
Abstract
Automatic estimation of skinning transformations is a popular way to deform a single reference shape into a new pose by providing a small number of control parameters. We generalize this approach by efficiently enabling the use of multiple exemplar shapes. Using a small set of representative natural poses, we propose to express an unseen appearance by a low-dimensional linear subspace, specified by a redundant dictionary of weighted vertex positions. Minimizing a nonlinear functional that regulates the example manifold, the suggested approach supports local-rigid deformations of articulated objects, as well as nearly isometric embeddings of smooth shapes. A real-time nonrigid deformation system is demonstrated, and a shape completion and partial registration framework is introduced. These applications can recover a target pose and implicit inverse kinematics from a small number of examples and just a few vertex positions. The resulting reconstruction is more accurate compared to alternative reduced deformable models.
Similar content being viewed by others

1 Introduction
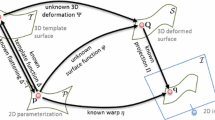
The construction of an efficient automatic procedure that deforms one shape into another in a natural manner is a fundamental and well-studied challenge in computer graphics. Professional animators design deformable models for manually editing facial expressions, controlling postures and muscles of shapes, and creating sequences of gestures and motions of animated objects. Such models also play a key role in the field of shape analysis. For example, elastic surface registration techniques try to iteratively warp given shapes so as to establish an optimal alignment between them (Fig. 1).
A major challenge in automatic shape deformation is preserving the expressiveness of the model while reducing its complexity. This can be accomplished by exploiting the potential redundancy in natural motions. For instance, in nonrigid articulated objects as hands, the bending of a single finger mainly influences the movement of nearby skin. The stiffness of the limbs restricts them to move freely and therefore the deformation of a shape as a whole can often be well approximated as a blend of a small number of affine transformations. One such skeletal deformation technique, the Linear Blend Skinning (LBS) [33], has been widely adopted by the gaming and the film industries due to its simplicity and efficiency.
More recently, Jacobson et al. [19] suggested to deform a single shape by looking for transformations that minimize the nonlinear As-Rigid-As-Possible (ARAP) energy [2, 40]. This energy penalizes deviations from rigidity of the underlying structural skeleton. The optimization process alternates between finding the minimal affine transformations and projecting them onto the group of rigid ones. The algorithm converges after a few iterations and provides realistic deformations with a low computational effort. The method was designed for modifying a single reference shape. As such, it does not effectively incorporate the nature of plausible nonrigid deformations that can be well captured by a few examples. Therefore, this method requires a manually tailored pre-computation of biharmonically smooth blending functions, and relies on an initial pose of the shape that is usually selected as the previous frame in the motion sequence.
In many situations, while analyzing or synthesizing shapes, neither manual input nor the temporal state of the shape at the previous frame is available. In these circumstances, obtaining a natural initial pose for the nonlinear optimization procedure becomes a challenge. Nevertheless, in many of these events, static poses of the same shape might be available, such as in [6] where several human bodies in various postures were captured and reconstructed using range scanners. In this paper, we present an efficient generalization of the LBS model for the case where multiple exemplar shapes are available. To that end, the proposed framework uses the reference shapes to infer an expressive yet low-dimensional model, which is computationally efficient and produces natural looking poses. The proposed method constructs a dictionary that contains prototype signal atoms of weighted vertex coordinates that effectively span the space of deformations represented by the exemplar shapes. We refer to [14], for applications of overcomplete dictionaries for sparse and redundant data representations in other domains.

A shape (right) obtained by the fast blended transformations method using ten positional constraints (red dots) and four reference shapes (left). The original shape is shown in brown (middle) (Color figure online)
The proposed algorithm is mainly motivated by the nonrigid 3D partial registration problem. This problem is considered a key challenge in the field of shape analysis. One of the most efficient approaches to solve this challenge is using deformation-driven correspondences [49]. A good deformation method for this purpose should efficiently produce plausible deformations that fit some known constraints. In our setting, we use several example shapes and a few known vertex positions. Although some example-based methods produce excellent deformations, in this context of partial registration, they usually carry three major drawbacks. First, most of these methods have high complexity. Second, they depend strongly on a good initial shape alignment. Third, they require many examples for constructing a model which plausibly captures various poses. The proposed method tries to overcome these difficulties by using a redundant dictionary that spans a linear deformation subspace. The advantages of using a linear subspace are evident. Acceleration in this case is well established using the ARAP energy functional formulated in a low-dimensional subspace. Additionally, well-known regularization techniques, such as \(L_1\) and \(L_2\) penalty terms, can easily be deployed in conjunction with the linear model to find a robust sparse representation for the initial shape alignment. Moreover, the simplicity and flexibility of using the linear representation enables the proposed algorithm to refine this initial shape deformation by gradually expanding the deformation space while simultaneously introducing more accurate model constraints.
The key contributions of the proposed approach include the following features.
-
Given a few reference shapes, we construct a redundant, yet compact, dictionary of weighted positional atoms that spans a rich space of deformations. A new deformation is represented as a linear combination of these atom signals.
-
Stable transformations are established by using sparse modeling over a limited subspace of deformations. The suggested framework ensures the use of only a few dictionary atoms relating a few given poses to a target one.
-
The As-Rigid-As-Possible energy is reformulated to support multiple reference shapes and automatic global scale detection. We introduce the average ARAP energy and the minimal ARAP energy. While the former is used for initialization of the deformation according to the constraints, the later is used for refining the deformation.
-
Smooth deformations are realized by an additional biharmonic energy term that is computationally efficient to minimize when the skinning weights are set to be the eigenfunctions of the Laplace–Beltrami operator.
To demonstrate the fast blended transformations approach, animation sequences were generated given just a few reference shapes and a handful of point constraints that define each target frame. Quantitative evaluation indicates that the advantages of the proposed approach are fully realized when plugged into a shape completion and registration application that achieves low correspondence errors and deformation distortions.
2 Related Efforts
Example-based deformation techniques attempt to establish a compact representation of shape deformations while trying to satisfy desirable properties. Forming these representations generally requires the processing of sets of poses, expressions, or identities of the same class of shapes. To fulfill this task, various methods have been proposed. Roughly speaking, they all share the following taxonomy.
Displacement field interpolation This technique computes the pointwise difference between each example shape and a reference one at a resting pose, see for example [26, 29, 39]. More recent methods include statistical [15] and rotational regressions [45].
Deformation gradient These methods interpolate the example poses using the gradient fields of the coordinate functions and construct the deformed surface by solving a Poisson equation. In [42, 48] the deformation is estimated for each triangle of the given mesh. Example-based deformation gradients and its variants [7, 17, 25, 34, 38, 50], like the Green strain tensor, are also used for static or dynamic simulation of elastic materials. For lowering the computational cost, Der et al. [12] proposed to cluster triangles that are subject to a similar rigid rotation with respect to a single reference shape. It allowed reformulating the problem in terms of transformations of a representative proxy point for each group of vertices.
