
Abstract
Given that happiness or satisfaction with life is generally measured via an ordinal variable, the question arises as to how one should measure average happiness or satisfaction with life in a country, given that there is no arithmetic mean when dealing with ordinal variables. The same issue exists as far as deriving measures of inequality in happiness or in satisfaction with life is concerned, since traditional inequality indices cannot really be used with ordinal variables. The objective of this paper is to adopt recent suggestions made in the literature concerning the distribution of self-assessed health, an ordinal variable, and to propose new measures of the inequality in happiness or satisfaction with life and of the overall achievement in happiness or satisfaction with life. We apply the indices introduced in this literature and compare them with more traditional measures. Our empirical illustration is based on the World Values Surveys for the years 1995–98 (wave 3) and 2010–14 (wave 6), uses the data on satisfaction in life and covers 31 countries.
Similar content being viewed by others


Notes
Among the papers that included measures of inequality in happiness without emphasizing too much methodological issues, one may mention those of Ott (2005), Ovaska and Takashima (2010), Van Praag (2011), Balestra and Ruiz (2015), Niimi (2018), Jordá et al. (2019), Zaborskis et al. (2019), Kollamparambil (2020a) (2020b).
A Likert (1932) scale is a rating system aiming at measuring people’s attitudes, opinions, or perceptions. Subjects have a choice between different possible answers to a question or a statement. These possible answers could, for example be: “strongly agree”, “agree”, “am neutral”, “disagree” and “strongly disagree.” In some cases the categories of possible answers are coded numerically.
A Visual Analogue Scale (VAS) is a measurement instrument that attempts to measure a characteristic or attitude that is difficult to measure directly and is assumed to range across a continuum of values. It has often been used in clinical research to measure, for example, the intensity of pain that a patient feels.
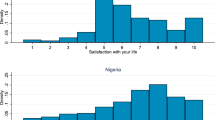
Responders are asked to answer to the following question: “Imagine a ladder/mountain with steps numbered from zero at the bottom to ten at the top. Suppose we say that the top of the ladder/mountain represents the best possible life for you and the bottom of the ladder/mountain represents the worst possible life for you. If the top step is 10 and the bottom step is 0, on which step of the ladder/mountain do you feel you personally stand at the present time?”.
A few numerical illustrations of the problems that occur when using cardinal indices when only ordinal variables are available are given in “Appendix 2”.
See, (Leik, 1966; Berry and Mielke, 1992; Blair and Lacy, 2000; Van der Cees, 2001; Van der Eijk, 2001; Van Doorslaer and Jones, 2003; Allison and Foster, 2004; Apouey, 2007; Tastle and Wierman, 2007; Abul Naga and Yalcin, 2008; Zheng, 2008; Abul Naga and Yalcin, 2010; Madden, 2010; Kalmijn and Arends, 2010; Giudici and Raffinetti, 2011; Kobus and Miłos, 2012; Costa Font and Cowell, 2013; Apouey and Silber, 2013; Lazar and Silber, 2013; Gravel et al., 2014; Schoder, 2014; Abul Naga and Stapenhurst, 2015; Lv et al., 2015; Kobus, 2015; Peñaloza, 2016; Yalonetzky, 2016; Cowell and Flachaire, 2017; Allanson, 2017; Schroeder and Yitzhaki, 2017; Cowell et al., 2017; Gravel et al., 2019; Kobus et al., 2019).
This measure was also derived by Apouey (2007).
Lv et al. (2015) stressed the fact (page 469, lines 17–19) that the index \(I_{{LWX1}}\) can be considered as the absolute Gini index of the ranks of the different categories (“happiness” categories in our case). Note that the absolute Gini index is equal to half the mean difference, a well-known measure of absolute dispersion.
