
Abstract
As a written language used for thousands of years, Ancient Chinese has some special characteristics like complex semantics as polysemy and the one-to-many alignment with Modern Chinese. Thus it may be translated in a large number of fully different but equally correct ways. In the absence of multiple references, reference-dependent evaluations like Bilingual Evaluation Understudy (BLEU) cannot identify potentially correct translation results. The explore on automatic evaluation of Ancient-Modern Chinese Translation is completely lacking. In this paper, we proposed an automatic evaluation metric for Ancient-Modern Chinese Translation called DTE (Dual-based Translation Evaluation), which can be used to evaluate one-to-many alignment in the absence of multiple references. When using DTE to evaluate, we found that the proper nouns often could not be correctly translated. Hence, we designed a new word segmentation method to improve the translation of proper nouns without increasing the size of the model vocabulary. Experiments show that DTE outperforms several general evaluations in terms of similarity to the evaluation of human experts. Meanwhile, the new word segmentation method promotes the Ancient-Modern Chinese translation models perform better on proper nouns’ translation, and get higher scores on both BLEU and DTE.







Similar content being viewed by others


Notes
In Experiment section, we make length statistics for Ancient-Modern Chinese corpus in Table 1. The average length of the augmented sentences is about a dozen words and the original sentences are shorter than that.
In order to ensure an objective comparison, the English translations of all pictures are literal translation without modification.
‘
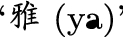
’ (elegance and delicacy) is also an evaluation requirement in this theory. Since this evaluation is very subjective and our task is to translate narrative Ancient Chinese which records facts of Chinese history, we ignored it here.
Two sentences are the ancient input sentence and the retranslation sentence from the symmetrical Modern-Ancient Chinese translation model.
We collected this special dictionary to include people names, place names, and some proper nouns that often appear in ancient China, containing about 6000 words.
Most of the translations for classical poems are subjective, with wide variations between different versions and requiring a lot of additional explanation.
A clause is a sentence that is obtained by dividing a sentence into fragments when meeting commas, semicolons, periods, exclamation marks and question marks.
The code is implemented based on https://github.com/huggingface/transformers.
The weights are determined by where the options are arranged. For example, we have three options for ranking, where the first position has a weight of 3, the second position has a weight of 2, and the third position has a weight of 1.
Similar to the way that converting the human expert ranking results into scores, we ranked the three candidate sentences from high to low in the automatic ranking method. After that, the first one gets 3 points, the second one gets 2 points and the third one gets 1 point, thus converting the ranking results into discrete scores.
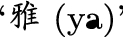
References
Agarwal A, Lavie A (2008) Meteor, m-Bleu and m-Ter: evaluation metrics for high-correlation with human rankings of machine translation output. In: WMT-08, ACL
Bahdanau D, Cho K, Bengio Y (2015) Neural machine translation by jointly learning to align and translate. In: ICLR
Callison-Burch C, Osborne M, Koehn P (2006) Re-evaluation the role of bleu in machine translation research. In: EACL
Callison-Burch C, Fordyce C, Koehn P, Monz C, Schroeder J (2007) (meta-) Evaluation of machine translation. In: WMT-07, ACL
Chang PC, Galley M, Manning CD (2008) Optimizing Chinese word segmentation for machine translation performance. In: WMT-08, ACL
Cheng Y, Tu Z, Meng F, Zhai J, Liu Y (2018) Towards robust neural machine translation. In: ACL
Fu Z, Tan X, Peng N, Zhao D, Yan R (2018) Style transfer in text: exploration and evaluation. In: AAAI