Edge lengths and dihedral angles interpolation Inspired by discrete shells [18], local properties were used for mesh interpolation [47], that naturally fits with the discrete shell energy for combined physics-based and example-driven mesh deformations [16].
Transformation blending This approach describes the deformation by a set of affine transformations that are blended together to represent the deformed shape. In this case, the example shapes are used to find the skinning weights as well as the transformations by using nonlinear optimization algorithms [21, 23, 27, 28].
Linear subspace Similar in its spirit to the proposed approach is Tycowicz et al. [44]. Their method computes an example-based reduced linear model for representing the high dimensional shape space using deformation energy derivatives and Krylov sequences. However, their framework and reduced linear subspace are specifically designed and restricted to the nonlinear shape interpolation problem and are not applicable to the problem of partial shape registration. First, their energy functional is predetermined by the interpolation weights and does not naturally integrate additional user-specified constraints. Second, unlike our method that use a redundant dictionary and an \(L_1\) penalty, their method does not use a sparsity promoting model and therefore it is very hard to initialize their deformation for applications such as partial shape registration and shape completion.
The fast blended transformations (FBT) method is affiliated with the class of transformation blending inspired by [19, 46]. The deformation is performed by minimizing a nonlinear energy functional over the linear subspace of skinning transformations. Unlike previous efforts, we suggest to simultaneously blend affine transformations of several given poses of the same subject. The proposed framework allows us to learn the example manifold without estimating the explicit connections between the reference shapes. With these reference shapes, we construct an overcomplete dictionary that spans the space of allowed deformations up to a small tolerance. The nonlinear energy functional guides the transformations to achieve a physically plausible deformation. Projecting a small set of constraints to the manifold of the examples, which is assumed to be of low dimensionality, we obtain an efficient and accurate blending procedure for real-time animation and for the partial shape registration task.
3 Notations and Problem Formulation
3.1 Linear Blend Skinning
Here, we follow the blend skinning model as described by Jacobson et al. in [19]. Let \(\mathbf{v}_1, \dots ,\mathbf{v}_n \in \mathbb {R}^{d}\) (\(d = 3\)) be the vertex positions of the input reference mesh \(\mathcal {M}\) with f triangles and n vertices. Denote the deformed vertex positions of a new target mesh \(\tilde{\mathcal {M}}\) by \(\tilde{\mathbf{v}}_1, \dots , \tilde{\mathbf{v}}_n \in \mathbb {R}^{d}\). The target vertex positions relate to the given reference vertices through m affine transformation matrices \(\mathbf{M}_j \in \mathbb {R}^{d \times (d+1)}\), \(j=\{1, \dots , m\}\) and real-valued skinning weight functions \(w_j\), that measure the influence of each affine transformation on each point of the shape. For a discrete mesh, we denote \(w_j(\mathbf{v}_i)\) by \(w_{j,i}\), and readily have
Equation (1) can be rewritten in a matrix form as
where \(\tilde{\mathbf{V}} \in \mathbb {R}^{n \times d}\) is the matrix whose rows are the positions of the target vertices, and the matrices \({\mathbf{T}}_{\mathrm{LBS}} \in \mathbb {R}^{ (d+1)m \times d}\) and \({\mathbf{D}}_{\mathrm{LBS}} \in \mathbb {R}^{n \times (d+1)m}\) are created by stacking the skinning parameters in the following fashion
3.2 Fast Automatic Skinning Transformations
The most general form of representing the position of a new target vertex by a linear transformation of some dictionary (such as the linear blend skinning formulation) can be expressed by
where \(\mathbf{D} \in \mathbb {R}^{n \times b}\) is a dictionary of size b (in case of standard linear blend skinning \(b=(d+1)m\)), and \(\mathbf{T} \in \mathbb {R}^{b \times d}\) is a matrix of unknown coefficients that represents the vertex positions in terms of the dictionary.
Jacobson et al. [19] introduced a method for automatically finding the skinning transformations \(\mathbf{T}\) by minimizing the ARAP energy [11, 32, 40] between the reference shape \(\mathcal {M}\) and the target one \(\tilde{\mathcal {M}}\). Let \(\tilde{V} \in \mathbb {R}^{n \times d}\) be the matrix whose rows are the positions of the reference vertices, and let \(\mathbf{R}_1, \mathbf{R}_2, \dots ,\mathbf{R}_r \in \text {SO}(d)\) and \(\mathcal {E}_1, \mathcal {E}_2, \dots , \mathcal {E}_r\) be r local rotations and their corresponding edge sets, respectively. The ARAP energy, which measures local deviation from rigidity, can be expressed as
where \(c_{ijk} \in \mathbb {R}\) are the cotangent weighting coefficients [36]. As indicated in [19], it is unnecessary to estimate the local rotation for each edge separately since vertices undergoing similar deformations can be clustered together into a small number of rotation clusters.
The ARAP energy can be expressed in a simple matrix form. Denote \(\mathbf{A}_k \in \mathbb {R}^{n\times |\mathcal {E}_k|}\) as the directed incidence matrix corresponding to edges \(\mathcal {E}_k\), and let \(\mathbf{C}_k \in \mathcal {R}^{|\mathcal {E}_k| \times |\mathcal {E}_k|}\) be a diagonal matrix with weights \(c_{ijk}\). Then, the ARAP energy can be written in matrix form as
where \(\mathbf{R} = (\mathbf{R}_1,\dots ,\mathbf{R}_r)\), \(\mathbf{K} \in {\mathbb R}^{dr \times n}\) stacks the matrices \(\mathbf{V}^{\mathrm {T}} \mathbf{A}_k \mathbf{C}_k \mathbf{A}_k^{\mathrm {T}}\), and \(\mathbf{L} \in \mathbb {R}^{n \times n}\) is the cotangent-weights Laplacian up to a constant scale factor. Plugging in the linear blend skinning formula \(\tilde{\mathbf{V}} = \mathbf{D}{} \mathbf{T}\), we obtain
where \({\tilde{\mathbf{L}}} = {\mathbf{D}}^{\mathrm {T}}{\mathbf{L}}{\mathbf{D}}\) and \({\tilde{\mathbf{K}}} = {\mathbf{K}}{\mathbf{D}}\). For more details about the above derivation, we refer the reader to [19].
