
Abstract
The outbreak of coronavirus disease 2019 (COVID-19) continues to have a catastrophic impact on the living standard of people worldwide. To fight against COVID-19, many countries are using a combination of containment and mitigation activities. Effective screening of contaminated patients is a critical step in the battle against COVID-19. During the early medical examination, it was observed that patient having abnormalities in chest radiography images shows the symptoms of COVID-19 infection. Motivated by this, in this article, we proposed a unique framework to diagnose the COVID-19 infection. Here, we removed the fully connected layers of an already proven model VGG-16 and placed a new simplified fully connected layer set that is initialized with some random weights on top of this deep convolutional neural network, which has already learned discriminative features, namely, edges, colors, geometric changes,shapes, and objects. To avoid the risk of destroying the rich features, we warm up our FC head by seizing all layers in the body of our network and then unfreeze all the layers in the network body to be fine-tuned.The suggested classification model achieved an accuracy of 97.12% with 99.2% sensitivity and 99.6% specificity for COVID-19 identification. This classification model is superior to the other classification model used to classify COVID-19 infected patients.
Similar content being viewed by others

1 Introduction
The Novel COVID-19 pandemic is rapidly expanding across North America, Europe, Asia, and the Middle East. In late December 2019, this epidemic started from Wuhan and quickly spread throughout the world [20]. Coronaviruses are identified in the mid-1960s and have known to affect humans and a variety of animals. Since 2002, two categories of coronaviruses have identified that caused outbreaks in humans. In 2003, the first category of coronavirus known as SARS-CoV was identified, and the first infected case with SARS-CoV (Severe Acute Respiratory Syndrome) was spotted in Southern China. The second category virus of these families, known as MERS-CoV (Middle East Respiratory Syndrome), was identified in Saudi Arabia in 2012. These two outbreaks have caused more than 1600 deaths. COVID-19 is a strain of coronavirus known as the 2019 novel coronavirus (2019-nCoV). COVID-19 is a communicable disease caused by SARS-CoV-2 and creates severe respiratory compliances.
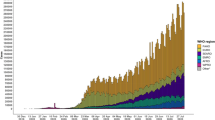
As claimed by an online COVID-19 virus tracker developed by The Lancet, and facilitated by Johns Hopkins University, the number of COVID-19 confirmed cases is 6.2 million as of 1st June 2020 and has now been diagnosed in 188 territories, in six continents. This fleet-footed COVID-19 epidemic is a major concern these days as it causes 3,72,566 number of deaths across the world. This death rate may increase in the future if we do not take the necessary measure to stop this epidemic. Presently “social distancing” is considered as suggestive prevention to break the epidemic chain. Figure 1 represents the total number of confirmed cases and daily reported cases in the world.
COVID-19 symptoms are flu-like and include fever, headache, dry cough, shortness in breath, diarrhea in the first two weeks of illness. These are the mild symptoms; however, in some cases, the symptoms are severe, often develop acute respiratory distress, and needs intensive care. According to WHO, 95% of the confirmed cases have mild symptoms, and 5% cases have critical conditions. We can not use these symptoms for accurate diagnosis as these symptoms are nonspecific and vary from person to person. According to Guan et al., out of 1099 COVID-19 cases, 44% of the patients had a fever before coming to the hospital, and 89% of the patient developed a fever during the treatment period [8]. They also found that 68% of patients had a cough and 38% fatigue with less percentage of common symptoms like sputum production and shortness of breath. It is reported that women are less infected than men, and the death rate in children between the age \(0-9\) is almost zero. Older people having other diseases like blood pressure, heart problems, pulmonary problems are severely infected by this COVID-19, and mortality cases are more in older persons as compared to younger ones. As the number of infected cases increases every day, the health system of many developed countries is overloaded because of the heavy demand for intensive care units [26].