As far as the index \(I_{{LWX2}}\) is concerned, note first that the expression (K−1) appears in the definition of both \(I_{{LWX1}}\) and \(I_{{LWX1}}\). But (K−1) is in fact the maximum value of \(\left| {h - k} \right|\). In the definition of \(I_{{LWX1}}\), we observe that \(\left| {h - k} \right|\) is divided by its maximum value while in the definition of \(I_{{LWX2}}\) it appears that \(\left| {h - k} \right|\) is deducted from its maximum value. It is also easy to check that when the parameter α → 1, \(I_{{LWX2}}\) becomes very close to \(I_{{LWX1}}\). The parameter α allows one therefore to vary the weight we want to give to the gap (K−1) − \(\left| {h - k} \right|\).
The measure they propose is derived axiomatically using five axioms: a continuity axiom, an anonymity axiom, a scale invariance axiom, an independence axiom allowing them to define their index as a function of a sum of functions of status and a monotonicity in distance axiom according to which modifications in status that increase the distance between the status and the reference point are assumed to increase inequality.
A referee drew our attention to some possible advantage of the index proposed by Cowell and Flachaire (2017) when compared to the Abul Naga and Yalcin index. Consider a 3 point scale with proportions as follows: (0.5, 0.0, 0.5). In this case the index \({\mathrm{I}}_{\mathrm{A}\!\mathrm{Y}}\) is equal to 1. Add now extra blank steps at the extremes to have proportions (0.0, 0.5, 0.0, 0.5, 0.0). It then turns out that \({\mathrm{I}}_{\mathrm{A}\mathrm{Y}}=0.5\) while the index \({I}_{\alpha}\left(s,e\right)\) introduced by Cowell and Flachaire (2017) would keep the same value.
The surveys we use included also data on self-assessment of happiness but for this question the respondents were asked to use a four-point scale. We therefore thought that it would be better to focus on the answers given to questions on satisfaction in life as in this case respondents had a choice between ten possible answers.
We thank an anonymous referee for suggesting to add to the Gini, Atkinson and Theil indices the standard deviation and the coefficient of variation.
We computed bootstrap 5%-95% confidence intervals.
The Pearson correlation between the rankings of countries is identical to the Spearman rank correlation.
The cumulative relative frequency \(F_{k} \left( s \right)\) is defined as \(F_{k} \left( s \right) = \mathop \sum \nolimits_{{h = 1}}^{k} p_{h} \left( s \right)\)
Remember that equations (11) to (15) ignore the axioms of equity and proportion equality.
We will suppose henceforth that whenever \( \alpha \to 1, \) α will be assumed to be equal to 0.999.
It does not matter whether they label the ordinal categories 1,2,3,4,5 or 1,3,5,7,9 or 1,6,11,16,21, etc…
References
Abul Naga, R. H., & Stapenhurst, C. (2015). Estimation of inequality indices of the cumulative distribution function. Economics Letters, 130, 109–112.
Abul Naga, R. H., & Yalcin, T. (2008). Inequality measurement for ordered response health data. Journal of Health Economics, 27(6), 1614–1625.
Abul Naga, R. H. and Yalcin, T. (2010) “Median independent inequality orderings,” Technical Report, University of Aberdeen Business School.
Allanson, P. (2017). Monitoring income-related health differences between regions in great britain: a new measure for ordinal health data. Social Science & Medicine, 175, 72–80.
Allison, R. A., & Foster, J. (2004). Measuring health inequalities using qualitative data. Journal of Health Economics, 23, 505–524.
Apouey, B. (2007). Measuring health polarization with self-assessed health data. Health Economics, 16(9), 875–894.
Apouey, B. and J. Silber (2013) “Inequality and Bi-polarization in Socioeconomic Status and Health: Ordinal Approaches,” Research on Economic Inequality, vol. 21. Health and Inequality, P. Rosas Dias and O. O’Donnell, editors, pp. 77-109.
Apouey, B., J. Silber and Y. Xu (2019) “On inequality-sensitive and additive achievement measures based on ordinal data,” Review of Income and Wealth. Available at https://doi.org/10.1111/roiw.12427
Atkinson, A. B. (1970). On the measurement of inequality. Journal of Economic Theory, 2(3), 244–263.
Balestra, C., & Ruiz, N. (2015). Scale-invariant measurement of inequality and welfare in ordinal achievements: an application to subjective well-being and education in OECD countries. Social Indicators Research, 123, 479–500.
