
Abstract
This paper optimizes the step coefficients of first-order methods for smooth convex minimization in terms of the worst-case convergence bound (i.e., efficiency) of the decrease in the gradient norm. This work is based on the performance estimation problem approach. The worst-case gradient bound of the resulting method is optimal up to a constant for large-dimensional smooth convex minimization problems, under the initial bounded condition on the cost function value. This paper then illustrates that the proposed method has a computationally efficient form that is similar to the optimized gradient method.

Similar content being viewed by others
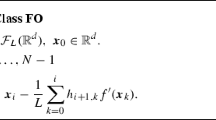

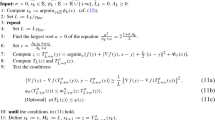
Notes
We found that the set of constraints in (P1) is sufficient for the exact worst-case gradient analysis of GM and OGM-G for (IFC), as illustrated in later sections. In other words, the resulting worst-case rates of GM and OGM-G in this paper are tight with our specific choice of the set of inequalities. Note that this relaxation choice in (P1) differs from the choice in [1, Problem (G\('\))].
References
Drori, Y., Teboulle, M.: Performance of first-order methods for smooth convex minimization: a novel approach. Math. Program. 145(1–2), 451–82 (2014). https://doi.org/10.1007/s10107-013-0653-0
Nesterov, Y.: A method for unconstrained convex minimization problem with the rate of convergence \(O(1/k^2)\). Dokl. Akad. Nauk. USSR 269(3), 543–7 (1983)
Nesterov, Y.: Introductory Lectures on Convex Optimization: A Basic Course. Kluwer, New York (2004). https://doi.org/10.1007/978-1-4419-8853-9
Nemirovsky, A.S.: Information-based complexity of linear operator equations. J. Complex 8(2), 153–75 (1992). https://doi.org/10.1016/0885-064X(92)90013-2
Kim, D., Fessler, J.A.: Optimized first-order methods for smooth convex minimization. Math. Program. 159(1), 81–107 (2016). https://doi.org/10.1007/s10107-015-0949-3
Drori, Y.: The exact information-based complexity of smooth convex minimization. J. Complex. 39, 1–16 (2017). https://doi.org/10.1016/j.jco.2016.11.001
Kim, D., Fessler, J.A.: Optimizing the efficiency of first-order methods for decreasing the gradient of smooth convex functions (2018). arxiv:1803.06600
Nesterov, Y., Gasnikov, A., Guminov, S., Dvurechensky, P.: Primal-dual accelerated gradient methods with small-dimensional relaxation oracle. Optim. Methods Softw. (2020). https://doi.org/10.1080/10556788.2020.1731747
Nesterov, Y.: How to make the gradients small. Optima 88 (2012). http://www.mathopt.org/?nav=optima_newsletter
Allen-Zhu, Z.: How to make the gradients small stochastically: even faster convex and nonconvex SGD. In: NIPS (2018)
Drori, Y., Shamir, O.: The complexity of finding stationary points with stochastic gradient descent. In: ICML (2020)
Carmon, Y., Duchi, J.C., Hinder, O., Sidford, A.: Lower bounds for finding stationary points II: first-order methods. Math. Program. (2019). https://doi.org/10.1007/s10107-019-01431-x
Kim, D., Fessler, J.A.: Another look at the Fast Iterative Shrinkage/Thresholding Algorithm (FISTA). SIAM J. Optim. 28(1), 223–50 (2018). https://doi.org/10.1137/16M108940X
Kim, D., Fessler, J.A.: Generalizing the optimized gradient method for smooth convex minimization. SIAM J. Optim. 28(2), 1920–50 (2018). https://doi.org/10.1137/17m112124x
Ghadimi, S., Lan, G.: Accelerated gradient methods for nonconvex nonlinear and stochastic programming. Math. Program. 156(1), 59–99 (2016). https://doi.org/10.1007/s10107-015-0871-8
Monteiro, R.D.C., Svaiter, B.F.: An accelerated hybrid proximal extragradient method for convex optimization and its implications to second-order methods. SIAM J. Optim. 23(2), 1092–1125 (2013). https://doi.org/10.1137/110833786
Taylor, A.B., Hendrickx, J.M., Glineur, F.: Smooth strongly convex interpolation and exact worst-case performance of first- order methods. Math. Program. 161(1), 307–45 (2017). https://doi.org/10.1007/s10107-016-1009-3
Nacson, M.S., Lee, J.D., Gunasekar, S., Savarese, P.H.P., Srebro, N., Soudry, D.: Convergence of gradient descent on separable data. In: AISTATS (2019)