Spread of COVID-19 cases across the world for the duration January, 2020 to June, 2020 (a) Confirmed cases around the world (b) Daily reported cases around the world
As COVID-19 is a communicable disease, to stop its human-to-human transmission, we need effective and rapid screening of infected cases, such that these patients can get instant treatment. The real-time polymerase chain reaction (RT-PCR) is the standard screening techniques used for diagnosing COVID-19 cases [28]. This test identifies SARS-COV-2 RNA from respiratory specimens like nasopharyngeal or oropharyngeal swabs. Though this RT-PCR testing technique is highly sensitive, it is taking up a great deal of time and involves a complex manual process. As approximately 75% COVID-19 patients expressed bilateral pneumonia [4], an alternative screening method has been used by radiologists, where the examination of chest radiography imaging like Computed Tomography (CT) or X-ray is conducted for detecting SARS COV-2 viral infection. During the early medical examination, it was observed that patients with a deformity in chest radiography images expressed the symptoms of COVID-19 infection [10, 16]. So, the diagnosis of COVID-19 cases using radiography images could be a key instrument for screening in epidemic areas. Due to the shortage of RT-PCR kit and its time-consuming process, radiography screening can be a good complement for PCR testing. As radiography examinations can be conducted quickly and have greater availability in the present health care system so, radiography screening can be used in those hospitals which lack the PCR infrastructure. According to Bernheim et al., 56% of the cases express normal CT findings in the first two days of infection with maximum infections occurs at around ten days after the first symptom. The most common features of lung infections in COVID-19 cases include ground-glass opacity (areas of hazy opacity) and compressible lung tissue. A retrospective study on imaging features shown that CT scans have 86 to 98% sensitivity and also increased in false-negative rates compared to RT-PCR testing [3]. The main limitation of using Computed Tomography images for COVID-19 diagnosis is its low specificity rate (25%) as features of CT images overlap with viral pneumonia [25]. Another important bottleneck faced in the examination of radiography image is the need for proficient radiologists to explicate the CT and X-ray images as the visual indicators are elusive. In that capacity, there is a high need for computer-assisted diagnostic systems that can help radiologists to quickly and precisely elucidate the radiography images. Deep learning models have been effectively used for image classification and recognition. Most of the studies focused on some specific network architecture for image classification. In this study, we have used an already proven convolutional neural network(CNN)architecture (VGG-16) with some fine-tuning for COVID-19 diagnosis.
VGG-16 model deals with a vital feature of CNN model that is the Depth. This model has a very small receptive field which is the least possible in size to get the feature map. The small size of filters allows VGG-16 to obtain large number of weight layers which leads to enhance the performance. All the hidden layers in this model use ReLU activation function which is capable of outputting a true zero value for the negative inputs. Due to the linear behavior of ReLU it avoids the problem of vanishing gradients as gradients are proportional to node activation. Also ReLU is computationally efficient and shows better convergence as compared to others. Though increase in the number of neurons decreases the training error, it also degrades the generalization ability of the network as the Nth hidden node may have some spurious connections. So we have fine-tuned the existing VGG-16 model by modifying the head of the network.
Motivated by the above reason, in this work, a fine-tuned VGG-16 framework is proposed for the diagnosis of COVID-19 infection from radiography images. The suggested model provides an end-to-end solution, where input is the raw CT-images and output is the diagnosis of COVID-19 or non-COVID-19 pneumonia. The main motivation of this work is to design an end-to-end solution with a higher sensitivity rate. The significant research contributions of this paper are:
-
To reduce the over-optimistic test performance, splitting of the original dataset into training, validation, and test set by eliminating patient overlap.
-
Use of Transfer learning techniques to train a deep convolutional neural network framework as state-of-the-art CNN required large datasets for on target feature extraction.
-
For extracting the rich and discriminating features, a new fully-connected layer head is appended on the top of the pr-trained VGG-16 model and fine-tuned the model from scratch for classification.
-
Reporting the performance comparison of the suggested framework with other state-of-the-art approaches.
The rest of the article is arranged as follows. Section 2 represents the existing research related to the scope of our work. Section 3 presents the details of the dataset and proposed classification model. In Sect. 4 experimental details and evaluation procedure are presented. Section 5 discusses the result of the experiment and comparative analysis. Finally, Sect. 6 presents the summarization and future scope.