4 Example-Based Blended Transformations
Overview We now extend the framework described in the previous section for the case where multiple poses of the same shape are available. We begin by expressing the deformed shape as a combination of atoms from a dictionary that is constructed from the linear blend skinning matrices of the given examples. Then, we provide the details of various energy terms to be minimized with respect to the unknown transformations \(\mathbf{T}\) using the proposed model. Next, we describe the nonlinear optimization process and its initialization and conclude by discussing optional extensions that can be incorporated into the algorithm.
4.1 Dictionary Construction
Suppose we are given q reference meshes \(\mathcal {M}_1, \mathcal {M}_2, \dots , \mathcal {M}_q\). Let \({\mathbf{v}^{\ell }_1}, \dots , \mathbf{v}^{\ell }_n \in \mathbb {R}^{d}\) be the positions of vertices belonging to the reference mesh \( \mathcal {M}_\ell \), \(\ell = 1, \dots , q\), and let \(\mathbf{V}_1, \mathbf{V}_2, \dots , \mathbf{V}_q \in \mathbb {R}^{n \times d}\) be the matrices whose rows denote the positions of the corresponding vertices. We are also given some h linear constraints represented by the matrix \(\mathbf{H} \in \mathbb {R}^{h \times n}\), such that \(\mathbf{H}\tilde{\mathbf{V}} \approx \mathbf{Y}\), where \(\mathbf{Y} \in \mathbb {R}^{h \times d}\) is the value of these constraints for the target shape. We can define the linear constraints to be simply the coordinates of points on the mesh or use more refined measures such as the Laplacian coordinates [1, 31], or a weighted average of some vertex positions, to constrain our nonrigid blended shape deformation. Using this setup, we are interested in finding the positions of the target vertices as a result of a smooth transformation of the input meshes such that it approximately preserves local rigidity and satisfies the linear constraints up to a small error.
Example-based dictionary Given m real-valued weight functions \(w_j\), \(j=1 ,\dots , m\), we propose the example-based representation of the positions of the target vertices to be a combination of the linear blend skinning deformations of each given reference mesh
where
We can explicitly write the new vertex positions as
where \({\hat{\mathbf{M}}}^\ell _j \in \mathbb {R}^{d \times d}\) and \({\bar{\mathbf{M}}}^\ell _j \in \mathbb {R}^{d \times 1}\) are sub-matrices of \(\mathbf{M}_j^\ell \), such that \(\mathbf{M}_j^\ell = \begin{pmatrix} {\hat{\mathbf{M}}}^\ell _j ,&{\bar{\mathbf{M}}}^\ell _j\end{pmatrix}\). This formula can be equivalently expressed in the standard matrix form by
where \(\mathbf{D} \in \mathbb {R}^{n \times (1+qd)m}\) is the proposed dictionary of size \(b = (1+qd)m\), that multiplies the examples’ vertex positions \(\mathbf{v}^{\ell }_i\) with the vertex weights \(w_j(v_i)\), and \(\mathbf{T} \in \mathbb {R}^{(1+qd)m \times d}\) stacks the matrices \({\hat{\mathbf{M}}}^m_j\) and \({\bar{\mathbf{M}}}^m_j\) in the following way
where
and
Weighting functions There are many ways to choose weighting functions. One is to consider the weights of bones like in the standard linear blend skinning model. In that case, we name the constructed dictionary as the example-based skeleton dictionary. When there is no significant underlying skeletal structure, we suggest to use the first m eigenfunctions of the Laplace–Beltrami operator (LBO) [8, 13]. This choice of a dictionary is useful, for example, when handling facial expressions, for analyzing internal organs in volumetric medical imaging applications, or for deforming nonrigid objects such as an octopus. The eigendecomposition of the LBO consists of non-negative eigenvalues \(0 = \lambda _0< \lambda _1< \cdots< \lambda _i < \cdots \), with corresponding eigenfunctions \(\Phi \equiv \{\phi _0, \phi _1, \ldots , \phi _i, \ldots \}\), that can be considered as an orthonormal basis. We refer to this dictionary as the example-based LBO dictionary.
4.2 Nonlinear Energy Terms
Linear constraints The energy of the h linear constraints can be calculated by
where \(\mathbf{X} = \mathbf{H} \mathbf{D}\).
Smoothness energy Let \(\mathbf{v}_{i,k},\, k \in \{1,\dots , d\}\) be the \(k{\text{ th }}\) coordinate of the vertex position \(\mathbf{v}_i\). Notice from Eq. (4), that the amount of influence of \(\mathbf{v}^{\ell }_{i,k}\) on \(\tilde{\mathbf{v}}_{i,\tilde{k}}\) is some linear combination of \(w_{j}(v_i)\), \(j=1 ,\dots , m\). Following the same reasoning as in [20], we search for a smooth variation of this influence, for example, one that minimizes the Laplacian energy \( \dfrac{1}{2} \int _\mathcal{M} \Delta (\cdot ) ^2 da\) of this linear combination, where da is an area element on the surface \(\mathcal{M}\) of our shape. For the special case where the weights are the LBO eigenfunctions, the sum of all smoothness energy terms can be expressed as
where \({\varvec{\Lambda }}\) is a diagonal matrix. The values of the diagonal are the squares of the eigenvalues of the respective eigenfunctions. Thus, in this case, the smoothness energy amounts to a simple quadratic regularization term. Note that when the weighting functions are chosen in a different way, the smoothness energy expression is a bit more involved.
Scaling In some applications, there is a scale difference between the example shapes and the linear constraints. To compensate for such a discrepancy, we introduce a scaling factor \(\alpha \) into the ARAP energy. It reflects the ratio between the reference shape and the deformed one, in the following manner,
Hence, the ARAP energy with the global scale factor reads
Average ARAP energy This example-based energy functional is defined by taking the average between all as-rigid-as-possible energies, namely,
with the additional linear constraints and the smoothness energies,
where \(\beta _{\text {lc}}\) and \(\beta _{\text {sm}}\) are some tuning parameters that control the importance of the linear constraints and the smoothness term. We can simplify this expression, plugging in Eqs. (6), (5) and (8)
Minimal ARAP energy The minimal ARAP energy is equal to the minimal ARAP energy between the deformed mesh and each of the input meshes separately,
where
This can be expressed as
Discussion Example-based ARAP energy can be defined by assigning positive weights to each of the reference shapes (such that the weights sum to one) [44] and minimize the weighted sum of the ARAP energies over all admissible deformations and weights. A variation of this approach would be to calculate the weighted average across the shapes with smoothly varying weights per edge. In both cases, the optimization problem is deeply nonlinear; it is difficult to solve and has a high computational cost.