Becchetti, L., R. Massariy and P. Naticchioniz P. (2014) “The drivers of happiness inequality: Suggestions for promoting social cohesion,” Oxford Economic Papers 66(2): 419–442
Berry, K. J., & Mielke, P. W., Jr. (1992). Assessment of variation in ordinal data. Perceptual and Motor Skills, 74(1), 63–66.
Blair, J., & Lacy, M. G. (2000). Statistics of ordinal variation. Sociological Methods and Research, 28(3), 251–280.
Blanchflower, D. G., & Oswald, A. J. (2011). International happiness: A new view on the measure of performance. The Academy of Management Perspectives, 25(1), 6–22.
Bond, T. N., & Lang, K. (2019). The sad truth about happiness scales. Journal of Political Economy, 127(4), 1629–1640.
Chen, L.-Y., E. Oparina, N. Powdthavee and S. Srisuma (2019) “Have Economic Analyses of Happiness Data Been Futile? A Simple Truth about Happiness Scales,” IZA Discussion paper No. 12152, Bonn, Germany.
Clark, A. E. (2018) “Four Decades of the Economics of Happiness: Where Next?,” Review of Income and Wealth. Available at DOI: https://doi.org/10.1111/roiw.12369.
Costa-Font, J. and F. A. Cowell (2013) “Measuring Health Inequality with Categorical Data: Some Regional Patterns,” CESifo Working Paper Series 4427, CESifo Group Munich.
Cowell, F. A., & Flachaire, E. (2017). Inequality with ordinal data. Economica, 84(334), 29–321.
Cowell, F. A., M. Kobus and R. Kurek (2017) “Welfare and Inequality Comparisons for Uni- and Multi-dimensional Distributions of Ordinal Data,” STICERD - Public Economics Programme Discussion Papers 31, Suntory and Toyota International Centres for Economics and Related Disciplines, LSE.
Delhey, J., & Kohler, U. (2011). Is happiness inequality immune to income inequality? New evidence through instrument-effect-corrected standard deviations. Social Science Research, 40(3), 742–756.
Dolan, P., Peasgood, T., & White, M. (2008). Do we really know what makes us happy? a review of the economic literature on the factors associated with subjective well-being. Journal of Economic Psychology, 29, 94–122.
Doorslaer, van, E. and A. M. Jones (2003) “Inequalities in self-reported health: validation of a new approach to measurement,” Journal of Health Economics 22: 61–87
Dutta, I., & Foster, J. (2013). Inequality of happiness in the U.S.: 1972–2010. Review of Income and Wealth, 59(3), 393–415.
Eijk, C. Van der (2001) “Measuring Agreement in Ordered Rating Scales,” Quality and Quantity 35(3): S. 325–341
Erreygers, G. (2009). Correcting the concentration index. Journal of Health Economics, 28(2), 504–515.
Ferrer-i-Carbonell, A. (2013). Happiness economics. SERIES (Journal of the Spanish Economic Association), 4, 335–60.
Ferrer-i-Carbonell, A., & Frijters, P. (2004). How important is methodology for the estimates of the determinant of happiness? Economic Journal, 114, 641–659.
Frey, B. S., & Stutzer, A. (2002). Happiness and economics. Princeton University Press, Princeton, USA.
Gandelman, N., & Porzecanski, R. (2013). Happiness inequality: how much is reasonable? Social Indicators Research, 110(1), 257–269.
Giudici, P., & Raffinetti, E. (2011). A Gini concentration quality measure for ordinal variables (p. 1). Statistica e Diritto, Università di Pavia, Serie Statistica, No.
Gluzman, P., & Gasparini, L. (2018). International inequality in subjective well-being: An exploration with the Gallup World Poll. Review of Development Economics, 22(2), 610–631.
Gravel, N. B. Magdalou and P. Moyes (2014) “Ranking Distributions of an Ordinal Attribute,” halshs-01082996v2
Gravel, N. B. Magdalou and P. Moyes (2019) "Inequality measurement with an ordinal and continuous variable," Social Choice and Welfare 52(3): 453-475
Hayes, M. H. S., & Patterson, D. G. (1921). Experimental development of the graphic rating method. Psychological Bulletin, 18, 98–99.