2 Related work
The need for faster interpretation of X-ray and CT images motivated many researchers to develop artificial intelligence systems based on deep learning and outcomes expressed in terms of accuracy, sensitivity and specificity have shown to be propitious [7, 19]. However, these developed AI systems are not publicly available to the research circle for further understanding and extensions of these systems. Therefore AI researchers have given efforts to develop AI-enabled solutions for the diagnosis of COVID-19 infection from radiography images. Cohen attempt to build an open-source COVID chest X-ray images dataset [5]. This dataset contains COVID-19 cases, SARS, and MERS cases with annotation of CT and X-ray images. As it is publicly available, the research community can explore this dataset to build AI-based solutions for diagnosing COVID-19 cases.
Some AI systems, based on machine learning, have been reported for prediction of COVID-19 cases. Ozturk et al. [17] suggested a Darknet framework for automatic diagnosis of COVID-19 cases from raw chest X-ray images. Each Darknet layer has one convolutional layer followed by BatchNorm and LeakyReLU. This model produced a binary classification (COVID vs. Nonfindings) accuracy of 98.08% and multi-class classification accuracy of 87.02%. The sensitivity and specificity achieved by this model were 90.65% and 99.61% respectively for COVID-19 cases. The limitation of this model is that presence of 17 convolutional layers slow down the training by requiring lower learning rates and careful parameter initialization. It produced a low classification accuracy for multi-class cases and also the model used a limited number of COVID-19 X-ray Images to train the model.
Wang et al. [27] revamped the deep Inception (M-inception) model on radiography images. The model was applied to 453 CT images of pathogen-confirmed COVID-19 cases and previously diagnosed pneumonia and obtained an accuracy of 82.9%. The limitations of this model are need of expert radiologist for outlining the Region of interest (ROI) area and relatively small training dataset. Also the model has a low sensitivity rate (74%) for an external testing dataset. Narin et al. [15] used five different deep CNN (ResNet50, InceptionV3, ResNet101, ResNet152 and Inception-ResNetV2), which are pre-trained on ImageNet data, for classification of COVID-19 cases from Normal cases. The experimental result demonstrates that the ResNet50 model obtained 98% accuracy, the highest value among the rest. The main disadvantage of this model is that all these five pre-trained models have large number of layers which leads to over fitting when the number of parameters increased and also only the fully connected head is trained for classification.
Hemdan et al. [9] proposed a deep learning framework called COVIDX-Net. In this framework seven different (VGG19, DenseNet121, ResNetV2, InceptionV3, InceptionResNetV2, Xception, and MobileNetV2) deep convolutional networks are used for training and testing. The experimental result shows that VGG19 and DenseNet121 give 90% accuracy; better results as compared to other deep learning architecture used in this framework. The major drawback of this framework is that all these networks are pre-trained on the ImageNet data and trained on a relatively small number of COVID-19 images. Wang et al. [26] proposed a novel deep neural architecture known as COVID-Net and trained it on the COVIDx dataset, which contains 5941 posteroanterior chest radiography images from three different class COVID-19, non-COVID-19 Pneumonia, Normal and obtained an accuracy of 92.4%. In this study an high architectural diversity can be observed because of the use of projection-expansion-projection design pattern. Though this study achieved a strong sensitivity for COVID-19 cases, the positive predicted values for COVID-19 cases indicates a number of false positive COVID-19 detections. Apostolopoulos and Mpesiana [1] applied transfer learning techniques by training the layers that contain rich features closer to the output and cut off the layers having untrainable features.This framework has attained 98.75% accuracy for two classes and 93.48% accuracy for the three-class problem. This study uses large number of neurons in the fully connected layers for transfer learning and also requires more in-depth analysis of COVID-19 patient data. Sethy et al. [21] extracted features using a pre-trained deep convolutional network and apply SVM on the extracted features for classification of COVID-19. Their model achieved an accuracy of 95.38% with a false positive rate score of 95.52% for the diagnosis of COVID-19 cases. Hussain et al. [11] proposed a COVID-RENet architecture where they have used the pre-trained deep CNN for dynamic feature extraction and fed these features to the SVM classifier for classification of COVID-19 X-ray images. Their suggested method attained an accuracy of 98.3% with precision and recall value 96.67% and 98%, respectively. The major disadvantage of this model is that it does not provide an end-to-end architecture for clinical diagnosis.