Our approach is to add a sparsity constraint on the weighted sum such that the weights are all zeros except for the weight of a single reference shape which is equal to 1. For solving this example-based energy, we break it down to two consecutive optimization problems. Initially, we lack any knowledge for which reference shape the weight should be 1, so we start by setting the example-based ARAP energy with fixed uniform weights, omitting the sparsity constraint. Only after we find the deformation that minimizes this average energy, we insert the sparsity constraint.
As shape deformation is an ill-posed problem, various articulations can satisfy the pointwise constraints. In the case where the positional constraints are far from any of the examples, the average ARAP energy penalizes deviation from all of the examples equally. Thus, it produces an adequate initial estimation of a desired deformation. However, given a prior knowledge about the shape articulation state, such as a previous frame, the average ARAP energy might favor a configuration of skeletal limbs which is far from the reference one and perhaps less expressive. As noted above, in our implementation, we use the average ARAP energy for initialization and then switch to minimizing the minimal ARAP energy.
4.3 Optimization
To minimize the energy \(E_{\text {total}}(\tilde{\mathbf{V}})\) and find the local rotations \(\mathbf{R}_\ell ,\,\ell =1,\dots , q\), the global scale factor \(\alpha \) and the transformations \(\mathbf{T}\), we follow the local-global approach of [40] with an additional step to find the global scale \(\alpha \). First, we fix \(\mathbf{T}\) and \(\alpha \) and solve for \(\mathbf{R}_\ell \) (local step). Then, we find \(\alpha \) by fixing \(\mathbf{T}\), \(\mathbf{R}_\ell \) (scale step). Finally, we fix \(\mathbf{R}_\ell \) and \(\alpha \), and solve for \(\mathbf{T}\) (global step).
Local step For fixed \(\alpha \) and \(\mathbf{T}\), maximizing \(\hbox {tr}(\mathbf{R}_\ell \mathbf{S}_\ell )\), \(\ell =1,\dots , q\), where \(\mathbf{S}_\ell = {\tilde{\mathbf{K}}}_\ell \mathbf{T}\) is constant, amounts to maximizing \(\hbox {tr}{(\mathbf{R}_{\ell ,k} \mathbf{S}_{\ell ,k})}\), \(k=1,\dots , r\), which is obtained by taking \(\mathbf{R}_{\ell ,k} = \varvec{\Psi }^{\mathrm {T}}_{\ell ,k} \varvec{\Phi }^{\mathrm {T}}_{\ell ,k}\), where
is given by the singular value decomposition of \( \mathbf{S}_{\ell ,k}\).
Scale step For fixed \(\mathbf{T}\) and \(\mathbf{R}_\ell \), \(\ell =1,\dots , q\), we can differentiate by \(\alpha \)
Setting the derivative to zero, we get
Global step For fixed \(\alpha \) and \(\mathbf{R}_\ell \), \(\ell =1,\dots , q\), we differentiate \( E_{\text {total}}\)
Setting these derivatives to zero, we obtain
Let us define \(\varvec{\Gamma } = ({\tilde{\mathbf{L}}}+\beta _{\text {lc}}{} \mathbf{X}^{\mathrm {T}} \mathbf{X} + \beta _{\text {sm}} {\varvec{\Lambda }})\). Then, we can solve for \(\mathbf{T}\) by precomputing the Cholesky factorization of \(\varvec{\Gamma }\)
As for optimizing the minimal ARAP energy \(E_{\text {mn}}(\tilde{\mathbf{V}})\), in the local step we find each set of rotations \(\mathbf{R}_\ell \) by maximizing \(\hbox {tr}(\mathbf{R}_\ell \mathbf{S}_\ell )\), where \(\mathbf{S}_\ell = \tilde{\mathbf{K}}_\ell \mathbf{T}_\ell \). We then find the global scale factor relative to each reference shape
In the global step, we calculate the respective blended transformations \(\mathbf{T}_\ell \), by
Then, we calculate the minimal energy \(E_\ell (\tilde{\mathbf{V}}, \mathbf{T}_\ell )\), \(\ell = 1,\dots ,q\) of Eq. (13). Finally, we minimize Eq. (12) by comparing all values of \(E_\ell \) and selecting the transformation \(\mathbf{T}_\ell \) that gives the minimal value.
The pseudo-code shown in Algorithms 1 and 2 describes the optimization procedures for finding the blended transformations using the average ARAP energy and the minimal ARAP energy, respectively.


Initial transformations For common situations where we cannot rely on an initial pose of the shape, we face a difficult challenge, since optimizing simultaneously for both the rotation matrices and the transformations is a non-convex optimization problem that is hard to solve. The approach we take is to apply the first global step without the rotation matrices. Hence, the energy that we need to minimize is
We readily have,
Setting these derivatives to zero, we obtain
Sparse initial transformations A more robust initial transformation can be achieved by adding an \(L_1\) penalty to the energy given in Eq. (20)
The effect of this additional penalty is that it makes the initial transformations sparse, which results in a deformation with less artifacts. The parameter \(\beta _{\text {sp}}\) controls the amount of sparsity in the initial solution of \(\mathbf{T}\). Equation (23) can be solved efficiently using the elastic net regression method [51].
4.4 Extensions
Updating constraints It may happen that some of the h linear constraints are unavailable due to noise or occlusions. This can be easily solved by deleting the appropriate rows of \(\mathbf{X}\) and \(\mathbf{Y}\) and efficiently updating the Cholesky factorization.
Dictionary reduction When the input meshes are similar to each other, the proposed example-based dictionary becomes redundant. The dictionary can be reduced considerably by clustering similar dictionary atoms. For this purpose, we use the k-medoids clustering algorithm [22]. The advantage of k-medoids over k-means clustering is that each cluster center of the k-medoids procedure is represented by one of the original dictionary atoms. This makes the appearance of the deformed shape more plausible compared to using k-means clustering for dimensionality reduction.
Change of dictionaries It is sometimes useful to work with two different dictionaries. In that case, the representations of the mesh in these two subspaces can be converted from one to the other in a simple way. Suppose we are given the dictionaries \(\mathbf{D}_1\), \(\mathbf{D}_2\) and a good approximation of the transformation \(\mathbf{T}_1\). We want to find a transformation \(\mathbf{T}_2\) such that the deformation \(\mathbf{D}_2\mathbf{T}_2\) will be closest to deformation \(\mathbf{D}_1\mathbf{T}_1\). That is, in the \(L_2\) sense, we want to minimize \(\left||{\mathbf{D}_1\mathbf{T}_1-\mathbf D}_2\mathbf{T}_2\right||_2^2\). Therefore, the transformation \(\mathbf{T}_2\) can easily be solved by applying the least squares method
This is particularly useful when one wants to initialize the transformations using a low-dimensional dictionary by applying Eq. (23), and then change to a richer dictionary for obtaining more refined transformations.

