2006), each new sequence is associated with a new set of context nodes, while a repeated sequence is associated with its own set of context signals and these connections are further strengthened with each repetition. Based on this, our random and repeated sequences, even if they had one item in common, might have been associated with different context nodes, consequently limiting the interference between random and repeated sequences.
Finally, our observations are in line with several previous studies on non-human primates, showing that monkeys like tamarins, macaques, and baboons can extract regular patterns from continuous sequences allowing them to learn predictable motor sequences by using statistical cues (Hauser et al., 2001; Heimbauer et al., 2012; Locurto et al., 2010, 2013; Malassis et al., 2018; Minier et al., 2016; Procyk et al., 2000; Rey et al., 2019, 2022; Tosatto et al., 2022; Wilson et al., 2013, 2015).
In sum, the present study used a semi-overlapping design to examine the influence of interference on memory forgetting in conditions that better mimic natural learning conditions compared to prior studies. In the present work, we observed that interference has not such a deleterious impact on sequence learning as would be expected based on the results of prior research. In contrast to the observation of previous studies, suggesting that no learning is possible when interference occurs (Page et al., 2013; Smalle et al., 2016), our findings are easy to reconcile with what is observed in natural sequence learning situations, where learning still takes place in an interfering environment.
Data availability
The datasets generated and analyzed during the current study are available via the Open Science Framework and can be accessed at: https://osf.io/6cpfm/?view_only=35017b02cc2947688636ee7620e1906f.
Code availability
Not applicable.
Notes
Thus, the inter-stimulus interval depends on the moment the baboon decides to press the yellow fixation cross. As the length of the inter-stimulus interval can help subjects to separate trials and eventually help to minimize interference between trials, it is important to mention that we deliberately decided to let the baboons initiate the next trials in order to make sure that they are alert after having been rewarded with the grains. For a video, see https://osf.io/7h8cd/?view_only=ec264f23c01f4b94b4571543b494d867
As this condition was the same as in our previous study, we only retained the 500 first trials in order to compare the results across experiments.
We compared the learning slope of Position 1 with the mean slope of Positions 2 + 3 because if learning takes place, we should observe a steeper learning slope for the predictable Positions 2 and 3 compared to the less predictable Position 1. Moreover, averaging both predictable positions allowed us to obtain more data points and thus more robust results.
References
Attout, L., Ordonez Magro, L., Szmalec, A., & Majerus, S. (2020). The developmental neural substrates of Hebb repetition learning and their link with reading ability. Human Brain Mapping. https://doi.org/10.1002/hbm.25099
Bogaerts, L., Szmalec, A., De Maeyer, M., Page, M. P. A., & Duyck, W. (2016). The involvement of long-term serial-order memory in reading development : A longitudinal study. Journal of Experimental Child Psychology, 145, 139–156. https://doi.org/10.1016/j.jecp.2015.12.008
Burgess, N., & Hitch, G. J. (2006). A revised model of short-term memory and long-term learning of verbal sequences. Journal of Memory and Language, 55(4), 627–652. https://doi.org/10.1016/j.jml.2006.08.005
Dienes, Z. (2014). Using Bayes to get the most out of non-significant results. Frontiers in Psychology, 5. https://doi.org/10.3389/fpsyg.2014.00781
Elman, J. L. (1990). Finding Structure in Time. Cognitive Science, 14(2), 179–211. https://doi.org/10.1207/s15516709cog1402_1
Fagot, J., & Bonté, E. (2010). Automated testing of cognitive performance in monkeys : Use of a battery of computerized test systems by a troop of semi-free-ranging baboons (Papio papio). Behavior Research Methods, 42(2), 507–516. https://doi.org/10.3758/BRM.42.2.507
Fagot, J., & Paleressompoulle, D. (2009). Automatic testing of cognitive performance in baboons maintained in social groups. Behavior Research Methods, 41(2), 396–404. https://doi.org/10.3758/BRM.41.2.396
Hauser, M. D., Newport, E. L., & Aslin, R. N. (2001). Segmentation of the speech stream in a non-human primate : Statistical learning in cotton-top tamarins. Cognition, 78(3), B53–B64. https://doi.org/10.1016/s0010-0277(00)00132-3
Hebb, D. (1961). Distinctive features of learning in the higher animal. In J. F. Delafresnaye (Ed.), Brain mechanisms and learning. Blackwell.
