
Abstract
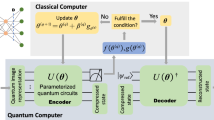
In the model of quantum cloud computing, the server executes a computation on the quantum data provided by the client. In this scenario, it is important to reduce the amount of quantum communication between the client and the server. A possible approach is to transform the desired computation into a compressed version that acts on a smaller number of qubits, thereby reducing the amount of data exchanged between the client and the server. Here we propose quantum autoencoders for quantum gates (QAEGate) as a method for compressing quantum computations. We illustrate it in concrete scenarios of single-round and multi-round communication and validate it through numerical experiments. A bonus of our method is it does not reveal any information about the server’s computation other than the information present in the output.
















Similar content being viewed by others

Availability of data and materials
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Preskill J (2018) Quantum computing in the NISQ era and beyond. Quantum 2:79
Arute F et al (2019) Quantum supremacy using a programmable superconducting processor. Nature 574(7779):505–510
Zhong H-S et al (2020) Quantum computational advantage using photons. Science 370(6523):1460–1463
Broadbent A, Fitzsimons J, Kashefi E (2009) Universal blind quantum computation. In: 2009 50th Annual IEEE Symposium on Foundations of Computer Science. IEEE, pp 517–526
Arrighi P, Salvail L (2006) Blind quantum computation. Int J Quantum Inf 4(05):883–898
Morimae T, Fujii K (2013) Blind quantum computation protocol in which alice only makes measurements. Phys Rev A 87(5):050301
Schmidhuber J (2015) Deep learning in neural networks: An overview. Neural Netw 61:85–117
Romero J, Olson JP, Aspuru-Guzik A (2017) Quantum autoencoders for efficient compression of quantum data. Quantum Sci Technol 2(4):045001
Bottou L (2012) Stochastic gradient descent tricks. In: Neural Networks: Tricks of the Trade. Springer, pp 421–436
Armbrust M, Fox A, Griffith R, Joseph AD, Katz R, Konwinski A, Lee G, Patterson D, Rabkin A, Stoica I et al (2010) A view of cloud computing. Commun ACM 53(4):50–58
Barz S, Kashefi E, Broadbent A, Fitzsimons JF, Zeilinger A, Walther P (2012) Demonstration of blind quantum computing. Science 335(6066):303–308
Yang Y, Chiribella G, Hayashi M (2020) Communication cost of quantum processes. IEEE J Sel Areas Inf Theory 1(2):387–400
Sheng Y-B, Zhou L (2017) Distributed secure quantum machine learning. Sci Bull 62(14):1025–1029
Bondarenko D, Feldmann P (2020) Quantum autoencoders to denoise quantum data. Phys Rev Lett 124(13):130502
Achache T, Horesh L, Smolin J (2020) Denoising quantum states with Quantum Autoencoders–Theory and Applications . arXiv preprint arXiv:2012.14714
Nielsen MA, Chuang IL (1997) Programmable quantum gate arrays. Phys Rev Lett 79(2):321
Yang Y, Renner R, Chiribella G (2020) Optimal universal programming of unitary gates. Phys Rev Lett 125(21):210501
Choi M-D (1975) Completely positive linear maps on complex matrices. Linear Algebra Appl 10(3):285–290
Jamiołkowski A (1972) Linear transformations which preserve trace and positive semidefiniteness of operators. Rep Math Phys 3(4):275–278
Nielsen MA, Chuang I (2002) Quantum computation and quantum information. American Association of Physics Teachers
Chiribella G, D’Ariano GM, Perinotti P (2008) Transforming quantum operations: Quantum supermaps. EPL Europhys Lett 83(3):30004
Chiribella G, D’Ariano GM, Perinotti P (2009) Theoretical framework for quantum networks. Phys Rev A 80(2):022339
Cong I, Choi S, Lukin MD (2019) Quantum convolutional neural networks. Nat Phys 15(12):1273–1278
Farhi E, Goldstone J, Gutmann S (2014) A quantum approximate optimization algorithm. arXiv preprint arXiv:1411.4028
Debnath S, Linke NM, Figgatt C, Landsman KA, Wright K, Monroe C (2016) Demonstration of a small programmable quantum computer with atomic qubits. Nature 536(7614):63–66
Kiefer J, Wolfowitz J et al (1952) Stochastic estimation of the maximum of a regression function. Ann Math Stat 23(3):462–466