Helliwell, J. F., Huang, H., & Wang, S. (2017). The social foundations of world happiness. In R. J. Helliwell, R. Layard, & J. Sachs (Eds.), World happiness report 2017 (pp. 8–47). Sustainable development solutions network.
Jordá, V., López-Noval, B., & Sarabia, J. M. (2019). Distributional dynamics of life satisfaction in Europe. Journal of Happiness Studies, 20, 1015–1039.
Kaiser, C., & Vendrik, M. C. M. (2020). “How threatening are transformations of happiness scales to subjective wellbeing research”, IZA Discussion paper 13905. Bonn.
Kalmijn, W. M., & Arends, L. R. (2010). Measures of inequality: application to happiness in nations. Social Indicators Research, 99, 147–162.
Kalmijn, W. and R. Veenhoven (2005) “Measuring Inequality of Happiness in Nations: In Search for Proper Statistics, “Journal of Happiness Studies 6: 357–396.
Kobus, M. (2015). Polarization measurement for ordinal data. Journal of Economic Inequality, 13, 275–297.
Kobus, M., & Miłos, P. (2012). Inequality decomposition by population subgroups for ordinal data. Journal of Health Economics, 31, 15–21.
Kobus, M., Pólchlopek, O., & Yalonetzky, G. (2019). Inequality and welfare in quality of life among OECD countries: Non-parametric treatment of ordinal data. Social Indicators Research, 143, 201–232.
Kollamparambil, U. (2020). Happiness, happiness inequality and income dynamics in South Africa. Journal of Happiness Studies, 21(1), 201–222.
Kollamparambil, U. (2020). Socio-economic inequality of wellbeing: a comparison of Switzerland and South Africa. Journal of Happiness Studies, Available at. https://doi.org/10.1007/s10902-020-00240-w
Kolm, S.-Ch. (1969). The optimal production of social justice. In H. Guitton & J. Margolis (Eds.), Public Economics (pp. 145–200). Macmillan.
La Haye, R., & Ziler, P. (2019). The Gini mean difference and variance. Metron, 77, 43–52.
Lane, T. (2017). How does happiness relate to economic behaviour? A review of the literature. Journal of Behavioral and Experimental Economics, 68, 62–78.
Lazar, A., & Silber, J. (2013). On the cardinal measurement of health inequality when only ordinal information is available on individual health status. Health Economics, 22, 106–113.
Leik, R. K. (1966). A measure of ordinal consensus. Pacific Sociological Review, 9(2), 85–90.
Likert, R. (1932). A technique for the measurement of attitudes. Archives of Psychology, 140, 1–55.
Lv, G., Wang, Y., & Xu, Y. (2015). On a new class of measures for health inequality based on ordinal data. Journal of Economic Inequality, 13(3), 465–477.
Madden, D. (2010). Ordinal and cardinal measures of health inequality: an empirical comparison. Health Economics, Health Economics Letters, 19(2), 243–250.
Niimi, Y. (2018). What affects happiness inequality? Evidence from Japan. Journal of Happiness Studies, 19(2), 521–543.
Ott, J. (2005). Level and inequality of happiness in nations: does greater happiness of a greater number imply greater inequality in happiness? Journal of Happiness Studies, 6, 397–420.
Ovaska, T., & Takashima, R. (2010). Does a rising tide lift all the boats? Explaining the national inequality of happiness. Journal of Economic Issues, 44(1), 205–224.
Peñaloza, R. (2016). Gini Coefficient for Ordinal Categorical Data. University of Brasilia, Brazil.
Powdthavee, N. (2007). Economics of happiness: A Review of literature and applications. Southeast Asian Journal of Economics (formerly Chulalongkorn Journal of Economics), 19(1), 51–73.
Praag, van B.M.S. and A. Ferrer-i-Carbonell (2004) Happiness Quantified, a Satisfaction Calculus Approach. Oxford University Press, Oxford, UK
Reardon, S. F. (2009) “Measures of Ordinal Segregation,” Research on Economic Inequality, vol. 17. Emerald: Bingley, UK; 129–155.