Heimbauer, L. A., Conway, C. M., Christiansen, M. H., Beran, M. J., & Owren, M. J. (2012). A Serial Reaction Time (SRT) task with symmetrical joystick responding for nonhuman primates. Behavior Research Methods, 44(3), 733–741. https://doi.org/10.3758/s13428-011-0177-6
Hitch, G. J., Flude, B., & Burgess, N. (2009). Slave to the rhythm : Experimental tests of a model for verbal short-term memory and long-term sequence learning. Journal of Memory and Language, 61(1), 97–111. https://doi.org/10.1016/j.jml.2009.02.004
JASP Team. (2021). JASP (Version 0.16)[Computer software].
Jeffreys, H. (1961). Theory of probability (3rd ed.). Oxford University Press.
Kruschke, J. K., Aguinis, H., & Joo, H. (2012). The time has come : Bayesian methods for data analysis in the organizational sciences. Organizational Research Methods, 15(4), 722–752. https://doi.org/10.1177/1094428112457829
Locurto, C., Gagne, M., & Nutile, L. (2010). Characteristics of implicit chaining in cotton-top tamarins (Saguinus oedipus). Animal Cognition, 13(4), 617–629. https://doi.org/10.1007/s10071-010-0312-2
Locurto, C., Dillon, L., Collins, M., Conway, M., & Cunningham, K. (2013). Implicit chaining in cotton-top tamarins (Saguinus oedipus) with elements equated for probability of reinforcement. Animal Cognition, 16(4), 611–625. https://doi.org/10.1007/s10071-013-0598-y
Majerus, S., Martinez Perez, T., & Oberauer, K. (2012). Two distinct origins of long-term learning effects in verbal short-term memory. Journal of Memory and Language, 66(1), 38–51. https://doi.org/10.1016/j.jml.2011.07.006
Malassis, R., Rey, A., & Fagot, J. (2018). Non-adjacent Dependencies Processing in Human and Non-human Primates. Cognitive Science, 42(5), 1677–1699. https://doi.org/10.1111/cogs.12617
Minier, L., Fagot, J., & Rey, A. (2016). The Temporal Dynamics of Regularity Extraction in Non-Human Primates. Cognitive Science, 40(4), 1019–1030. https://doi.org/10.1111/cogs.12279
Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of learning : Evidence from performance measures. Cognitive Psychology, 19(1), 1–32. https://doi.org/10.1016/0010-0285(87)90002-8
Oberauer, K., & Kliegl, R. (2006). A formal model of capacity limits in working memory. Journal of Memory and Language, 55(4), 601–626. https://doi.org/10.1016/j.jml.2006.08.009
Ordonez Magro, L., Attout, L., Majerus, S., & Szmalec, A. (2018). Short-and long-term memory determinants of novel word form learning. Cognitive Development, 47, 146–157. https://doi.org/10.1016/j.cogdev.2018.06.002
Ordonez Magro, L., Majerus, S., Attout, L., Poncelet, M., Smalle, E. H. M., & Szmalec, A. (2020). The contribution of serial order short-term memory and long-term learning to reading acquisition : A longitudinal study. Developmental Psychology, 56(9), 1671–1683. https://doi.org/10.1037/dev0001043
Ordonez Magro, L., Majerus, S., Attout, L., Poncelet, M., Smalle, E. H. M., & Szmalec, A. (2021). Do serial order short-term memory and long-term learning abilities predict spelling skills in school-age children? Cognition, 206, 104479. https://doi.org/10.1016/j.cognition.2020.104479
Ordonez Magro, L., Fagot, J., Grainger, J., & Rey, A. (revision submitted). The limits of forgetting in sequential statistical learning. Cognitive Science.
Page, M. P. A., & Norris, D. (1998). The Primacy Model : A New Model of Immediate Serial Recall. Psychological Review, 105(4), 761–781.