Deformation using the example-based LBO dictionary. The left portion of the figure shows the cat and centaur ground-truth target shapes (colored in gray). On the right we show the near perfect representation of these target shapes by a linear combination of the dictionary’s atoms. In this case, the weighting functions are the eigenfunctions of the Laplace–Beltrami operator that correspond to the lowest 15 eigenvalues. The exemplar shapes that are used to extract the example-based LBO dictionaries for representing the shapes are shown inside the box
5 Experimental Results
Implementation Considerations In our implementation we use \(m \le 15\) eigenfunctions as the weighting functions for the example-based LBO dictionary. To support natural articulated shapes deformation, we construct the example-based skeleton dictionary. Its weights are generated using an automatic example-based skinning software package [27]. These skeleton weights are also used to define the rotation clusters. After constructing the dictionary from our mesh examples, we decrease the size of the dictionary using the k-medoids clustering algorithm. This step typically reduces the size of the dictionary in half.
The transformations are found in several steps. We begin by estimating the sparse initial transformations using Eq. (23). Typically, we start with \(m \le 4\) eigenfunctions as the weighting functions. Then, we apply a two-stage optimization procedure. In the first step we minimize the average ARAP energy of Eq. (11). This energy, although robust, tends to smooth out some of the details of the shape. Therefore, in the second step we optimize the minimal ARAP energy of Eq. (12) that effectively selects one reference pose which seems to be closest to the target pose. Practically, we apply one iteration of Algorithm 1, and one iteration of Algorithm 2. Then, we select the closest reference shape and continue to calculate the ARAP energy for the selected reference shape only. After a few iterations, we apply Eq. (24) and change to a richer dictionary that can reflect finer details of the shape. We construct this richer dictionary according to the properties of the subject we want to deform. For articulated shapes, we use the example-based skeleton dictionary and omit the smoothness energy term. For non-articulated objects, we increase the number of eigenfunctions used to construct the example-based LBO dictionary. Totally, we iterate the local, scale and global steps 10 times. The tuning parameters \(\beta _{lc}\) and \(\beta _{sm}\) are kept fixed for all shapes.
The algorithm was implemented in MATLAB with some optimizations in C++. We use the SVD routines provided by McAdams et al. [35]. All the experiments were executed on a 3.00 GHz Intel Core i7 machine with 32GB RAM. In Table 1 we give the settings for different mesh classes [9, 41] and typical performance of the algorithm. For these settings the algorithm takes between 10 and 25 ms.
Example-based dictionary The example-based dictionary spans natural deformations of a given shape with a small error. In Fig. 2 we show some examples of deformations created using the example-based LBO dictionary with 15 eigenfunctions. The mesh parameters and number of example shapes used are as in Table 1. Observe that there are no noticeable artifacts in these deformations. We note that the experiments indicate that the accuracy of the proposed model increases with the number of example shapes. For each shape in the database [5], we found the closest deformed shape in the \(L_2\) sense. Let \({\mathcal M}^{*}\), \(\tilde{\mathcal M}\) be the ground-truth mesh and the deformed mesh, respectively, and let \({\mathcal A}^*\) be the surface area of \({\mathcal M}^{*}\). We define the distortion between \({\mathcal M}^{*}\) and \(\tilde{\mathcal M}\) as the maximal Euclidean distortion between corresponding vertices of the two meshes normalized by the square root of \({\mathcal A}^*\).
where \({\mathbf{v}^{*}_1}, \dots , \mathbf{v}^{*}_n \in \mathbb {R}^{d}\) and \({\tilde{\mathbf{v}}_1}, \dots , \tilde{\mathbf{v}}_n \in \mathbb {R}^{d}\) are the positions of the vertices belonging to the meshes \({\mathcal M}^{*}\) and \(\tilde{\mathcal M}\), respectively. Then, we average this maximal distortion for all shapes. We observe that the mean maximal distortion decreases as the number of example shapes grows. We also compare the example-based LBO and the skeleton dictionaries. Although quantitatively, the example-based LBO dictionary seems to perform better, our experience suggests that for shapes that have a well-defined skeleton, the example-based skeleton dictionary is more pleasing to the eye, as it captures the stiffness of the bones. Another conclusion is that using many examples improves the deformation accuracy. This can be seen by calculating the mean maximal distortion of the deformed shape when the example-based LBO dictionary is constructed using one shape only, while keeping the number of dictionary atoms the same and without applying the dictionary reduction step. Table 2 summarizes the results.
It is interesting to examine the runtime of the algorithm compared to the dictionary size and the number of base shapes. The last two columns of Table 2 present the iteration time for solving the minimal ARAP energy (with the skeleton dictionary) and the total runtime of the algorithm. Notice, that while the number of example shapes increases from 1 to 8, the time for one iteration grows only by a factor of 2 and that the overall algorithm runtime increases by less than 3 times.

The four dog shapes are used as examples for our method (left). The deformed shape (right) is found from the vertex positions (middle). In this case the deformed shape is 50% larger than the reference ones

Example-based deformed shapes from few vertex positions of a hand shape. Scale factor is 70%
Example-based deformation from few vertex positions Perhaps, the most powerful application of our example-based framework is finding a naturally deformed shape from just a small number of vertex positions. In this scenario, we are given the positions of just a few points of a single depth image of a target shape. Given prior example shapes in different postures, we are able to faithfully and reliably reconstruct the target shape. In Figs. 3 and 4, we show reconstructed dog and hand shapes from a small number of feature points. In these examples, the feature points were sampled in a scale different than that of the example shapes by a factor of 1.5 (dog), and 0.7 (hand). For the dog shape we used four example shapes, and for the hand shape we used seven example shapes. Six feature points were automatically selected by the farthest point sampling strategy. We used two dictionaries. The first, for robustness, is comparatively small with 4 eigenfuctions as the weighting functions, and the second is more expressive by using a skeletal based weighting functions. Change of dictionaries is done with Eq. (24). We minimize the average ARAP energy by Algorithm 1 and the minimal ARAP energy with Algorithm 2.

