
Abstract
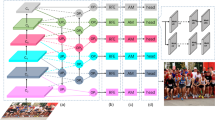
Expressive representations for characterizing face appearances are essential for accurate face detection. Due to different poses, scales, illumination, occlusion, etc, face appearances generally exhibit substantial variations, and the contents of each local region (facial part) vary from one face to another. Current detectors, however, particularly those based on convolutional neural networks, apply identical operations (e.g. convolution or pooling) to all local regions on each face for feature aggregation (in a generic sliding-window configuration), and take all local features as equally effective for the detection task. In such methods, not only is each local feature suboptimal due to ignoring region-wise distinctions, but also the overall face representations are semantically inconsistent. To address the issue, we design a hierarchical attention mechanism to allow adaptive exploration of local features. Given a face proposal, part-specific attention modeled as learnable Gaussian kernels is proposed to search for proper positions and scales of local regions to extract consistent and informative features of facial parts. Then face-specific attention predicted with LSTM is introduced to model relations between the local parts and adjust their contributions to the detection tasks. Such hierarchical attention leads to a part-aware face detector, which forms more expressive and semantically consistent face representations. Extensive experiments are performed on three challenging face detection datasets to demonstrate the effectiveness of our hierarchical attention and make comparisons with state-of-the-art methods.








Similar content being viewed by others


Notes
Some papers also call such boxes as “default boxes”. Since both default box and anchor box essentially indicate the same thing, hereinafter we use anchor box for consistency.
ImageNet pretrained models of ResNet are obtained from https://github.com/KaimingHe/deep-residual-networks.
Results of DCN are obtained with the official code from https://github.com/msracver/Deformable-ConvNets.
The results are obtained from the FDDB official website at http://vis-www.cs.umass.edu/fddb/results.html.
The results are obtained from WIDER FACE official website at http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/WiderFace_Results.html.
The results are obtained from UFDD official website at https://ufdd.info.
References
Alahi, A., Ortiz, R., & Vandergheynst, P. (2012). FREAK: Fast retina keypoint. In The IEEE conference on computer vision and pattern recognition (CVPR), pp. 510–517.
Alexe, B., Heess, N., Teh, Y. W., & Ferrari, V. (2012). Searching for objects driven by context. In Advances in neural information processing systems (NIPS), pp. 881–889.
Ba, J. L., Mnih, V., & Kavukcuoglu, K. (2015). Multiple object recognition with visual attention. In International conference on learning representations (ICLR).
Caicedo, J. C., & Lazebnik, S. (2015). Active object localization with deep reinforcement learning. In The IEEE international conference on computer vision (ICCV).
Chen, D., Ren, S., Wei, Y., Cao, X., & Sun, J. (2014). Joint cascade face detection and alignment. In European conference on compute vision (ECCV), pp. 109–122.
Chen, D., Hua, G., Wen, F., & Sun, J. (2016). Supervised transformer network for efficient face detection. In European conference on compute vision (ECCV), pp. 122–138.
Chen, L., Zhang, H., Xiao, J., Nie, L., Shao, J., Liu, W., Chua, T. S. (2017a). SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In The IEEE conference on computer vision and pattern recognition (CVPR).
Chen, Y., Song, L., & He, R. (2017b). Masquer hunter: Adversarial occlusion-aware face detection. arXiv:1709.05188
Dai, J., Li, Y., He, K., & Sun, J. (2016). R-FCN: Object detection via region-based fully convolutional networks. In Advances in neural information processing systems (NIPS), pp. 379–387.
Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., & Wei, Y. (2017). Deformable convolutional networks. In The IEEE international conference on computer vision (ICCV).
Ding, H., Zhou, H., Zhou, S. K., & Chellappa, R. (2018). A deep cascade network for unaligned face attribute classification. In The thirty-second AAAI conference on artificial intelligence (AAAI-18).
Farfade, S. S., Saberian, M., & Li, L. J. (2015). Multi-view face detection using deep convolutional neural networks. In International conference on multimedia retrieval (ICMR).
Felzenszwalb, P. F., Girshick, R. B., McAllester, D., & Ramanan, D. (2010). Object detection with discriminatively trained part-based models. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 32(9), 1627–1645.
