
Abstract
This research looks at the effects of segment order and segmentation on translation retrieval performance for an experimental Japanese–English translation memory system. We implement a number of both bag-of-words and segment-order-sensitive string comparison methods, and test each over character-based and word-based indexing using n-grams of various orders. To evaluate accuracy, we propose an automatic method which identifies the target-language string(s) which would lead to the optimal translation for a given input, based on analysis of the held-out translation and the current contents of the translation memory. Our results indicate that character-based indexing is superior to word-based indexing, and also that bag-of-words methods are equivalent to segment-order-sensitive methods in terms of accuracy but vastly superior in terms of retrieval speed, suggesting that word segmentation and segment-order sensitivity are unnecessary luxuries for translation retrieval.
Similar content being viewed by others


References
Aramaki E, Kurohashi S, Kashioka H, Tanaka H (2005) Probabilistic model for example-based machine translation. In: Proceedings of the tenth machine translation summit (MT Summit X), Phuket, Thailand, pp 219–226
Backhouse AE (1993) The Japanese language: an introduction. Oxford University Press, Oxford
Baldwin T (2001a) Low-cost, high-performance translation retrieval: dumber is better. In: Association for Computational Linguistics, 39th annual meeting and 10th conference of the European Chapter, Toulouse, France, pp 18–25
Baldwin T (2001b) Making lexical sense of Japanese–English machine translation: a disambiguation extravaganza. PhD thesis, Tokyo Institute of Technology, Japan
Baldwin T, Tanaka H (2000) The effects of word order and segmentation on translation retrieval performance. In: The 18th international conference on computational linguistics, COLING 2000 in Europe, Saarbrücken, Germany, pp 35–41
Banerjee S, Lavie A (2005) METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In: Intrinsic and extrinsic evaluation measures for machine translation and/or summarization, Proceedings of the ACL-05 Workshop, Ann Arbor, Michigan, pp 65–72
Brown PF, Della Pietra VJ, deSouza PV, Lai JC, Mercer RL (1992) Class-based n-gram models of natural language. Comput Ling 18: 467–479
Carl, M, Way, A (eds) (2003) Recent advances in example-based machine translation. Kluwer Academic, Dordrecht, Netherlands
Chen SF (1993) Aligning sentences in bilingual corpora using lexical information. In: 31st annual meeting of the Association for Computational Linguistics, Columbus, Ohio, pp 9–16
Chen SF, Goodman J (1996) An empirical study of smoothing techniques for language modeling. In: 34th annual meeting of the Association for Computational Linguistics, Santa Cruz, CA, pp 310–318
Culy C, Riehemann SZ (2003) The limits of n-gram translation evaluation metrics. In: MT Summit IX, New Orleans, USA, pp 71–78
Doi T, Yamamoto H, Sumita E (2005) Example-based machine translation using efficient sentence retrieval based on edit-distance. ACM T Asian Lang Info Proc (TALIP) 4: 377–399
Fujii H, Croft WB (1993) A comparison of indexing techniques for Japanese text retrieval. In: Proceedings of 16th international ACM-SIGIR conference on research and development in information retrieval (SIGIR’93), Pittsburgh, PA, pp 237–246
Gale W, Church K (1993) A program for aligning sentences in bilingual corpora. Comput Ling 19: 75–102
Gale W, Church K, Yarowsky D (1992) A method for disambiguating word senses in a large corpus. Comput Hum 26: 415–439
Isahara H (1998) JEIDA’s English–Japanese bilingual corpus project. In: Proceedings of the 1st international conference on language resources and evaluation (LREC’98), Granada, Spain, pp 471–481
Kitamura M [
 ], Yamamoto H [
], Yamamoto H [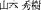 ] (1996)
] (1996) 
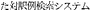 [Translation retrieval system using alignment data from parallel texts]. In:
[Translation retrieval system using alignment data from parallel texts]. In: 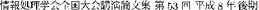 [Proceedings of the 53rd annual meeting of the Information Processing Society of Japan], Osaka, Japan, vol 2, pp 385–386
[Proceedings of the 53rd annual meeting of the Information Processing Society of Japan], Osaka, Japan, vol 2, pp 385–386Kukich K (1992) Techniques for automatically correcting words in text. ACM Comput Surv 24: 377–439