Due to the availability of limited samples of COVID-19 infected chest X-rays, transfer learning is a favourable method to handle it. Hence, we customized a pre-trained deep neural network (VGG-16) by adding newly fully connected layers on top of it. We explore the deep features obtained by our customized deep neural network for classification of COVID-19 infection, which can help clinicians in better screening.
3 Methods
3.1 Dataset of the study
For conducting the experiment, radiography images from various sources are explored. A collection of COVID-19 X-ray images is available in the Github repository for research. Cohen et al. [5] attempts to build this open-source COVID-19 chest radiography images Dataset to develop an AI solution for the diagnosis of COVID-19 patients. This repository is comprising CT and X-ray images of people sufferers with COVID-19, severe acute breathing syndrome (SARS), Middle East respiratory syndrome (MERS), acute respiration distress syndrome (ARDS), and Pneumonia. Firstly, 147 COVID-19 chest radiography images with the posteroanterior view were selected from this Github repository. Secondly, a collection of Pneumonia and normal chest X-ray images were selected from Mooney [14] and are combined with this dataset for training the proposed model to classify COVID-19 from non-COVID-19 Pneumonia.The dataset contains a total of 1,272 images from 3 different classes, out of which 147 are COVID-19 images, 600 images are from non-COVID-19 Pneumonia, and 525 normal class. Figure 2 represents the chest radiography images of COVID-19, Normal, and Pneumonia, respectively.

Sample cases of different class labels of patients (a) COVID-19 (b) Normal (c) Pneumonia
The preference of these two datasets for developing our dataset is guided by the fact that both are open source and freely available for analysis. Also, as these datasets grow, we will preserve to grow our dataset. Figure 3 represents the different stages of chest X-ray images of a middle-aged patient who suffered from COVID-19 over a time period.

Chest X-ray images of a 50 year old man infected with COVID-19 over a week (a) Day 1: no significant findings, lungs clear (b) Day 4: patchy ill-defined bilateral alveolar consolidations, with peripheral distribution (c) Day 5: radiological worsening, with consolidation in the left upper lobe (d) Day 7: radiological worsening, with typical findings of acture respiratory distress syndrome (ARDS) [13]
3.2 Data pre-processing
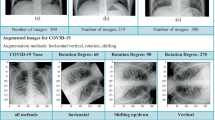
For further processing with the deep learning model, the chest X-ray images collected from the various sources are rescaled to a fixed size of \(224 \times 224\) pixels. Each image in the dataset is assigned with a label, which is one-hot encoded. As there is a fewer number of training samples are available to increase the generalizability of the learning model, we applied data augmentation to our data set. Data augmentation encloses a wide variety of methodology that is used to generate a new data sample from the original samples by doing small variation so that the original class label is not changed. Geometric Transformations support repeatability of the training samples to obtain suitable solutions [12, 22,23,24]. The geometric transformation applied to perform the data augmentations are rotation, horizontal shifting, vertical shifting, shear transformation, and horizontal flip. The parameters used to perform this data augmentation is given in Table 1:
In our experiment for resizing the image, we have also used aspect aware preprocessing to resize the image into a fixed size by maintaining the aspect ratio. We resize the image to \(224 \times 224\) pixels by resizing the shorter dimension first such that width is 224 pixels then crop the image along the height, such that height is 224 pixels. This technique allows our conventional neural network to learn more discriminative and consistent features.
3.3 The proposed transfer learning with CNN
The introduction of deep learning techniques has transformed the Artificial intelligence. The term deep in Deep learning describes the increasing number of layers in the network i.e., the presence of multiple hidden layers between the input and output. The model is defined after convolution, an operator in mathematics. A standard CNN architecture has more than one convolutional layer that extracts the rich and discriminative features from the input, a pooling layer to decrease the parameters and computations in the network, and a fully connected layer refers to the neural network. A CNN model is built by combining one or more above layers and perform a specific task by adjusting its internal parameters such as object detection, segmentation, and classification [6, 18].