McClean JR, Boixo S, Smelyanskiy VN, Babbush R, Neven H (2018) Barren plateaus in quantum neural network training landscapes. Nat Commun 9(1):4812
Broughton M, Verdon G, McCourt T, Martinez AJ, Yoo JH, Isakov SV, Massey P, Halavati R, Niu MY, Zlokapa A et al (2020) Tensorflow quantum: A software framework for quantum machine learning. arXiv preprint arXiv:2003.02989
Baxter RJ (2007) Exactly Solved Models in Statistical Mechanics. Courier Corporation
Williamson DF, Parker RA, Kendrick JS (1989) The box plot: a simple visual method to interpret data. Ann Intern Med 110(11):916–921
Bisio A, Chiribella G, D’Ariano GM, Facchini S, Perinotti P (2010) Optimal quantum learning of a unitary transformation. Phys Rev A 81(3):032324
Mo Y, Chiribella G (2019) Quantum-enhanced learning of rotations about an unknown direction. New J Phys 21(11):113003
Sedlák M, Ziman M (2020) Probabilistic storage and retrieval of qubit phase gates. Phys Rev A 102(3):032618
Bishop LS, Bravyi S, Cross A, Gambetta JM, Smolin J (2017) Quantum volume. Quantum Volume, Technical Report
Moll N, Barkoutsos P, Bishop LS, Chow JM, Cross A, Egger DJ, Filipp S, Fuhrer A, Gambetta JM, Ganzhorn M et al (2018) Quantum optimization using variational algorithms on near-term quantum devices. Quantum Sci Technol 3(3):030503
Allen-Zhu Z (2017) Natasha 2: Faster non-convex optimization than sgd. arXiv preprint arXiv:1708.08694
Sweke R, Wilde F, Meyer JJ, Schuld M, Fährmann PK, Meynard-Piganeau B, Eisert J (2020) Stochastic gradient descent for hybrid quantum-classical optimization. Quantum 4:314
Developers Cirq (2022). Cirq Zenodo. https://doi.org/10.5281/ZENODO.7465577
Mitarai K, Negoro M, Kitagawa M, Fujii K (2018) Quantum circuit learning. Physical Review A 98(3):032309
Funding
This work was supported by funding from the Hong Kong Research Grant Council through grants no. 17300918 and no. 17307520, through the Senior Research Fellowship Scheme SRFS2021-7S02, the Croucher Foundation, and by the John Templeton Foundation through grant 62312, The Quantum Information Structure of Spacetime (qiss.fr). YXW acknowledges funding from the National Natural Science Foundation of China through grants no. 61872318. Research at the Perimeter Institute is supported by the Government of Canada through the Department of Innovation, Science and Economic Development Canada and by the Province of Ontario through the Ministry of Research, Innovation and Science. The opinions expressed in this publication are those of the authors and do not necessarily reflect the views of the John Templeton Foundation.
Author information
Authors and Affiliations
Contributions
Zhu and Li provided the main ideas for the work, while Zhu, Bai, and Wang designed the numerical experiments. Zhu and Chiribella drafted the main manuscript text, and all authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 A. Proof of Theorem 1
According to Allen-Zhu (2017), we have the following lemma about convergence of SGD for nonconvex functions:
Lemma 1
If a function f(x) is \(L_1\)-smooth and we perform SGD update \(x_{t+1}\leftarrow x_t - \eta \nabla f_i(x_t)\) each time for a random \(i\in [n]\), then the convergence rate is \(T = \mathcal {O}(\frac{L_1}{\epsilon ^4})\) for finding \(\mathbb {E}[\Vert \nabla f(x) \Vert ^2]\le \epsilon ^2\).
Therefore, we first discuss the smoothness property of the loss function \(\mathcal {L}(\varvec{\theta })\) in the training of QAEGate model. Note that the first- and second-order Lipschitz smoothness are equivalent to Lipschitz continuity of the first- and second-order derivatives. So we start with a lemma about the Lipschitz continuity of multivariate functions (Sweke et al. 2020).
Lemma 2
Given some function \(f :\textbf{R}^M \rightarrow \textbf{R}\), if all partial derivatives of f are continuous, then for any \(a, b \in \textbf{R}\) the function \(f :[a, b]^M \rightarrow \textbf{R}\) is L-Lipschitz continuous with
Next we prove a more general result about the smoothness of measurement probability of quantum circuits, and then show that \(\mathcal {L}(\varvec{\theta })\) fits into this result.