Automatic feature point correspondence and shape interpolation. The four examples of a horse (top middle) and the two sets of vertex positions (top left, top right) were used to generate a sequence of frames. Correspondence of the points on the four legs (circled in blue) was detected by minimizing the example-based deformation energy for all permissible correspondences. The example-based deformations (bottom left and right) were then interpolated at four times the original frame rate to produce the movie sequence (bottom) (Color figure online)

Nonrigid ICP. Left to right: The three exemplar shapes, the uncorrupted and complete target shape, the acquired partial shape with eight known feature points (marked as red dots), the initial deformation using the feature points and the final deformation after applying the nonrigid ICP (Color figure online)
Automatic feature point correspondence The example-based deformation energy can be used to find correspondence between the example shapes and the given feature points [49]. Because our method does not rely on good initialization nor on many input points, it is ideal for such a purpose. For example, in Fig. 5, we are given four reference shapes and eight feature points. In this demonstration, the correspondences of the four feature points that belong to each leg (circled in blue) are difficult to find. We can resolve this ambiguity by running our optimization algorithm for all 24 options of permissible correspondences, and calculate the example-based energy of Eq. (12) for each. Then, the correspondence can be found by choosing the option that gave the minimal deformation energy.

Evaluation of the shape completion and registration procedure applied to shapes from the TOSCA (top) and FAUST (bottom) datasets
Shape interpolation A nice application that can easily be performed is to interpolate between two deformed shapes. In our setting, we are given two instances of positional constraints. From these constraints, we find two deformed shapes and their rotations. Then, we are able to interpolate between these rotations. To produce the new transformations, we apply one additional global step. Figure 5 demonstrates an interpolation between two deformed shapes of a galloping horse. Four example meshes are used as an input. In the supplementary material, we add a video of a galloping horse reconstructed from few feature points. The video frames are interpolated by a factor of eight. Based on the proposed ideas, we developed a computer program that automatically finds a natural deformed shape from a user’s specified vertex locations and interpolates between the start pose and the final deformation of the shape, creating a smooth and intuitive motion of the shape. We provide a video that shows how this software is used to make an animation sequence of a moving person.
Nonrigid ICP The blended transformations can be plugged into a simple nonrigid ICP framework [3, 4, 30]. Nonrigid ICP registration alternates between finding pointwise correspondences and deforming one shape to best fit the other. Hence, we propose the following strategy. To find correspondences compare the vertex positions of all points and their surface normal vectors. In each iteration, we set new linear constraints according to the vertex positions of the obtained point-to-point correspondences and apply our blended transformations method to warp the nonrigid shapes while keeping the deformed shape inside the example manifold. We note that because the representation space is defined by the blended transformations, it is sufficient to match only a subset of points on the two shapes.
Shape completion and registration In many depth data acquisition scenarios, the acquired data consists of an incomplete, occluded and disconnected parts of a shape [10, 37, 43]. Given some known feature points in those parts of the shape, we want to find the deformation that best fits the partial data and detect the pointwise mapping between acquired partial shape and the reference shapes. To this end, we propose a two-step procedure. In the first step, the feature points are used to find an initial deformation. In the second step, the deformation is refined by applying a nonrigid ICP procedure. Since our deformation technique is able to find a good approximation from just a few vertex positions, it is ideal to be plugged into this procedure. Figure 6 shows an example of partial data of a cat shape (middle) with some known feature points (marked in red). The initial deformation was found by applying the proposed Fast Blended Transformation algorithm using the known feature points (second from left). The final deformation was attained by applying the nonrigid ICP algorithm in conjunction with our blended transformations approach (left). Notice that the nonrigid ICP algorithm corrected the tilt of the cat’s head.
We tested the proposed shape completion and registration procedure on shapes represented by triangulated meshes from the TOSCA and FAUST datasets [6, 9]. We performed 50 random experiments with different example and target shapes. For each experiment, we were given eight reference shapes and one target shape for which some of its vertices were removed. We assume that the remaining shape includes some predefined parts that amount to more than 50% of the shape’s area. We further assume that in these parts there are a number of identifiable feature points and that around each feature point, within a certain geodesic circle, no vertices were removed. In the test we performed the number of feature points was set to eight and the radius of the geodesic circle about each point was 15% of the square root of the shape’s area.
We studied the performance of our approach with different number of example shapes. In our implementation, we set the initial linear constraints to be the weighted average of the vertex positions in 10 different geodesic circles around each feature point. The weights of each vertex were proportional to its voronoi area. Using these linear constraints, we found an initial guess of the deformation. Then, we employed the nonrigid ICP algorithm for the rest of the mesh. We also compared our results with the ones obtained by plugging in the deformation method proposed by Der et al. [12] into our shape completion procedure, using the same skeleton structure. This method applies an example-based deformation gradient model on the problem and is computationally comparable to the proposed blended transformations algorithm. To achieve better results, we used a modified version of the deformation gradient model that supports soft constraints. Although the method of Der et al. is pretty basic, we believe that it presents most of the drawbacks of other example-based deformation techniques. For leveling the playing field, the automatic skeleton structure was found in the same way for all methods [27].
Figure 7 (left) compares the accuracy of the achieved deformations. The distortion curves describe the percentage of surface points falling within a relative distance from the target mesh. For each shape, the Euclidean distance between corresponding vertices is normalized by the square root of the shape’s area. As for the partial registration, the distortion curves shown in Fig. 7 (right) describe the percentage of correspondences that fall within a relative Euclidean distance from what is assumed to be their true locations, similar to the protocol of [24]. We see that both the deformation quality and the correspondence accuracy increase with the number of reference shapes. This is expected, since as more example poses are introduced, the example-based dictionary better spans the space of natural deformations and we have more poses to compare against. We also notice that for these experiments, our deformation approach (even with one reference shape as in [19]) significantly outperforms the inverse kinematics method of Der et al. [12]. This can be explained by the fact that the reduced deformable model of Der et al. is based on explicit interpolation between the reference poses using deformation gradients. Apparently, this model needs a large number of reference poses to cover all the allowed isometric transformations. In contrast, our model implicitly finds the example manifold by a linear combination of the dictionary atoms and the ARAP energy. Hence, it needs far fewer examples. Also, our initial deformation using the sparsity promoting \(L_1\) penalty is better then using one of the reference shapes as an initial guess. This is especially true when the target shape is not similar to any of the reference shapes (Table 3).

Deformed shapes constructed by omitting some of the steps in the proposed example-based framework. A Restricting the example-based dictionary to use one example. B Comparing the deformed shape to only one reference shape. C Skipping the scale step, by setting \(\alpha = 1\)
6 Discussion
We tested some deficient versions of our example-based deformation framework. In Fig. 8, we show several examples of how these partial versions of the algorithm behave. For comparison to the complete method see Figs. 3 and 4. We notice that the most important part of the proposed framework is the construction of the dictionary from multiple examples. If only one example is used (A), as in [19], the deformation algorithm fails when the shape has many degrees of freedom.