Page, M. P. A., Cumming, N., Norris, D., McNeil, A. M., & Hitch, G. J. (2013). Repetition-spacing and item-overlap effects in the Hebb repetition task. Journal of Memory and Language, 69(4), 506–526. https://doi.org/10.1016/j.jml.2013.07.001
Perruchet, P., & Pacton, S. (2006). Implicit learning and statistical learning : One phenomenon, two approaches. Trends in Cognitive Sciences, 10(5), 233–238. https://doi.org/10.1016/j.tics.2006.03.006
Perruchet, P., & Vinter, A. (1998). PARSER : A Model for Word Segmentation. Journal of Memory and Language, 39(2), 246–263. https://doi.org/10.1006/jmla.1998.2576
Procyk, E., Ford Dominey, P., Amiez, C., & Joseph, J. P. (2000). The effects of sequence structure and reward schedule on serial reaction time learning in the monkey. Brain Research. Cognitive Brain Research, 9(3), 239–248. https://doi.org/10.1016/s0926-6410(00)00002-1
Rey, A., Minier, L., Malassis, R., Bogaerts, L., & Fagot, J. (2019). Regularity Extraction Across Species : Associative Learning Mechanisms Shared by Human and Non-Human Primates. Topics in Cognitive Science, 11(3), 573–586. https://doi.org/10.1111/tops.12343
Rey, A., Bogaerts, L., Tosatto, L., Bonafos, G., Franco, A., & Favre, B. (2020). Detection of regularities in a random environment. Quarterly Journal of Experimental Psychology, 73(12), 2106–2118. https://doi.org/10.1177/1747021820941356
Rey, A., Fagot, J., Mathy, F., Lazartigues, L., Tosatto, L., Bonafos, G., et al. (2022). Learning higher-order transitional probabilities in nonhuman primates. Cognitive Science, 46(4), e13121. https://doi.org/10.1111/cogs.13121
Saffran, J. R., Aslin, R. N., & Newport, E. L. (1996). Statistical learning by 8-month-old infants. Science (New York, N.Y.), 274(5294), 1926–1928. https://doi.org/10.1126/science.274.5294.1926
Saint-Aubin, J., Guérard, K., Fiset, S., & Losier, M.-C. (2015). Learning multiple lists at the same time in the Hebb repetition effect. Canadian Journal of Experimental Psychology/Revue Canadienne de Psychologie Expérimentale, 69(1), 89–94. https://doi.org/10.1037/cep0000030
Smalle, E. H. M., Bogaerts, L., Simonis, M., Duyck, W., Page, M. P. A., Edwards, M. G., & Szmalec, A. (2016). Can Chunk Size Differences Explain Developmental Changes in Lexical Learning? Frontiers in Psychology, 6, 1925. https://doi.org/10.3389/fpsyg.2015.01925
Szmalec, A., Loncke, M., Page, M. P. A., & Duyck, W. (2011). Order or disorder ? Impaired Hebb learning in dyslexia. Journal of Experimental Psychology. Learning, Memory, and Cognition, 37(5), 1270–1279. https://doi.org/10.1037/a0023820
Tosatto, L., Fagot, J., Nemeth, D., & Rey, A. (2022). The evolution of chunks in sequence learning. Cognitive Science, 46(4), e13124. https://doi.org/10.1111/cogs.13124
Wagenmakers, E.-J. (2007). A practical solution to the pervasive problems ofp values. Psychonomic Bulletin & Review, 14(5), 779–804.
Wagenmakers, E.-J., Love, J., Marsman, M., Jamil, T., Ly, A., Verhagen, J., Selker, R., Gronau, Q. F., Dropmann, D., Boutin, B., Meerhoff, F., Knight, P., Raj, A., van Kesteren, E.-J., van Doorn, J., Šmíra, M., Epskamp, S., Etz, A., Matzke, D., et al. (2018). Bayesian inference for psychology. Part II : Example applications with JASP. Psychonomic Bulletin & Review, 25(1), 58–76. https://doi.org/10.3758/s13423-017-1323-7
Wilson, B., Slater, H., Kikuchi, Y., Milne, A. E., Marslen-Wilson, W. D., Smith, K., & Petkov, C. I. (2013). Auditory artificial grammar learning in macaque and marmoset monkeys. The Journal of Neuroscience: The Official Journal of the Society for Neuroscience, 33(48), 18825–18835. https://doi.org/10.1523/JNEUROSCI.2414-13.2013
Wilson, B., Smith, K., & Petkov, C. I. (2015). Mixed-complexity artificial grammar learning in humans and macaque monkeys : Evaluating learning strategies. The European Journal of Neuroscience, 41(5), 568–578. https://doi.org/10.1111/ejn.12834
Acknowledgements
This work was supported by the CHUNKED ANR project (#ANR-17-CE28-0013-02) and the ERC advanced grant (#POP-R 742141).