Kurohashi S [
 ], Nagao M [
], Nagao M [ ] (1998)
] (1998)  JUMAN 3.5 [Japanese morphological analysis system JUMAN version 3.5]. Technical report, Kyoto University, Japan
JUMAN 3.5 [Japanese morphological analysis system JUMAN version 3.5]. Technical report, Kyoto University, JapanLanglais P, Simard M (2002) Merging example-based and statistical machine translation. In: Richardson SD (ed) Machine translation: from research to real users: 5th conference of the Association for Machine Translation in the Americas, AMTA 2002, Tiburon, CA, October 2002, Berlin, Springer Verlag, PP 104–113
Manning CD, Schütze H (1999) Foundations of statistical natural language processing. MIT Press, Cambridge, MA
Marcu D (2001) Towards a unified approach to memory- and statistical-based machine translation. In: ACL-EACL-2001: 39th annual meeting and 10th conference of the European chapter, Toulouse, France, pp 386–393
Masek W, Paterson M (1980) A faster algorithm computing string edit distances. J Comput Syst Sci 20: 18–31
Matsumoto Y, Kitauchi A, Yamashita T, Hirano Y (1999) Japanese morphological analysis system ChaSen version 2.0 manual. Technical report, NAIST-IS-TR99009, Nara Institute of Science and Technology, Japan
Moffat A, Zobel J (1996) Self-indexing inverted files for fast text retrieval. ACM T Inform Syst 14: 349–379
Nakamura N [
 ] (1989)
] (1989)  [Translation support system using example-based retrieval]. In:
[Translation support system using example-based retrieval]. In:  [Proceedings of the 38th annual meeting of the Information Processing Society of Japan], vol 1, pp 357–358
[Proceedings of the 38th annual meeting of the Information Processing Society of Japan], vol 1, pp 357–358Nagao M, Mori S (1994) A new method of n-gram statistics for large number of n and automatic extraction of words and phrases from large text data of Japanese. In: COLING 94, The 15th international conference on computational linguistics, Kyoto, Japan, pp 611–615
Nirenburg S, Domashnev C, Grannes DJ (1993) Two approaches to matching in example-based machine translation. In: TMI-93: The fifth international conference on theoretical and methodological issues in machine translation, Kyoto, Japan, pp 47–57
Och FJ, Ney H (2003) A systematic comparison of various statistical alignment models. Comput Ling 29: 19–51
Papineni K, Roukos S, Ward T, Zhu W-J (2002) BLEU: A method for automatic evaluation of machine translation. In: 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, pp 311–318
Planas E, Furuse O (1999) Formalizing translation memories. In: Proceedings of the seventh machine translation summit (MT Summit VII), Singapore, pp 331–339
Planas E, Furuse O (2000) Multi-level similar segment matching algorithm for translation memories and example-based machine translation. In: The 18th international conference on computational linguistics, COLING 2000 in Europe, Saarbrücken, Germany, pp 621–627
Planas E, Furuse O (2003) Formalizing translation memory. In: Carl and Way (2003), pp 157–188
Salton G (1971) The SMART retrieval system: experiments in automatic document processing. Englewood Cliffs, NJ: Prentice-Hall
Sato S (1992) CTM: An example-based translation aid system. In: Coling-92: Proceedings of the fourteenth [sic] international conference on computational linguistics, Nantes, pp 1259–1263
Sato S (1994) Example-based translation and its MIMD implementation. In: Kitano H, Hendler J (eds) Massively parallel artificial intelligence. MIT Press, Cambridge, MA, pp 171–201
Sato S, Kawase T (1994) A high-speed best match retrieval method for Japanese text. Technical report IS-RR-94-9I, Japan Advanced Institute of Science and Technology, Ishikawa, Japan
Sato S, Nagao M (1990) Toward memory-based translation. In: Coling-90: Papers presented to the 13th international conference on computational linguistics, vol 3, Helsinki, pp 247–252
Somers H (2003a) Recent advances in example-based machine translation. In: Carl and Way (2003), pp 3–57
Somers H (2003b) Translation memory systems. In: Somers H (ed) Computers and translation: a translator’s guide, John Benjamins, Amsterdam/Philadelphia, pp 31–47
Sumita E [
 ] Tsutsumi Y [
] Tsutsumi Y [ ] (1991)
] (1991)  [A practical method of retrieving similar examples for translation aid].