Although the method is robust and usually performs very well, some limitations and failures in particular cases do exist. Despite the usually pleasing to the eye deformations of the proposed example-based approach, sometimes undesirable artifacts might occur. This is the result of the collinearity between different dictionary atoms. As for the performance of the algorithm, the deformation can be produced in real time but the algorithm cannot accommodate for video applications with many objects that need to be simultaneously deformed. This problem can be solved by using the proposed algorithm only for objects for which a previous pose cannot be used for the initialization of the current one. Another drawback is that if the example shapes do not incorporate enough information for extracting the right rotation clusters, then, the algorithm will ultimately fail. Also, the current evaluation system does not prevent self-intersections.
7 Conclusions
We applied the concept of overcomplete dictionary representation to the problem of shape deformation. The proposed example-based deformation approach extends the subspace of physically plausible deformations, while controlling the smoothness of the reconstructed mesh. The blended transformations enable us to find a new pose from a small number of known feature points without any additional information. It is well suited for real-time applications as well as offline animation and analysis systems. In the future, we plan to apply the proposed framework to various problems from the field of shape understanding, such as gesture recognition, registration of MRI images, and prior-based object reconstruction from depth images.
References
Alexa, M.: Differential coordinates for local mesh morphing and deformation. Vis. Comput. 19(2), 105–114 (2003)
Alexa, M., Cohen-Or, D., Levin, D.: As-rigid-as-possible shape interpolation. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH’00, pp. 157–164. ACM Press/Addison-Wesley Publishing Co., New York, NY, USA (2000). https://doi.org/10.1145/344779.344859
Allen, B., Curless, B., Popović, Z.: The space of human body shapes: reconstruction and parameterization from range scans. ACM Trans. Graph. 22(3), 587–594 (2003). https://doi.org/10.1145/882262.882311
Amberg, B., Romdhani, S., Vetter, T.: Optimal step nonrigid icp algorithms for surface registration. In: IEEE Conference on Computer Vision and Pattern Recognition, 2007. CVPR ’07, pp. 1–8 (2007). https://doi.org/10.1109/CVPR.2007.383165
Anguelov, D., Srinivasan, P., cheung Pang, H., Koller, D., Thrun, S., Davis, J.: The correlated correspondence algorithm for unsupervised registration of nonrigid surfaces. In: Saul, L.K., Weiss, Y., Bottou, L. (eds.) Advances in Neural Information Processing Systems vol. 17, pp. 33–40. MIT Press, Cambridge (2005). http://papers.nips.cc/paper/2601-the-correlated-correspondence-algorithm-for-unsupervised-registration-of-nonrigid-surfaces.pdf
Bogo, F., Romero, J., Loper, M., Black, M.J.: Faust: dataset and evaluation for 3d mesh registration. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2014)
Bouaziz, S., Martin, S., Liu, T., Kavan, L., Pauly, M.: Projective dynamics: fusing constraint projections for fast simulation. ACM Trans. Graph. 33(4), 154:1–154:11 (2014). https://doi.org/10.1145/2601097.2601116
Bouaziz, S., Wang, Y., Pauly, M.: Online modeling for realtime facial animation. ACM Trans. Graph. (TOG) 32(4), 40 (2013)
Bronstein, A.M., Bronstein, M.M., Kimmel, R.: Numerical Geometry of Non-rigid Shapes. Springer, Berlin (2008)
Brunton, A., Wand, M., Wuhrer, S., Seidel, H.P., Weinkauf, T.: A low-dimensional representation for robust partial isometric correspondences computation. Graph. Models 76(2), 70–85 (2014)
Chao, I., Pinkall, U., Sanan, P., Schröder, P.: A simple geometric model for elastic deformations. In: ACM SIGGRAPH 2010 Papers, SIGGRAPH’10, pp. 38:1–38:6. ACM, New York, NY, USA (2010). https://doi.org/10.1145/1833349.1778775
Der, K.G., Sumner, R.W., Popović, J.: Inverse kinematics for reduced deformable models. ACM Trans. Graph. 25(3), 1174–1179 (2006). https://doi.org/10.1145/1141911.1142011
Dey, T.K., Ranjan, P., Wang, Y.: Eigen deformation of 3d models. Vis. Comput. 28(6–8), 585–595 (2012)
Elad, M.: Sparse and Redundant Representations: From Theory to Applications in Signal and Image Processing. Springer, Berlin (2010)
Feng, W.W., Kim, B.U., Yu, Y.: Real-time data driven deformation using kernel canonical correlation analysis. In: ACM SIGGRAPH 2008 Papers, SIGGRAPH’08, pp. 91:1–91:9. ACM, New York, NY, USA (2008). https://doi.org/10.1145/1399504.1360690
Fröhlich, S., Botsch, M.: Example-driven deformations based on discrete shells. Comput. Graph. Forum 30(8), 2246–2257 (2011). https://doi.org/10.1111/j.1467-8659.2011.01974.x
Gao, L., Lai, Y.K., Liang, D., Chen, S.Y., Xia, S.: Efficient and flexible deformation representation for data-driven surface modeling. ACM Trans. Graph. (TOG) 35(5), 158 (2016)
Grinspun, E., Hirani, A.N., Desbrun, M., Schröder, P.: Discrete shells. In: Proceedings of the 2003 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, SCA’03, pp. 62–67. Eurographics Association, Aire-la-Ville, Switzerland, Switzerland (2003)
Jacobson, A., Baran, I., Kavan, L., Popović, J., Sorkine, O.: Fast automatic skinning transformations. ACM Trans. Graph. 31(4), 77:1–77:10 (2012). https://doi.org/10.1145/2185520.2185573
Jacobson, A., Baran, I., Popović, J., Sorkine-Hornung, O.: Bounded biharmonic weights for real-time deformation. Commun. ACM 57(4), 99–106 (2014). https://doi.org/10.1145/2578850
James, D.L., Twigg, C.D.: Skinning mesh animations. In: ACM SIGGRAPH 2005 Papers, SIGGRAPH’05, pp. 399–407. ACM, New York, NY, USA (2005). https://doi.org/10.1145/1186822.1073206
Kaufman, L., Rousseeuw, P.: Clustering by Means of Medoids. North-Holland, Amsterdam (1987)
Kavan, L., Sloan, P.P., O’Sullivan, C.: Fast and efficient skinning of animated meshes. Comput. Graph. Forum 29(2), 327–336 (2010). https://doi.org/10.1111/j.1467-8659.2009.01602.x