Fu, J., Zheng, H., & Mei, T (2017) Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In The IEEE conference on computer vision and pattern recognition (CVPR).
Girshick, R. (2015). Fast R-CNN. In The IEEE international conference on computer vision (ICCV).
Gregor, K., Danihelka, I., Graves, A., Rezende, D., & Wierstra, D. (2015). Draw: A recurrent neural network for image generation. International Conference on Machine Learning (ICML), 37, 1462–1471.
Hao, Z., Liu, Y., Qin, H., Yan, J., Li, X., Hu, X. (2017). Scale-aware face detection. In The IEEE conference on computer vision and pattern recognition (CVPR).
Hara, K., Liu, M. Y., Tuzel, O., Farahmand, A. M. (2017). Attentional network for visual object detection. CoRR. arXiv:1702.01478
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In The IEEE conference on computer vision and pattern recognition (CVPR), pp. 770–778.
He, P., Huang, W., He, T., Zhu, Q., Qiao, Y., & Li, X. (2017). Single shot text detector with regional attention. In The IEEE international conference on computer vision (ICCV).
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Hoiem, D., Chodpathumwan, Y., & Dai, Q. (2012). Diagnosing error in object detectors. In European conference on compute vision (ECCV).
Hu, J., Shen, L., & Sun, G. (2018). Squeeze-and-excitation networks. In The IEEE conference on computer vision and pattern recognition (CVPR).
Hu, P., & Ramanan, D. (2017). Finding tiny faces. In The IEEE conference on computer vision and pattern recognition (CVPR).
Huang, C., Ai, H., Li, Y., & Lao, S. (2006). Learning sparse features in granular space for multi-view face detection. In The IEEE international conference on automatic face gesture recognition (FG), pp. 401–406.
Jain, V., Learned-Miller, E. (2010). FDDB: A benchmark for face detection in unconstrained settings. Technical report UM-CS-2010-009, University of Massachusetts, Amherst.
Jia, Y., Shelhamer, E., Donahue, J., Karayev, S., Long, J., Girshick, R., Guadarrama, S., & Darrell, T. (2014). Caffe: Convolutional architecture for fast feature embedding. In ACM international conference on multimedia (MM), pp. 675–678.
Jiang, H., & Learned-Miller, E. (2017). Face detection with the Faster R-CNN. In The IEEE international conference on automatic face gesture recognition (FG), pp. 650–657.
Jie, Z., Liang, X., Feng, J., Jin, X., Lu, W., & Yan, S. (2016). Tree-structured reinforcement learning for sequential object localization. In Advances in neural information processing systems (NIPS), pp. 127–135.
Le, V., Brandt, J., Lin, Z., Bourdev, L., & Huang, T. S. (2012). Interactive facial feature localization. In European conference on compute vision (ECCV), pp. 679–692.
Leutenegger, S., Chli, M., & Siegwart, R. Y. (2011). BRISK: Binary robust invariant scalable keypoints. In The IEEE international conference on computer vision (ICCV), pp. 2548–2555.
Li, H., Lin, Z., Shen, X., Brandt, J., & Hua, G. (2015). A convolutional neural network cascade for face detection. In The IEEE conference on computer vision and pattern recognition (CVPR).
Li, H., Liu, Y., Ouyang, W., & Wang, X. (2017a). Zoom out-and-in network with map attention decision for region proposal and object detection. CoRR. arXiv:1709.04347
Li, J., & Zhang, Y. (2013). Learning SURF cascade for fast and accurate object detection. In The IEEE conference on computer vision and pattern recognition (CVPR), pp. 3468–3475.
Li, J., Wei, Y., Liang, X., Dong, J., Xu, T., Feng, J., et al. (2017b). Attentive contexts for object detection. IEEE Transactions on Multimedia (TMM), 19(5), 944–954.
Li, Y., Sun, B., Wu, T., & Wang, Y. (2016). Face detection with end-to-end integration of a convnet and a 3D model. In European conference on compute vision (ECCV), pp. 420–436.