[A practical method of retrieving similar examples for translation aid].  [Transactions of the Institute of Electronics, Information and Communication Engineers] J74-D-II(10), 1437–1447
[Transactions of the Institute of Electronics, Information and Communication Engineers] J74-D-II(10), 1437–1447Tanaka H [
 ] (1997)
] (1997)  [An efficient way of gauging similarity between long Japanese expressions]. In:
[An efficient way of gauging similarity between long Japanese expressions]. In:  [Information processing society of Japan: natural language processing study group report], 97.85, pp 69–74
[Information processing society of Japan: natural language processing study group report], 97.85, pp 69–74Trujillo A (1999) Translation engines: techniques for machine translation. Springer Verlag, London
Veale T, Way A (1997) Gaijin: a bootstrapping, template-driven approach to example-based MT. In: Proceedings of RANLP 1997, Recent advances in natural language processing, Tzigov Chark, Bulgaria, pp 239–244
Véronis, J (eds) (2000) Parallel text processing: alignment and use of translation corpora. Kluwer Academic, Dordrecht, Netherlands
Wagner RA, Fischer MJ (1974) The string-to-string correction problem. JACM 21: 168–173
Wu D (1994) Aligning parallel English–Chinese text statistically with lexical criteria. In: 32nd annual meeting of the Association for Computational Linguistics, Las Cruces, NM, pp 80–87
Zhai C, Lafferty J (2004) A study of smoothing methods for language models applied to information retrieval. ACM T Inform Syst 22: 179–214
 ], Yamamoto H [
], Yamamoto H [ ] (1996)
] (1996) 
 [Translation retrieval system using alignment data from parallel texts]. In:
[Translation retrieval system using alignment data from parallel texts]. In:  [Proceedings of the 53rd annual meeting of the Information Processing Society of Japan], Osaka, Japan, vol 2, pp 385–386
[Proceedings of the 53rd annual meeting of the Information Processing Society of Japan], Osaka, Japan, vol 2, pp 385–386 ], Nagao M [
], Nagao M [ ] (1998)
] (1998)  JUMAN 3.5 [Japanese morphological analysis system
JUMAN 3.5 [Japanese morphological analysis system  ] (1989)
] (1989)  [Translation support system using example-based retrieval]. In:
[Translation support system using example-based retrieval]. In:  [Proceedings of the 38th annual meeting of the Information Processing Society of Japan], vol 1, pp 357–358
[Proceedings of the 38th annual meeting of the Information Processing Society of Japan], vol 1, pp 357–358 ] Tsutsumi Y [
] Tsutsumi Y [ ] (1991)
] (1991)  [A practical method of retrieving similar examples for translation aid].
[A practical method of retrieving similar examples for translation aid].  [Transactions of the Institute of Electronics, Information and Communication Engineers] J74-D-II(10), 1437–1447
[Transactions of the Institute of Electronics, Information and Communication Engineers] J74-D-II(10), 1437–1447 ] (1997)
] (1997)  [An efficient way of gauging similarity between long Japanese expressions]. In:
[An efficient way of gauging similarity between long Japanese expressions]. In:  [Information processing society of Japan: natural language processing study group report], 97.85, pp 69–74
[Information processing society of Japan: natural language processing study group report], 97.85, pp 69–74Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Baldwin, T. The hare and the tortoise: speed and accuracy in translation retrieval. Machine Translation 23, 195–240 (2009). https://doi.org/10.1007/s10590-009-9064-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10590-009-9064-7