Soudry, D., Hoffer, E., Nacson, M.S., Srebro, N.: The implicit bias of gradient descent on separable data. In: Proc. Intl. Conf. on Learning Representations (2018)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2(1), 183–202 (2009). https://doi.org/10.1137/080716542
Drori, Y., Taylor, A.B.: Efficient first-order methods for convex minimization: a constructive approach. Math. Program. (2019). https://doi.org/10.1007/s10107-019-01410-2
Taylor, A.B., Hendrickx, J.M., Glineur, F.: Exact worst-case convergence rates of the proximal gradient method for composite convex minimization. J. Optim. Theory Appl. 178(2), 455–76 (2018)
CVX Research Inc.: CVX: Matlab software for disciplined convex programming, version 2.0. http://cvxr.com/cvx (2012)
Grant, M., Boyd, S.: Graph implementations for nonsmooth convex programs. In: Blondel V., Boyd, S., Kimura, H. (eds.) Recent Advances in Learning and Control, Lecture Notes in Control and Information Sciences, pp. 95–110. Springer, Berlin (2008). http://stanford.edu/~boyd/graph_dcp.html
Kim, D., Fessler, J.A.: On the convergence analysis of the optimized gradient methods. J. Optim. Theory Appl. 172(1), 187–205 (2017). https://doi.org/10.1007/s10957-016-1018-7
Sturm, J.: Using SeDuMi 1.02, A MATLAB toolbox for optimization over symmetric cones. Optim. Methods Softw. 11(1), 625–53 (1999). https://doi.org/10.1080/10556789908805766
Löfberg, J.: YALMIP: a toolbox for modeling and optimization in MATLAB. In: Proc. of the CACSD Conference (2004)
Taylor, A.B., Hendrickx, J.M., Glineur, F.: Performance estimation toolbox (PESTO): automated worst-case analysis of first-order optimization methods. In: Proc. Conf. Decision and Control, pp. 1278–83 (2017). https://doi.org/10.1109/CDC.2017.8263832
Nesterov, Y.: Smooth minimization of non-smooth functions. Math. Program. 103(1), 127–52 (2005). https://doi.org/10.1007/s10107-004-0552-5
Acknowledgements
Part of this work was carried through while the first author was affiliated with the University of Michigan. The first author would like to thank Ernest K. Ryu for pointing out related references. The authors would like to thank associate editor and referees for useful comments, especially regarding the case where a finite minimizer does not exist. The first author was supported in part by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (No. 2019R1A5A1028324), and the POSCO Science Fellowship of POSCO TJ Park Foundation. The second author was supported in part by NSF grant IIS 1838179.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Alexander Mitsos.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Proof of Eqs. (25) and (26)
Appendix: Proof of Eqs. (25) and (26)
This proof shows the properties (25) and (26) of the step coefficients \(\{\tilde{h} _{i,j}\}\) (22).
We first show (25). We can easily derive
for \(i=2,\ldots ,N\) using (27). Again using the definition of (22) and (27), we have
for \(i=2,\ldots ,N,\;j=0,\ldots ,i-3\), which concludes the proof of (25).
We next prove the first two lines of (26) using the induction. For \(N=1\), we have \(\tilde{\theta } _1 = 1\) and
where the third equality uses (27). For \(N>1\), we have
where the third equality uses (27). Assuming \(\sum _{l=j+1}^N\tilde{h} _{l,j} = \tilde{\theta } _j\) for \(j=n,\ldots ,N-1\) and \(n\ge 1\), we get
where the last equality uses (27), which concludes the proof of the first two lines of (26).
We finally prove the last line of (26) using the induction. For \(i\ge 1\), we have
where the third and fourth equalities use (27). Then, assuming \(\sum _{l=i+1}^N\tilde{h} _{l,j}=\frac{\tilde{\theta } _i^4}{\tilde{\theta } _j\tilde{\theta } _{j+1}^2}\) for \(i=n,\ldots ,N-1\), \(j=0,\ldots ,i-1\) with \(n\ge 1\), we get:
where the second and third equalities use (25), which concludes the proof. \(\square \)
Rights and permissions
About this article

Cite this article
Kim, D., Fessler, J.A. Optimizing the Efficiency of First-Order Methods for Decreasing the Gradient of Smooth Convex Functions. J Optim Theory Appl 188, 192–219 (2021). https://doi.org/10.1007/s10957-020-01770-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-020-01770-2