Instead of generating a new deep learning framework from scratch, an alternative intelligent procedure is to create a model utilizing an already existing proven model. Therefore in our study for structuring the deep learning model, the VGG-16 model is chosen as the base model. VGG-16 was used in ILSVR (Imagenet) competition in 2014. Since then, it is considered one of the outstanding architecture for object detection. The uniqueness of this model is that it focused on the number of convolutional layers instead of the hyper-parameters. This model has convolution layers of \(3 \times 3\) filter with a stride 1, and padding is always the same. This model used a max pool layer of \(2 \times 2\) filter of stride two, and this order of convolution and max pool layers are constantly maintained throughout the architecture. The primary function of convolutional layer is to find out local conjunctions of features from the preceding layer and mapping their appearance to a feature map. In each layer, there is bank \(m_{1}\) filters. In our proposed model we have considered \(3 \times 3\) filter. the output \(Y_{i}\) of layer l consists of \(m_{1}\) feature maps of size \(m_{2} \times m_{3}\). The \(i^{th}\) feature map, denoted \(Y_{i}\) is computed as follows
where \(B_{i}^{l}\) is a bias matrix and \(K_{i,j}^{l}\) is the filter of size \(2h_{1}^{l} + 1 \times 2h_{2}^{l} + 1\) connecting the \(j^{th}\) feature map in layer \((l-1)\) with \(i^{th}\) feature map in layer.
We designed a deep learning model, where we performed a network surgery on the already existing proven model VGG-16. The model architecture is shown in Fig. 4.

Schematic representation of the proposed model
Before we replaced the head of the VGG-16 model, we define our fully-connected (FC) head, which is very simple compared to the original head of the VGG-16 model. The head of the VGG-16 model contains two sets of 4096 fully connected layers. In comparison to the base VGG-16 model, our head includes one set of 128 fully-connected layers succeeded by a dropout value of 0.5 and a softmax for output. Instead of replicating the original head of the network, we simplify it so that it will be easier to fine-tune the fewer head parameters. The architecture of our fully-connected layers is as follows:
Figure 5 shows the schematic representation of our proposed model with input and output parameters of each layer of the model. The bird’s-eye-view of the fine-tuned VGG-16 architecture is described in Algorithm 1.

To perform fine-tuning of our model, this newly build fully-connected head is put on the top of the base VGG-16 architecture. Each layer in the current FC head is initialized with random weights. However, as we have used a pre-existing already proven network as our base architecture, so our convolution layers have just learned rich and discriminative features, while our new FC network is initialized with some arbitrary weights. To avoid the risk of destroying the discriminative and rich features instead of allowing the gradient to propagate from these random values, we warm up our FC head by seizing every layer in the model’s body and enabling the gradient to backpropagate within the FC layers. After warming up our FC head, we unfroze all layers in the network body and allowed every layer fine-tuned. Unlike other state-of-the-art architecture, in this model features learned in one distributions (ImageNet dataset) is exploited to improve the generalization in another distribution(COVID-19 infection data). Also in this model we trained the complete architecture with our dataset by unfreezing all layers in the network body. Table 2 shows the layer details and layer parameters of the proposed model.