Lemma 3
Consider a quantum circuit consisting of any number of fixed unitary gates and M variable unitary gates \(U_1(\theta _1),\dots ,U_M(\theta _M)\), where \(U_j(\theta _j):= \textrm{exp}(i\theta _j H_j)\) for some Hermitian operator \(H_j\). Then the probability of any measurement outcome of the output of this circuit is \(L_1\)-smooth and \(L_2\)-second-order smooth with respect to \(\varvec{\theta }=(\theta _1,\dots ,\theta _M)\), where
where \(H_{\textrm{max}}:=\textrm{max}_{j} \Vert H_j\Vert _2\) and \(\Vert \cdot \Vert _2\) is the induced operator norm defined as \(\Vert A\Vert _2:= \sup \frac{\Vert Ax\Vert _2}{\Vert x\Vert _2}\).
Proof
Let \(\vert \psi _0\rangle \) be the initial state of the circuit. Without loss of generality, we assume the variable unitary gates are labeled as \(U_1(\theta _1)\) to \(U_M(\theta _M)\) according to the order they are applied. Then the output of this circuit can be written as \(\vert \psi _{\varvec{\theta }}\rangle := V_M U_M(\theta _M) \dots V_1 U_1(\theta _1) V_0 \vert \psi _0\rangle \), where \(V_1,\dots ,V_M\) denotes the fixed unitary gates. A measurement outcome can be described by a positive operator-valued measure (POVM) element P with the property that P and \(I-P\) are both positive semidefinite, where I is the identity operator of the output. The probability of this outcome is
To study the smoothness of \(f(\varvec{\theta })\), we take the partial derivatives:
These partial derivatives can be bounded with vector and operator norms. For a unitary operator U, \(\Vert U\Vert _2=1\). For the POVM element P, \(\Vert P\Vert _2\le 1\). The second-order partial derivatives can be bounded as:
Similarly, for the third-order partial derivatives,
Therefore, to show that the second- and third-order partial derivatives are bounded, it suffices to show that \(\textrm{max}_{a}\left\| \frac{\partial \vert \psi _{\varvec{\theta }}\rangle }{\partial \theta _a }\right\| _2, \textrm{max}_{a,b}\left\| \frac{\partial ^2 \vert \psi _{\varvec{\theta }}\rangle }{\partial \theta _a \partial \theta _b}\right\| _2\) and \(\textrm{max}_{a,b,c}\left\| \frac{\partial ^3 \vert \psi _{\varvec{\theta }}\rangle }{\partial \theta _a \partial \theta _b \partial \theta _c}\right\| _2\) are all bounded. We observe that \(\frac{\partial U_j(\theta _j)}{\partial j} = \frac{\partial \textrm{exp}(i\theta _j H_j)}{\partial j} = iH_j U_j(\theta _j)\), and we have
With similar derivations, we can obtain \(\textrm{max}_{a,b}\left\| \frac{\partial ^2 \vert \psi _{\varvec{\theta }}\rangle }{\partial \theta _a \partial \theta _b}\right\| _2^2 \le H_{\textrm{max}}^2\) and \(\textrm{max}_{a,b,c}\left\| \frac{\partial ^3 \vert \psi _{\varvec{\theta }}\rangle }{\partial \theta _a \partial \theta _b \partial \theta _c}\right\| _2 \le H_{\textrm{max}}^3\). According to Eqs. (7) and (8), we obtain
Consider \(\frac{\partial f(\varvec{\theta })}{\partial \theta _j}\) as a function of \(\varvec{\theta }\). Since its partial derivatives \(\frac{\partial ^2 f(\varvec{\theta })}{\partial \theta _j \partial \theta _k}\) are bounded by \(4 H_{\textrm{max}}^2\), according to Lemma 2, \(\frac{\partial f(\varvec{\theta })}{\partial \theta _j}\) is \(L_1'\)-continuous with \(L_1'=4 \sqrt{M} H_{\textrm{max}}^2\). Then
and therefore f is \(L_1\)-smooth with \(L_1 = 4 M H_{\textrm{max}}^2\). Similarly, consider \(\frac{\partial ^2 f(\varvec{\theta })}{\partial \theta _j \partial \theta _k}\) as a function of \(\varvec{\theta }\). Since its partial derivatives \(\frac{\partial ^3 f(\varvec{\theta })}{\partial \theta _j \partial \theta _k \partial \theta _l}\) are bounded by \(8 H_{\textrm{max}}^3\), according to Lemma 2, \(\frac{\partial ^2 f(\varvec{\theta })}{\partial \theta _j \partial \theta _k}\) is \(L_2'\)-continuous with \(L_2'=8\sqrt{M} H_{\textrm{max}}^3\). Then
and therefore f is \(L_2\)-second-order smooth with \(L_2 = 8 M^{3/2} H_{\textrm{max}}^3\). \(\square \)
Based on above lemma, we obtain the following theorem:
Theorem 3
(Smoothness) The loss function \(\mathcal {L}(\varvec{\theta })\) in the training of QAEGate model is \(L_1\)-smooth and \(L_2\)-second-order smooth.