Funding
This work was supported by the CHUNKED ANR project (#ANR-17-CE28-0013-02) and the ERC advanced grant (#POP-R 742141).
Author information
Authors and Affiliations
Contributions
Laura Ordonez Magro conceptualized the design, collected the data, conducted the data analyses, and wrote the paper; Joël Fagot conceptualized the design; Jonathan Grainger helped to write the paper; Arnaud Rey conceptualized the design, conducted data analyses, and helped to write the paper.
Corresponding author
Ethics declarations
Conflicts of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Ethics approval
This research adhered to the applicable French rules for ethical treatment of research animals and received ethical approval from the French Ministery of Education (approval APAFIS#2717-2015111708173794 10 v3).
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Open practices statements
The data and materials for all experiments are available at: https://osf.io/6cpfm/?view_only=35017b02cc2947688636ee7620e1906f and none of the experiments was preregistered.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
Mean response times over a group of 13 baboons for each of the 72 possible transitions calculated from 1,000 random trials. For example, consider the transition [4-8] from Positions 4–8 (4 being the first position of the transition and 8 being the second position). When the red circle was on Position 4, baboons touched it and the target moved to Position 8. The mean response times for that transition [4-8], i.e., 482 ms, corresponds to the time baboons took on average to move from Position 4 to Position 8 (i.e., from the baboon’s touch on Position 4 to the baboon’s touch on Position 8).
First position in transition | Second position in transition | ||||||||
|---|---|---|---|---|---|---|---|---|---|
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
1 | 426 | 421 | 438 | 365 | 360 | 447 | 359 | 371 | |
2 | 506 | 457 | 411 | 377 | 393 | 391 | 365 | 393 | |
3 | 502 | 435 | 443 | 368 | 353 | 439 | 372 | 365 | |
4 | 486 | 423 | 448 | 366 | 374 | 434 | 339 | 358 | |
5 | 485 | 408 | 378 | 444 | 345 | 449 | 392 | 380 | |
6 | 477 | 383 | 379 | 426 | 344 | 448 | 384 | 418 | |
7 | 472 | 424 | 435 | 423 | 370 | 381 | 374 | 371 | |
8 | 445 | 388 | 401 | 396 | 342 | 367 | 443 | 396 | |
9 | 487 | 403 | 410 | 425 | 334 | 361 | 437 | 362 | |
Appendix 2
Mean response times (RTs) per block for both random and repeated sequences and for each condition. Error bars represent 95% confidence intervals.

Appendix 3
Mean slopes for both random and repeated sequences and for each condition. Error bars represent 95% confidence intervals.

Note that paired t-tests on the regression slopes showed steeper regression slopes for repeated compared to random sequences for the three conditions, confirming our analyses that learning takes place in all three conditions.
Condition 1: t(16) = -6.87, p < .001
Condition 2: t(16) = -6.06, p < .001
Condition 3: t(16) = -4.84, p < .001
Moreover, paired t-tests showed that the regression slopes for the random sequences are all positive and significantly larger than zero for Conditions 1 and not significantly different from zero for Condition 2 and 3, indicating that learning did not take place for the random sequences. As to the repeated sequences, analyses show that the slopes for all three conditions are negative and significantly smaller than zero, indicating that learning took place for the repeated sequences.
t | df | p | |
|---|---|---|---|
Random sequences | |||
Condition1 | 2.353 | 16 | <.05 |
Condition2 | 0.705 | 16 | 0.491 |
Condition3 | 1.930 | 16 | 0.072 |
Repeated sequences | |||
Condition1 | -4.703 | 16 | <.001 |
Condition2 | -6.832 | 16 | <.001 |
Condition3 | -3.122 | 16 | <.01 |
Rights and permissions
About this article

Cite this article
Ordonez Magro, L., Fagot, J., Grainger, J. et al. On the role of interference in sequence learning in Guinea baboons (Papio papio). Learn Behav 51, 201–212 (2023). https://doi.org/10.3758/s13420-022-00537-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13420-022-00537-1