Block diagram of the proposed fine-tuned VGG-16 architecture
4 Experimental setup
4.1 Implementation details
Python programming used to design our model and fine-tune the parameters of the model. All experiments performed using a GeForce GTX 1080 Ti gaming GPU having ubuntu 16.04 operating system. The COVID-19 dataset split into training and testing sets with a ratio of 8:2. The training set partitioned into training and validation sets with 80% data in the training and 20 % data in the validation set. We constructed a new model using the body of the VGG-16 as the input and FC head model as the output. To perform the freezing of convolution layers the trainable parameters are made false for each layer in the base model. We have used the RMSprop optimizer with a lower learning rate \(10^{-3}\) to warm up our newly designed, fully connected head and trained our new FC head using our data augmentation method. Our initial objective was to warm up the FC head without changing the weights in the network’s body. We run the warm-up phase for 25 epochs to train the head. As the FC layers partially trained, we unfroze all convolution layers and trained the entire network from the beginning. In this situation, we need a warm start for training our model, so switched to the SGD optimizer with a learning rate of \(10^{-3}\) and continue the training. This time we allow our network to train over 100 epoch for finding the rich and discriminative features. Learning rate (\(l_{r}\)) plays a vital role in configuring a neural network. In our experiment, we investigate the effect of different learning rates on our model performance by a heuristic approach. It is recommended that for a fixed value of \(l_{r}\) if the training loss is not decreasing for the first few epochs, stop the training and adjust the \(l_{r}\). Figure 6 shows the schematic representation of our network surgery. Our dataset has more number of radiography images of class normal and pneumonia as compared to COVID-19 X-ray images, so to handle the class imbalance problem, we have used the weighted cross-entropy loss function. The normal cross-entropy loss contribution from the \(i^{th}\) training data is:
where \(x_i\) and \(t_i\) are the input features and the label. \(f(s_i)\) is the score of the model i.e., the probability that it is positive. As the positive COVID-19 cases are significantly lower than that of negative ones, we need equal contributions from each class. So to achieve this, we multiply each example from each class by a specific weight vector \(w_p\) and \(W_n\). To find this, we have used,
where,
Now after computing the weight our final weighted loss function is:
where, \(w_p\) and \(w_n\) are the weights of the positive and negative labels within each class

Block diagram of freezing and unfreezing of the convolutional (CONV) layers
4.2 Performance measure
The performance of our model evaluated using a K-fold cross-validation scheme, where k value is 5 [2]. In each fold, standard metrics such as precision, recall, F1-score, and accuracy calculated from the confusion matrix. Classification accuracy represents how often the classifier is correct. Precision represents how accurate is the classifier when predicting positive instances. It is a ratio of correctly predicted positive observation of the total predicted positive observation. Recall is the ratio of correctly predicted positive observations to all observations in the actual class “yes”. F1-score is the weighted average of Precision and Recall. The performance of the model also depends on the sensitivity and specificity value. Sensitivity represents a true positive rate, i.e., if a patient has the disease probability that the model predicts positive. Specificity represents a true negative rate, i.e., if a patient is a normal probability that the model predicts negative. We have also found out the positive predicted value (PPV) for each infection type. PPV value represents the probability that a patient has a disease if the model predicts positive.
Where,
For a two class classification having class labels disease and normal, model accuracy can be evaluated using the following formula:
5 Results and discussion
This section describes the representation of performance about our proposed model. This model is outlined for the diagnosis of COVID-19 cases from chest radiography images without the intervention of any radiologist. As the number of cases increases exponentially, this method may provide a second opinion to the radiologist for an accurate diagnosis. To measure the performance of our model quantitatively, test accuracy, sensitivity, and F1-score of the model are computed. We trained the network by considering the parameters mentioned in Table 3. Figure 7 shows the results of the confusion matrix for each fold, and Fig. 8 represents the training loss, validation loss, training accuracy, and validation accuracy of each fold of our experiment. Table 4 shows the standard metrics obtained for each class label of the COVID-19 dataset by the proposed model.We calculated the sensitivity, specificity and positive predicted value (PPV) for each infection type. Table 5 shows the results of sensitivity, specificity and PPV value for each class label of our proposed model.

Results of Confusion matrix for 5-fold cross validation: (a) fold1, (b) fold2, (c) fold3, (d) fold4, (e) fold5

Training loss,validation loss, training accuracy, validation accuracy of 5-fold cross validation:(a) fold1, (b) fold2, (c) fold3, (d) fold4, (e) fold5
Cohen et al. [5] has collated COVID-19 radiography images from different sources to develop an AI solution for accurate detection of COVID-19 cases. Most of the experiments studied in this article have used these images for the COVID-19 instance, and for cases such as pneumonia & normal, radiography images from different publicly available sources are collected. Many researchers endeavored various deep learning models and blended different methods to achieve better performance. The performance of the model not only depends on the accuracy, but it also depends upon the sensitivity and the PPV value of the model.
In this study, we have used the transfer learning techniques by considering VGG-16 as our base model for the classification of COVID-19 patients. We have considered a total of 1272 chest radiography images (COVID-19 (+) 147, Normal 525, Pneumonia 600) to build our framework. We achieved an accuracy of 97.12% with a sensitivity score of 99.2% for COVID-19 cases, which represents the “True positive rate”. The sensitivity obtained for three class label by our suggested model is higher as compared to other surveys present in this article. PPV value of our proposed model for the COVID-19 case is 97.0%, which represents if our proposed model predicts it as COVID-19 case, then the probability that a patient has the disease is 0.97. Table 6 shows the accuracy comparison of the article studied with our proposed model. From the results, it is observed that the accuracy obtained by our model for three class labels is outperformed the other models with higher PPV value.