Kim, V.G., Lipman, Y., Funkhouser, T.: Blended intrinsic maps. In: ACM SIGGRAPH 2011 Papers, SIGGRAPH’11, pp. 79:1–79:12. ACM, New York, NY, USA (2011). https://doi.org/10.1145/1964921.1964974
Koyama, Y., Takayama, K., Umetani, N., Igarashi, T.: Real-time example-based elastic deformation. In: Proceedings of the 11th ACM SIGGRAPH/Eurographics Conference on Computer Animation, EUROSCA’12, pp. 19–24. Eurographics Association, Aire-la-Ville, Switzerland, Switzerland (2012). https://doi.org/10.2312/SCA/SCA12/019-024
Kry, P.G., James, D.L., Pai, D.K.: Eigenskin: real time large deformation character skinning in hardware. In: Proceedings of the 2002 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, SCA’02, pp. 153–159. ACM, New York, NY, USA (2002). https://doi.org/10.1145/545261.545286
Le, B.H., Deng, Z.: Robust and accurate skeletal rigging from mesh sequences. ACM Trans. Graph. 33(4), 84:1–84:10 (2014). https://doi.org/10.1145/2601097.2601161
Levi, Z., Gotsman, C.: Smooth rotation enhanced as-rigid-as-possible mesh animation. IEEE Trans. Vis. Comput. Graph. 21(2), 264–277 (2015)
Lewis, J.P., Cordner, M., Fong, N.: Pose space deformation: a unified approach to shape interpolation and skeleton-driven deformation. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH’00, pp. 165–172. ACM Press/Addison-Wesley Publishing Co., New York, NY, USA (2000). https://doi.org/10.1145/344779.344862
Li, H., Sumner, R.W., Pauly, M.: Global correspondence optimization for non-rigid registration of depth scans. Comput. Graph. Forum 27(5), 1421–1430 (2008). https://doi.org/10.1111/j.1467-8659.2008.01282.x
Lipman, Y., Sorkine, O., Cohen-Or, D., Levin, D., Rossi, C., Seidel, H.P.: Differential coordinates for interactive mesh editing. In: Shape Modeling Applications, 2004. Proceedings, pp. 181–190 (2004). https://doi.org/10.1109/SMI.2004.1314505
Liu, L., Zhang, L., Xu, Y., Gotsman, C., Gortler, S.J.: A local/global approach to mesh parameterization. Comput. Graph. Forum 27(5), 1495–1504 (2008). https://doi.org/10.1111/j.1467-8659.2008.01290.x
Magnenat-thalmann, N., Laperrire, R., Thalmann, D., Montral, U.D.: Joint-dependent local deformations for hand animation and object grasping. In: Proceedings on Graphics interface vol. 88, pp. 26–33 (1988)
Martin, S., Thomaszewski, B., Grinspun, E., Gross, M.: Example-based elastic materials. ACM Trans. Graph. 30(4), 72:1–72:8 (2011). https://doi.org/10.1145/2010324.1964967
McAdams, A., Selle, A., Tamstorf, R., Teran, J., Sifakis, E.: Computing the singular value decomposition of 3\(\times \) 3 matrices with minimal branching and elementary floating point operations. Technical Report, University of Wisconsin-Madison (2011)
Pinkall, U., Polthier, K.: Computing discrete minimal surfaces and their conjugates. Exp. Math. 2(1), 15–36 (1993). https://doi.org/10.1080/10586458.1993.10504266
Rodolà, E., Cosmo, L., Bronstein, M.M., Torsello, A., Cremers, D.: Partial functional correspondence. In: Computer Graphics Forum. Wiley Online Library (2016)
Schumacher, C., Thomaszewski, B., Coros, S., Martin, S., Sumner, R., Gross, M.: Efficient simulation of example-based materials. In: Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, pp. 1–8. Eurographics Association (2012)
Sloan, P.P.J., Rose III, C.F., Cohen, M.F.: Shape by example. In: Proceedings of the 2001 Symposium on Interactive 3D Graphics, I3D’01, pp. 135–143. ACM, New York, NY, USA (2001). https://doi.org/10.1145/364338.364382
Sorkine, O., Alexa, M.: As-rigid-as-possible surface modeling. In: Proceedings of EUROGRAPHICS/ACM SIGGRAPH Symposium on Geometry Processing, pp. 109–116 (2007)
Sumner, R.W., Popović, J.: Deformation transfer for triangle meshes. ACM Trans. Graph. 23(3), 399–405 (2004). https://doi.org/10.1145/1015706.1015736
Sumner, R.W., Zwicker, M., Gotsman, C., Popović, J.: Mesh-based inverse kinematics. In: ACM SIGGRAPH 2005 Papers, SIGGRAPH’05, pp. 488–495. ACM, New York, NY, USA (2005). https://doi.org/10.1145/1186822.1073218
van Kaick, O., Zhang, H., Hamarneh, G.: Bilateral maps for partial matching. In: Computer Graphics Forum, vol. 32, pp. 189–200. Wiley Online Library (2013)
Von-Tycowicz, C., Schulz, C., Seidel, H.P., Hildebrandt, K.: Real-time nonlinear shape interpolation. ACM Trans. Graph. 34(3), 34:1–34:10 (2015). https://doi.org/10.1145/2729972
Wang, R.Y., Pulli, K., Popović, J.: Real-time enveloping with rotational regression. ACM Trans. Graph. (2007). https://doi.org/10.1145/1276377.1276468
Wang, Y., Jacobson, A., Barbič, J., Kavan, L.: Linear subspace design for real-time shape deformation. ACM Trans. Graph. (TOG) 34(4), 57 (2015)
Winkler, T., Drieseberg, J., Alexa, M., Hormann, K.: Multi-scale geometry interpolation. Comput. Graph. Forum 29(2), 309–318 (2010). https://doi.org/10.1111/j.1467-8659.2009.01600.x
Xu, D., Zhang, H., Wang, Q., Bao, H.: Poisson shape interpolation. Graph. Models 68(3), 268–281 (2006)
Zhang, H., Sheffer, A., Cohen-Or, D., Zhou, Q., Van Kaick, O., Tagliasacchi, A.: Deformation-driven shape correspondence. Comput. Graph. Forum 27(5), 1431–1439 (2008). https://doi.org/10.1111/j.1467-8659.2008.01283.x
Zhang, W., Zheng, J., Thalmann, N.M.: Real-time subspace integration for example-based elastic material. In: Computer Graphics Forum, vol. 34, pp. 395–404. Wiley Online Library (2015)
Zou, H., Hastie, T.: Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 67(2), 301–320 (2005)
Acknowledgements
Funding was provided by European Research Council (Grant No. 267414).
Author information
Authors and Affiliations
Corresponding author
Additional information
Alon Shtern and Matan Sela have contributed equally to this work.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary material 1 (mp4 12921 KB)
Rights and permissions
About this article

Cite this article
Shtern, A., Sela, M. & Kimmel, R. Fast Blended Transformations for Partial Shape Registration. J Math Imaging Vis 60, 913–928 (2018). https://doi.org/10.1007/s10851-017-0782-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10851-017-0782-9