Proof
Let \(p(\varvec{\theta })\) be the probability of outcome \(\vert +\rangle \) in the SWAP test when the gates are parameterized with \(\varvec{\theta =(\theta _{\textrm{le}},\theta _{\textrm{re}},\theta _{\textrm{ld}},\theta _{\textrm{rd}})}\). Because of \(\mathcal {L}(\varvec{\theta }) = 1-f(\varvec{\theta })\) and \(f(\varvec{\theta }) = 2p(\varvec{\theta })-1\), we just need to discuss the smoothness of \(p(\varvec{\theta })\). Since \(p(\varvec{\theta })\) is the probability of a measurement outcome of a unitary circuit, and in this circuit, every variable gate has the form of \(U_\theta = \textrm{exp}(i\theta H)\), we can apply Lemma 3. Thus, \(p(\varvec{\theta })\) is \(L_1\)-smooth and \(L_2\)-second-order smooth where \(L_1 = 4MH_{\textrm{max}}^2, L_2 = 8M^{3/2}H_{\textrm{max}}^3\) and M is the number of variable gates in the circuit. To prove Theorem 3, we only need to show that \(H_{\textrm{max}}\) is bounded.
The variable gates in our circuit only includes the following single- and two-qubit gates:
Therefore, \(H_{\textrm{max}} = \textrm{max}\{\Vert \sigma _x\Vert _2,\Vert \sigma _y\Vert _2,\Vert \sigma _z\Vert _2, \Vert \sigma _x\otimes \sigma _x\Vert _2, \Vert \sigma _y\otimes \sigma _y\Vert _2,\Vert \sigma _z\otimes \sigma _z\Vert _2\} = 1\). \(\square \)
Proof
(Proof of Theorem 1) Based on Theorem 3, we have proved that \(\mathcal {L}(\varvec{\theta })\) is \(L_1\)-smooth, where \(L_1 = 4M\). In our implementation, there is only one variable for each variable unitary gate, so \(M=\dim {\varvec{\theta }} = \mathcal {O}(n^2)\) here. Then we can apply Lemma 1 and obtain that the convergence rate is \(T=\mathcal {O}(\frac{n^2}{\epsilon ^4})\) for finding \(\mathbb {E}[\Vert \nabla _{\varvec{\theta }} \mathcal {L}(\varvec{\theta }) \Vert ^2]\le \epsilon ^2\). In order to estimate the gradients, we have to compute the loss function for \(\mathcal {O}(\dim {\varvec{\theta }}) = \mathcal {O}(n^2)\) times. The total time complexity of the algorithm is \(\mathcal {O}(\frac{n^4}{\epsilon ^4})\). \(\square \)
1.2 B. Details of numerical experiments
Data generation
For each class of gates U(t) we considered in different scenarios, we randomly generate 60 different \(U(t_i), t_i \in [0,2]\) and split them into the training set and the test set with ratio 50 : 10.
Hyperparameters
We set the learning rate \(\eta \) as 0.005, the maximum number of iterations K as 150 and the threshold \(\delta \) as 0.999 in all experiments.
Impelementation details
We implement our proposed model QAEGate based on Tensorflow Quantum (Broughton et al. 2020). The parameterized quantum circuits are constructed by the tools provided in Cirq (2022) and the gradients are estimated by the differentiators based on parameter shift rule (Mitarai et al. 2018).
Training details
We employed stochastic gradient descent to train all the models in our experiments, using a single GPU. The training time for all the experiments presented in this paper is less than one hour.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhu, Y., Bai, G., Wang, Y. et al. Quantum autoencoders for communication-efficient cloud computing. Quantum Mach. Intell. 5, 27 (2023). https://doi.org/10.1007/s42484-023-00112-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42484-023-00112-5