The overall loss, accuracy of training, and validation of our model are presented in Fig. 9. The X-axis indicates epoch number, and Y-axis indicates loss and accuracy. Examining this figure, we can see that with an increase in the epoch, validation loss and training loss converges towards 0, and our training accuracy and validation accuracy continues to increase towards 1.

Overall training loss, Validation loss, training accuracy, validation accuracy of our proposed model
6 Conclusion
Prediction of COVID-19 disease in its initial phase is essential to obstruct the progress of this epidemic. In this article, we proposed transfer learning techniques with VGG-16 as our base model for diagnosing COVID-19 infection from publicly available chest radiography images. We built up a dataset from the publicly available chest radiography images that is comprised of 1,272 images from the three different classes to train our model. We performed a heuristic approach to fix the different hyper-parameters values for quick convergence of our model with an optimal solution. The model attained an overall accuracy of 97.12 % with sensitivity 99.2% for COVID-19 infection. There are a very few number of articles in the literatures that work with multiple classes. We compared the performance of our model to the state-of-the-art models described in literature survey. Performance result of our model yielded highest accuracy among the models under studies. Based on the results obtained from the experiment, it has been observed that the suggested model effectively extract the deep and discriminative features for automatic identification of COVID-19 infection.
The advantage of this model is that it is a low cost, does not require any feature extraction techniques for the classification of chest radiography images and might be an effective method to assist radiologist for diagnosis.
The significant shortcoming of this model is that it needs a a large volume of COVID-19 patient chest radiography images for effective model training.It is also required to design a model that can distinguish COVID-19 infection from related diseases such as SARS and MARS.
In the subsequent studies, we expect to validate our model by adding more radiography images. Also, we will provide the training time of the proposed architecture. We plan to develop an mobile application for instant diagnosis to help the patient immediately.
References
Apostolopoulos ID, Mpesiana TA (2020) Covid-19: automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Phys Eng Sci Med 43(2):635–640
Baliarsingh SK, Ding W, Vipsita S, Bakshi S (2019) A memetic algorithm using emperor penguin and social engineering optimization for medical data classification. Appl Soft Comput 85:105773
Bernheim A, Mei X, Huang M, Yang Y, Fayad ZA, Zhang N, Diao K, Lin B, Zhu X, Li K et al (2020) Chest ct findings in coronavirus disease-19 (covid-19): relationship to duration of infection. Radiology 200463
Chen N, Zhou M, Dong X, Qu J, Gong F, Han Y, Qiu Y, Wang J, Liu Y, Wei Y et al (2020) Epidemiological and clinical characteristics of 99 cases of 2019 novel coronavirus pneumonia in wuhan, china: a descriptive study. Lancet 395(10223):507–513
Cohen JP, Morrison P, Dao L, Roth K, Duong TQ, Ghassemi M (2020) Covid-19 image data collection: Prospective predictions are the future. arXiv preprint. arXiv: 2006.11988
Dorj U-O, Lee K-K, Choi J-Y, Lee M (2018) The skin cancer classification using deep convolutional neural network. Multimed Tools Appl 77(8):9909–9924
Gozes O, Frid-Adar M, Greenspan H, Browning PD, Zhang H, Ji W, Bernheim A, Siegel E (2020) Rapid ai development cycle for the coronavirus (covid-19) pandemic: Initial results for automated detection & patient monitoring using deep learning ct image analysis. arXiv preprint. arXiv: 2003.05037
Guan W-J, Ni Z-Y, Hu Y, Liang W-H, Ou C-Q, He J-X, Liu L, Shan H, Lei C-L, Hui DS et al (2020) Clinical characteristics of coronavirus disease 2019 in china. N Engl J Med 382(18):1708–1720