Schoder, J. (2014) “Inequality with ordinal data. Cross-disciplinary review of methodologies and applications to life satisfaction in Europe,” Geographies of Uneven Development Working Paper No. 5, Department of Geography and Geology, University of Salzburg, Austria.
Schroeder, C., & Yitzhaki, S. (2017). Revisiting the evidence for cardinal treatment of ordinal variables. European Economic Review, 92, 337–358.
Stevenson, B., & Wolfers, J. (2008). Happiness Inequality in the United States. Journal of Legal Studies, 37(2), S33-79.
Studer, R. (2011) “Does it matter how happiness is measured? Evidence from a randomized controlled experiment,” Working Paper No. 49, Department of Economics, University of Zurich.
Stutzer, A. and B. S. Frey (2013) “Introduction Recent Developments in the Economics of Happiness: A Select Overview,” in B. S. Frey and A. Stutzer eds, Recent Developments in the Economics of Happiness, op. cit.
Tastle, W. J., & Wierman, M. J. (2007). Consensus and dissention: A measure of ordinal dispersion. International Journal of Approximate Reasoning, 45, 531–545.
van der Cees, E. (2001). Measuring agreement in ordered rating scales. Quality & Quantity, 35, 325–341.
Van Praag, B. (2011). Well-being inequality and reference groups: An agenda for new research. Journal of Economic Inequality, 9(1), 111–127.
Veenhoven, R. (1990) “Inequality in Happiness. Inequality in countries compared between countries,” Paper presented at the 12th Work Congress of Sociology in Madrid July 1990. Working Group Social Indicators and Quality of Life. Session 7, Social trends and Inequality.
Veenhoven, R. (2005). Inequality of happiness in nations. Journal of Happiness Studies, 6, 351–355.
Veenhoven, R. and W. Kalmijn (2005) “Inequality Adjusted Happiness in Nations. Egalitarianism and Utilitarianism Married in a New Index of Societal Performance,” Journal of Happiness Studies, Special Issue on ‘Inequality of Happiness in nations’ 6: 421-455.
Wiese, T. (2014). A literature review of happiness and economic and guide to needed research. Competitio, Scientific Journal XIII, 1, 117–131.
World Values Survey 1981-2014. World Values Survey Association (www.worldvaluessurvey.org). Aggregate File Producer: JDSystems, Madrid SPAIN.
Yalonetzky, G. (2016). Robust inequality comparisons based on ordinal attributes with Kolm-independent measures. Economics Bulletin, 36(4), 2203–2208.
Yitzhaki, S., & Schechtman, E. (2013). The Gini Methodology: a Primer on a Statistical Methodology. Springer.
Zaborskis, A., Grincaite, M., Lenzi, M., Tesler, R., Moreno-Maldonado, C., & Mazur, J. (2019). Social inequality in adolescent life satisfaction: Comparison of measure approaches and correlation with macro-level indices in 41 countries. Social Indicators Research, 141(3), 1055–1079.
Zheng, B. (2008). Measuring inequality with ordinal data: a note. Research on Economic Inequality, 16, 177–188.
Zheng, B. (2011). A new approach to measure socioeconomic inequality in health. Journal of Economic Inequality, 9(4), 555–577.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
None of the authors has any conflict of interest or competing interests.
Ethical Approval
This research complies with the required ethical standards.
Informed Consent
The author give their consent for publication as stated by the rules of the journal.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
See Table 8.
Appendix 1.1 A Simple Illustration on the Limits of Cardinal Indices when Working with Ordinal Data
Assume now that we use the Gini index when analyzing ordinal data. Let us suppose first that individuals who are asked to give a self-assessment of their satisfaction with life have a choice between four possible answers, category 1 referring to the lowest and category 4 to the highest level of satisfaction with life. The numbers associated with these four categories are hence 1, 2, 3 and 4. Assume that there are 9 individuals who choose category 1, that no individual chooses category 2 or 3 and that one individual chooses category 4. It is then easy to show that the traditional Gini index of the distribution of levels of satisfaction with life will be equal to 0.208.