Lienhart, R., & Maydt, J. (2002). An extended set of haar-like features for rapid object detection. International Conference on Image Processing (ICIP), 1, 900–903.
Liu, C., & Shum, H. Y. (2003). Kullback-leibler boosting. In IEEE conference on computer vision and pattern recognition (CVPR), pp. 587–594.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016). SSD: Single shot multibox detector. In European conference on compute vision (ECCV), pp. 21–37.
Liu, Y., Li, H., Yan, J., Wei, F., Wang, X., & Tang, X. (2017). Recurrent scale approximation for object detection in CNN. In The IEEE international conference on computer vision (ICCV).
Mathe, S., Pirinen, A., & Sminchisescu, C. (2016). Reinforcement learning for visual object detection. In The IEEE conference on computer vision and pattern recognition (CVPR).
Mathias, M., Benenson, R., Pedersoli, M., Van Gool, L. (2014), Face detection without bells and whistles. In European conference on compute vision (ECCV), pp. 720–735.
Nada, H., Sindagi, V., Zhang, H., & Patel, V. M. (2018). Pushing the limits of unconstrained face detection: A challenge dataset and baseline results. CoRR. arXiv:1804.10275
Najibi, M., Samangouei, P., Chellappa, R., & Davis, L. S. (2017). SSH: Single stage headless face detector. In The IEEE international conference on computer vision (ICCV).
Osadchy, M., Miller, M. L., & Cun, Y. L. (2005). Synergistic face detection and pose estimation with energy-based models. In Advances in neural information processing systems, pp. 1017–1024.
Osadchy, M., Miller, M. L., & Cun, Y. L. (2005). Synergistic face detection and pose estimation with energy-based models. In Advances in neural information processing systems, pp. 1017–1024.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet large scale visual recognition challenge. International Journal of Computer Vision, 115(3), 211–252.
Sagonas, C., Tzimiropoulos, G., Zafeiriou, S., & Pantic, M. (2013). A semi-automatic methodology for facial landmark annotation. In The IEEE conference on computer vision and pattern recognition (CVPR) workshops.
Shih, K. J., Singh, S., & Hoiem, D. (2016). Where to look: Focus regions for visual question answering. In The IEEE conference on computer vision and pattern recognition (CVPR), pp. 4613–4621.
Shrivastava, A., Gupta, A., & Girshick, R. (2016). Training region-based object detectors with online hard example mining. In The IEEE conference on computer vision and pattern recognition (CVPR).
Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. CoRR. arXiv:1409.1556
Triantafyllidou, D., & Tefas, A. (2017). A fast deep convolutional neural network for face detection in big visual data. In INNS conference on big data, pp. 61–70.
Vaillant, R., Monrocq, C., & Cun, Y. L. (1994). Original approach for the localisation of objects in images (ip-vis). IEE Proceedings - Vision, Image and Signal Processing, 141(4), 245–250.
Viola, P., & Jones, M. J. (2004). Robust real-time face detection. International Journal of Computer Vision (IJCV), 57(2), 137–154.
Wang, H., Li, Z., Ji, X., & Wang, Y. (2017a). Face R-CNN. CoRR. arXiv:1706.01061
Wang, Y., Ji, X., Zhou, Z., Wang, H., & Li, Z. (2017b). Detecting faces using region-based fully convolutional networks. CoRR. arXiv:1709.05256
Wang, Z., Chen, T., Li, G., Xu, R., & Lin, L. (2017c). Multi-label image recognition by recurrently discovering attentional regions. In The IEEE international conference on computer vision (ICCV).
Wen, Y., Zhang, K., Li, Z., & Qiao, Y. (2016). A discriminative feature learning approach for deep face recognition. In European conference on compute vision (ECCV), pp. 499–515.
Wu, S., Kan, M., He, Z., Shan, S., & Chen, X. (2017). Funnel-structured cascade for multi-view face detection with alignment-awareness. Neurocomputing, 221, 138–145.
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., & Bengio, Y. (2015). Show, attend and tell: Neural image caption generation with visual attention. In International conference on machine learning (ICML), pp. 2048–2057.
Yan, J., Lei, Z., Wen, L., & Li, S. Z. (2014). The fastest deformable part model for object detection. In IEEE conference on computer vision and pattern recognition (CVPR), pp. 2497–2504.