Hemdan EE-D, Shouman MA, Karar ME (2020) Covidx-net: A framework of deep learning classifiers to diagnose covid-19 in x-ray images. arXiv preprint. arXiv: 2003.11055
Huang C, Wang Y, Li X, Ren L, Zhao J, Hu Y, Zhang L, Fan G, Xu J, Gu X et al (2020) Clinical features of patients infected with 2019 novel coronavirus in wuhan, china. Lancet 395(10223):497–506
Hussain S, Khan A, Zafar M (2020) Coronavirus disease analysis using chest x-ray images and a novel deep convolutional neural network. 10.13140/Rg.2.2.35868.64646
Izonin I, Tkachenko R, Kryvinska N, Tkachenko P et al (2019) Multiple linear regression based on coefficients identification using non-iterative sgtm neural-like structure. In International Work-Conference on Artificial Neural Networks 467–479. Springer
Lorente E (2020) covid-19 pneumonia - evolution over a week
Mooney P (2020) kaggle chest x-ray images (pneumonia) dataset
Narin A, Kaya C, Pamuk Z (2020) Automatic detection of coronavirus disease (covid-19) using x-ray images and deep convolutional neural networks. arXiv preprint. arXiv: 2003.10849
Ng M-Y, Lee EY, Yang J, Yang F, Li X, Wang H, Lui MM-S, Lo CS-Y, Leung B, Khong P-L et al (2020) Imaging profile of the covid-19 infection: radiologic findings and literature review. Radiology: Cardiothoracic Imaging, 2(1):e200034
Ozturk T, Talo M, Yildirim EA, Baloglu UB, Yildirim O, Acharya UR (2020) Automated detection of covid-19 cases using deep neural networks with x-ray images. Comput Biol Med 121:103792
Pannu HS, Ahuja S, Dang N, Soni S, Malhi AK (2020) Deep learning based image classification for intestinal hemorrhage. Multimed Tools Appl 79:21941–21966
Rehman A, Khan FG (2020) A deep learning based review on abdominal images. Multimed Tools Appl 1–32
Roosa K, Lee Y, Luo R, Kirpich A, Rothenberg R, Hyman J, Yan P, Chowell G (2020) Real-time forecasts of the covid-19 epidemic in china from february 5th to february 24th, 2020. Infectious Disease Modelling 5:256–263
Sethy PK, Behera SK, Ratha PK, Biswas P (2020) Detection of coronavirus disease (covid-19) based on deep features and support vector machine
Tkachenko R, Doroshenko A, Izonin I, Tsymbal Y, Havrysh B (2018) Imbalance data classification via neural-like structures of geometric transformations model: Local and global approaches. In International conference on computer science, engineering and education applications 112–122. Springer
Tkachenko R, Izonin I (2018) Model and principles for the implementation of neural-like structures based on geometric data transformations. In International Conference on Computer Science, Engineering and Education Applications 578–587. Springer
Tkachenko R, Tkachenko P, Izonin I, Tsymbal Y (2018) Learning-based image scaling using neural-like structure of geometric transformation paradigm. In Advances in soft computing and machine learning in image processing 537–565. Springer
Udugama B, Kadhiresan P, Kozlowski HN, Malekjahani A, Osborne M, Li VY, Chen H, Mubareka S, Gubbay JB, Chan WC (2020) Diagnosing covid-19: the disease and tools for detection. ACS Nano 14(4):3822–3835
Wang L, Lin ZQ, Wong A (2020) Covid-net: A tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Sci Rep 10(1):1–12
Wang S, Kang B, Ma J, Zeng X, Xiao M, Guo J, Cai M, Yang J, Li Y, Meng X et al (2020) A deep learning algorithm using ct images to screen for corona virus disease (covid-19). MedRxiv
Wang W, Xu Y, Gao R, Lu R, Han K, Wu G, Tan W (2020) Detection of sars-cov-2 in different types of clinical specimens. Jama 323(18):1843–1844
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants performed by any of the authors.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Dash, A.K., Mohapatra, P. A Fine-tuned deep convolutional neural network for chest radiography image classification on COVID-19 cases. Multimed Tools Appl 81, 1055–1075 (2022). https://doi.org/10.1007/s11042-021-11388-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11388-9