Assume now that in another survey covering this time 100 individuals, rather than 10, 99 individuals choose level 1, no one chooses levels 2 or 3 and one individual chooses level 4. It is then easy to check that the Gini index will now be equal to 0.0288.
If instead of 99 individuals choosing category 1, we had now 999 individuals choosing this category, in a survey covering 1000 individuals, the observations in the other 3 categories being as in the two previous examples, we would find that the Gini index is equal to 0.00299.
We therefore observe that when one individual is in the highest category and all the other individuals in the lowest category, the Gini index will be lower, the higher the number of individuals who are in the lowest category. Such a conclusion is in complete contradiction with what we know about the Gini index as will now be shown. Assume 10 individuals, 9 of them have a zero income and one has an income of 10. The Gini index is then equal to 0.9. If we now suppose that 99 individuals have a zero income and one an income of 10, the Gini index will be equal to 0.99. And if there are 999 individuals with a zero income and one with an income of 10, the Gini index will be equal to 0.999. The same results would evidently be obtained if the only individual with a positive income had an income of 100, 1000 or whatever positive number one selects. In short when all the individuals but one are in the worst state (with a zero income) and one individual only has a positive income, the Gini index is higher, the higher the number of individuals in the worst income state.
Assume that there are four happiness categories and that the cardinal numbers assigned to these categories are 0, 1 2 and 3, rather than 1, 2, 3 and 4. We would then discover that if 9 individuals are in the lowest category (given a value of 0) and 1 individual is in the highest category (no one is in the other categories), the Gini index will be equal to 0.9. If 99 individuals are in the lowest category and one in the highest (and still no one in the other categories) the Gini index will be equal to 0.99. Finally if 999 individuals are in the lowest category and one in the highest (and still no one in the other categories) the Gini index will be equal to 0.999. In other words when all the individuals but one are in the lowest category and one in the highest, the Gini index is now higher, and not lower, the higher the number of individuals in the lowest category. Which value to assign to each category is hence a crucial issue and, depending on the values selected, one can reach completely opposite conclusions.
We can also look at another critical illustration, one where half the individuals are in the lowest category and half in the highest. Following Abul Naga and Yalcin (2008), all the indices of inequality introduced in the literature for the case of ordinal variables (see, for example, Reardon, 2009, Lazar and Silber, 2013, Lv et al., 2015) have assumed that inequality will be maximal when half the individuals are in the lowest category and half in the highest. Let us now see what happens when we use the Gini index and assume, as before, equidistance between the different categories. Assuming that half of the individuals are in the lowest category and half in the highest and that the four categories receive respectively the values 1, 2, 3 and 4 (or 10, 20, 30 40; or 100. 200. 300, 400, etc…). We will then find that the Gini index is equal to 0.3. If we assign to the four categories the values 0, 1 2 and 3 (or, for example, 0, 100, 200 and 300) and still assume that half of the individuals are in the lowest and half in the highest category, the Gini index will be equal to 0.5. If we assign to the four categories the values 2, 3, 4, and 5 the Gini index will be equal to 0.214 and if, for example, the four categories receive respectively the values 97, 98, 99 and 100, the Gini index will be equal to 0.00761. In other words, when half of the population is in the lowest category and half in the highest, assuming equidistance between the different categories, the Gini index will be lower, the more equal in relative terms the values assigned to the different categories.
To summarize what we have stressed, we can first say that the implicit assumptions lying behind the use of the Gini index when dealing with ordinal variables are quite different from the assumptions made by the inequality measures that have been proposed to deal with cardinal variables. Second the Gini index (or any other cardinal measure of inequality) will be very sensitive to the values assigned to the different categories whereas the inequality indices introduced in the literature when working with ordinal variables do not depend at all on the values assigned to the different categories.
Appendix 2
Appendix 2.1
Rights and permissions
About this article

Cite this article
Bérenger, V., Silber, J. On the Measurement of Happiness and of its Inequality. J Happiness Stud 23, 861–902 (2022). https://doi.org/10.1007/s10902-021-00429-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10902-021-00429-7