Yang, B., Yan, J., Lei, Z., & Li, S. Z. (2014). Aggregate channel features for multi-view face detection. In The IEEE international joint conference on biometrics (IJCB), pp. 1–8.
Yang, S., Luo, P., Loy, C. C., & Tang, X. (2015). From facial parts responses to face detection: A deep learning approach. In The IEEE international conference on computer vision (ICCV).
Yang, S., Luo, P., Loy, C. C., & Tang, X. (2016a). WIDER FACE: A face detection benchmark. In The IEEE conference on computer vision and pattern recognition (CVPR).
Yang, S., Xiong, Y., Loy, C. C., & Tang, X. (2017). Face detection through scale-friendly deep convolutional networks. CoRR. arXiv:1706.02863
Yang, Z., He, X., Gao, J., Deng, L., & Smola, A. (2016b). Stacked attention networks for image question answering. In The IEEE conference on computer vision and pattern recognition (CVPR), pp. 21–29.
Ye, Q., Yuan, S., & Kim, T. K. (2016). Spatial attention deep net with partial pso for hierarchical hybrid hand pose estimation. In European conference on compute vision (ECCV), pp. 346–361.
Yu, D., Fu, J., Mei, T., & Rui, Y. (2017). Multi-level attention networks for visual question answering. In The IEEE conference on computer vision and pattern recognition (CVPR).
Yu, J., Jiang, Y., Wang, Z., Cao, Z., & Huang, T. (2016). UnitBox: An advanced object detection network. In ACM on multimedia conference (MM), pp. 516–520.
Zafeiriou, S., Trigeorgis, G., Chrysos, G., Deng, J., & Shen, J. (2017). The Menpo facial landmark localisation challenge: A step towards the solution. In The IEEE conference on computer vision and pattern recognition (CVPR) workshops.
Zaremba, W., & Sutskever, I. (2014). Learning to execute. CoRR. arXiv:1410.4615
Zhang, C., Zhang, Z. (2014). Improving multiview face detection with multi-task deep convolutional neural networks. In The IEEE winter conference on applications of computer vision (WACV), pp. 1036–1041.
Zhang, K., Zhang, Z., Li, Z., & Qiao, Y. (2016). Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Processing Letters (LSP), 23(10), 1499–1503.
Zhang, S., Zhu, X., Lei, Z., Shi, H., Wang, X., & Li, S. Z. (2017a). FaceBoxes: A cpu real-time face detector with high accuracy. In The IEEE/IAPR international joint conference on biometrics (IJCB).
Zhang, S., Zhu, X., Lei, Z., Shi, H., Wang, X., & Li, S. Z. (2017b) \(\text{S}^3\)FD: Single shot scale-invariant face detector. In The IEEE international conference on computer vision (ICCV).
Zhang, S., Yang, J., & Schiele, B. (2018). Occluded pedestrian detection through guided attention in cnns. In The IEEE conference on computer vision and pattern recognition (CVPR).
Zheng, H., Fu, J., Mei, T., & Luo, J. (2017). Learning multi-attention convolutional neural network for fine-grained image recognition. In The IEEE international conference on computer vision (ICCV).
Zhu, C., Zheng, Y., Luu, K., & Savvides, M. (2017). CMS-RCNN: Contextual multi-scale region-based CNN for unconstrained face detection. In B. Bhanu & A. Kumar (eds.), Deep learning for biometrics (pp. 57–79). Cham: Springer.
Zhu, X., & Ramanan, D. (2012). Face detection, pose estimation, and landmark localization in the wild. In IEEE conference on computer vision and pattern recognition (CVPR), pp. 2879–2886.
Acknowledgements
This research was supported in part by the National Key R&D Program of China (No. 2017YFA0700800), Natural Science Foundation of China (Nos. 61390511, 61650202, 61772496 and 61402443).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Xiaoou Tang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wu, S., Kan, M., Shan, S. et al. Hierarchical Attention for Part-Aware Face Detection. Int J Comput Vis 127, 560–578 (2019). https://doi.org/10.1007/s11263-019-01157-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-019-01157-5