Gomaa WH, Fahmy AA (2013) A survey of text similarity approaches. Int J Comput Appl 68(13):13–18
He D, Xia Y, Qin T, Wang L, Yu N, Liu TY, Ma WY (2016) Dual learning for machine translation. In: NIPS
Joulin A, Grave E, Bojanowski P, Mikolov T (2017) Bag of tricks for efficient text classification. In: EACL
Lample G, Conneau A, Denoyer L, Ranzato M (2018) Unsupervised machine translation using monolingual corpora only. In: ICLR
Lavie A, Agarwal A (2007) Meteor: an automatic metric for mt evaluation with high levels of correlation with human judgments. In: WMT-07, ACL
Li J, Song Y, Zhang H, Chen D, Shi S, Zhao D, Yan R (2018) Generating classical Chinese poems via conditional variational autoencoder and adversarial training. In: EMNLP
Lin CY (2004) Rouge: a package for automatic evaluation of summaries. In: Text Summarization Branches Out
Liu D, Fu J, Qu Q, Lv J (2018) Bfgan: backward and forward generative adversarial networks for lexically constrained sentence generation. ArXiv preprint arXiv:180608097
Liu D, Yang K, Qu Q, Lv J (2019) Ancient-modern Chinese translation with a new large training dataset. In: TALLIP
Liu D, Yang X, He F, Chen Y, Lv J (2019b) mu-forcing: Training variational recurrent autoencoders for text generation. ArXiv preprint arXiv:190510072
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J (2013) Distributed representations of words and phrases and their compositionality. In: NIPS
Mitchell J, Lapata M (2008) Vector-based models of semantic composition. In: ACL
Nakov P, Guzman F, Vogel S (2012) Optimizing for sentence-level bleu+ 1 yields short translations. In: COLING
Papineni K, Roukos S, Ward T, Zhu WJ (2002) Bleu: a method for automatic evaluation of machine translation. In: ACL
Pennington J, Socher R, Manning C (2014) Glove: Global vectors for word representation. In: EMNLP
Scwartz B (2009) In search of wealth and power: Yen Fu and the West. Harvard University Press, Harvard
Shimanaka H, Kajiwara T, Komachi M (2019) Machine translation evaluation with BERT regressor. CoRR abs/1907.12679. arXiv:1907.12679
Snover M, Dorr B, Schwartz R, Micciulla L, Makhoul J (2006) A study of translation edit rate with targeted human annotation. In: AMTA
Su J, Zeng J, Xiong D, Liu Y, Wang M, Xie J (2018) A hierarchy-to-sequence attentional neural machine translation model. In: TASLP
Sundermeyer M, Alkhouli T, Wuebker J, Ney H (2014) Translation modeling with bidirectional recurrent neural networks. In: EMNLP
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: NIPS
Wieting J, Bansal M, Gimpel K, Livescu K (2016) Towards universal paraphrastic sentence embeddings. In: ICLR
Yu L, Zhang W, Wang J, Yu Y (2017) Seqgan: Sequence generative adversarial nets with policy gradient. In: AAAI
Zhang H, Li J, Ji Y, Yue H (2016) Understanding subtitles by character-level sequence-to-sequence learning. IEEE Trans Indus Inf 13(2):616–624
Zhang J, Zong C (2016) Bridging neural machine translation and bilingual dictionaries. ArXiv preprint arXiv:161007272
Zhang T, Kishore V, Wu F, Weinberger KQ, Artzi Y (2020) Bertscore: Evaluating text generation with BERT. In: 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26–30, 2020, OpenReview.net. https://openreview.net/forum?id=SkeHuCVFDr
Zhang WX, Qiu LK, Song ZY, Chen B (2012) Corpus-based quantitative analysis on stylistic difference of chinese synonyms. Chin Lang Learn 3:72–80
Zhang Z, Li W, Sun X (2018) Automatic transferring between ancient chinese and contemporary chinese. ArXiv preprint arXiv:180301557
Acknowledgements
This work is supported by the National Key R&D Program of China Grant No. 2017YFB1002201, the National Natural Science Fund for Distinguished Young Scholar Grant No. 61625204, and partially supported by the Sichuan Science and Technology Major Project Grant No. 2018GZDZX0028.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yang, K., Liu, D., Qu, Q. et al. An automatic evaluation metric for Ancient-Modern Chinese translation. Neural Comput & Applic 33, 3855–3867 (2021). https://doi.org/10.1007/s00521-020-05216-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-05216-8