
Abstract
As the number of cores in chip multiprocessors (CMPs) increases, cache coherence protocol has become a key issue in integration of chip multiprocessors. Supporting cache coherence protocol in large chip multiprocessors still faces three hurdles: design complexity, performance and scalability. This paper proposes Cache Coherent Network on Chip (CCNoC), a scheme that decouples cache coherency maintenance from processors and shared L2 caches and implements it completely in network on chip to free up processors and shared L2 caches from the chore of maintaining coherency, thereby reduces design complexity of CMPs. In this way, CCNoC also improves the performance of cache coherence protocol through reducing directory access latency and enhances scalability by avoiding massive directories overhead in shared L2 caches. In CCNoC, coherence state caches and active directory caches are implemented in the network interface components of network on chip to maintain cache coherence states for blocks in L1 caches and manage directory information for recently accessed blocks in L2 caches respectively. CCNoC provides a scalable CMP framework to tackle cache coherency which is the foundation of CMP. This paper evaluates the performance of CCNoC. Experimental results show that for a 16-core system, CCNoC improves performance by 3% on average over the conventional chip multiprocessor and by 10% at best, while reduces storage overhead by 1.8% and saves directory storage by 88%, showing good scalability.
Similar content being viewed by others

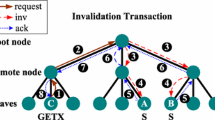
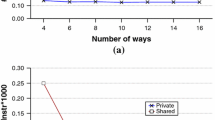
References
International technology roadmap for semiconductors. http://public.itrs.net, 2009.
Tomasevic M, Milutinovic V. Tutorial on the Cache Coherency Problem in Shared-Memory Multiprocessor: Hardware Methods. IEEE CS Press, 1993.
http://www-128.ibm.com/developerworks/power/library/paexpert1.html.
Agarwal A, Simoni R, Hennessy J et al. An evaluation of directory schemes for cache coherence. In Proc. the 15th Int. Symp. Comp. Arch., Honolulu, USA, May 30-June 2, 1988, pp.280–289.
Culler D E, Singh J P, Gupta A. Parallel Computer Architecture: A Hardware/Software Approach. Second Edition, Harcourt Asia Pte Ltd., 2002.
Dally W J, Towles B. Route packets, not wires: On-chip interconnection networks. In Proc. the 38th Design Automation Conference (DAC 2001), Las Vegas, USA, June 18–22, 2001, pp.684–689.
Guerrier P, Greiner A. A generic architecture for on-chip packet-switched interconnections. In Proc. the Design Automation and Test in Europe (DATE), Paris, France, March 27–30, 2000, pp.250–256.
Benini L, De Micheli G. Networks on chip: A new SoC paradigm. IEEE Computer, 2002, 35(1): 70–78.
Eisley N, Peh L S, Shang L. In network cache coherence. In Proc. the 39th International Symposium on Microarchitecture (MICRO 2006), Orlando, Florida, December 9–13, 2006, pp.321–332.
Mizrahi H E et al. Introducing memory into the switch elements of multiprocessor interconnection networks. In Proc. the 16th Int. Symp. Comp. Arch., Jerusalem, Israel, May 28-June 1, 1989, pp.158–166.
Iyer R, Bhuya L N. Switch cache: A framework for improving the remote memory accesslatency of CC-NUMA multiprocessors. In Proc. the 5th Int. Symp. High Performance Computer Architecture, Orlando, USA, Jan. 9–12, 1999, pp.152–160.
Iyer R, Bhuyan L N, Nanda A. Using switch directories to speed up cache-to-cache transfers in CCNUMA multiprocessors. In Proc. the 14th International Symposium on Parallel and Distributed Processing, Cancun, Mexico, May 1–5, 2000, pp.721–728.
Gupta A, Weber W, Mowry T. Reducing memory traffic requirements for scalable directory-based cache coherence schemes. In Proc. Int. Conference on Parallel Processing (ICPP 1900), Urbana-Champaign, USA, August 13–17, 1990, pp.312–321.
Nanda A, Nguyen A, Michael M, Joseph D. High-throughput coherence controllers. In Proc. 6th Int. Symposium on High-Performance Computer Architecture (HPCA-6), Toulouse, France, Jan. 10–12, 2000, pp.145–155.
Michael M, Nanda A. Design and performance of directory caches for scalable shared memory multiprocessors. In Proc. the Fifth International Conference on High Performance Computer Architecture (HPCA-5), Orlando, USA, Jan. 9–12, 1999, pp.142–151.
Acacio M E, Gonzalez J, Garcia J M, Duato J. An architecture for high-performance scalable shared- memory multiprocessors exploiting on-chip integration. IEEE Trans. Parallel and Distributed Systems, 2004, 15(8): 755–768.
Ros A, Acacio M E, García J M. A novel lightweight directory architecture for scalable shared-memory multiprocessors. In Proc. Euro-Par 2005 Parallel Processing, Lisboa, Portugal, Aug. 30-Sept. 2, 2005, pp.582–591.
Ros A, Acacio M E, Garcí M J. An efficient cache design for scalable glueless shared-memory multiprocessors. In Proc. the 3rd Conference on Computing Frontiers, Ischia, Italy, May 3–5, 2006, pp.321–330.
Cho S, Jin L. Managing distributed shared L2 caches through OS-level page acclocation. In Proc. 39th Int. Symp. Microarchitecture, Orlando, Florida, USA, Dec. 9–13, 2006, pp.455–468.
Zhang M, Asanovic K. Victim migration: Dynamically adapting between private and shared CMP caches. MIT Technical Report, MIT-CSAIL-TR-2005–064, MIT-LCS-TR-1006, October, 2005.
Zhang M, Asanovic K. Victim replication: Maximizing capacity while hiding wire delay in tiled chip multiprocessors. In Proc. the 32nd Int. Symp. Computer Architecture, Madison, USA, June 4–8, 2005, pp.336–345.
Chaiken D, Fields C, Kurihara K, Agarwal A. Directory-based cache coherence in large-scale multiprocessors. Computer, 1990, 23(6): 49–58.
Martin M M K, Sorin D J, Beckmann B M, Marty M R, Xu M, Alameldeen A R, Moore K E, Hill M D, Wood D A. Multifacet’s general execution-driven multiprocessor simulator (GEMS) toolset. Computer Architecture News, 2005, 33(4): 92–99.
Woo S, Ohara M, Torrie E, Singh J, Gupta A. The SPLASH-2 programs: Characterization and methodological considerations. In Proc. the 22nd Int. Symp. Computer Architecture, Santa Margherita Ligure, Italy, June 22–24, 1995, pp.24–36.
Author information
Authors and Affiliations
Corresponding author
Additional information
This work is supported by the National Natural Science Foundation of China under Grant Nos. 60970002, 60833004, 60773146, and 60673145.
Rights and permissions
About this article
Cite this article
Wang, JL., Xue, YB., Wang, HX. et al. CCNoC: Cache-Coherent Network on Chip for Chip Multiprocessors. J. Comput. Sci. Technol. 25, 257–266 (2010). https://doi.org/10.1007/s11390-010-9322-4
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11390-010-9322-4