
Abstract
Our ability to understand users constrains our ability to design, create, and develop for them new ways of interfacing with technology. In turn, our ability to measure and derive insights from user behavior in real-world environments constrains our ability to truly understand them and how they will use the technology we develop for them. The psychological sciences (broadly defined) remain steadfastly locked in a tradition of experimental artifice—they make sense of our observations of humans by artificially constraining the environment (the laboratory) and human experience (experiments). However, the rate at which real-world endeavors are finding analogous virtualized platforms (e.g., entertainment, productivity, and sociality) is dramatically increasing; people are using software for more aspects of their lives than ever. This presents new measurement opportunities because software is a tool, and if we can instrument tools while they are used to perform tasks, then we can understand how humans approach those tasks. In this way, software is a new, virtualized medium for understanding real-human behavior in new compelling ways that bridge the gap between foundational research in the psychological science and applied research in the fields of human computer interaction (HCI). In this review paper, we will describe advances in gathering meaningful data from human in software environments and how it may be used to improve how people interface with their technology, understand cognition, as well as our understanding of people.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
In this paper, we review literature, methods, and technologies related to capturing high-resolution user activity in order to make inferences about user cognition. Beyond a direct benefit to the Human Computer Interaction (HCI) community, there is much deeper benefit to be had. Namely, bridging gaps in the psychological sciences for understanding human beings in real-world environment (even if they are virtual environments). If those gaps can be bridged, we might see far future advances in how humans can connect to their technology in the near future. A key theme in this paper is that the psychological sciences will not close these gaps alone. In fact, lacking the requisite skill-set and the technology, the psychological sciences will depend on HCI community to understand people in the virtual environments that they live, work and play in. Most importantly, it will be the HCI community that capitalizes on the knowledge we gain about people in real-world (virtual) environments to build new ways of interfacing with technology that everyone will benefit from.
2 (Psychological) Science and Technology
Science is a method for generating knowledge. Currently, it’s the best one we have. Two things that people forget about science are that (1) Francis Bacon laid the groundwork for scientific principles of falsification, replication, and generalizability in the same source text [1], and (2) he did not necessarily believe in knowledge for its own sake. In fact, Bacon was pretty clear on the added value of science to human kind and the value he saw was in the science’s ability to shape the world through technology.
“The making of great scientific discoveries seems to have a pride of place among human discoveries… Why? Because the benefits of scientific discoveries can extend to the whole of mankind, and can last for all time… This is nowhere more obvious than … the arts of printing, gunpowder, and the natural compass… there seems to have been no empire, no philosophical system, no star that has exerted greater power and influence in human affairs than these mechanical discoveries”
-Francis Bacon, Novum Organum (1620), Aphorism 129
To Bacon, it wasn’t enough to generate knowledge, even though he gave us a very good method for doing so (science). It’s equally, if not more important to use scientific discoveries to push the human condition forward through technology that exploits those discoveries. This point is built into the scientific method, into what we call today generalizability—that we can’t understand the nature of a thing in the thing itself and we must make our scientific inquiries as general as possible to really understand the limits and conditions of the natural principles we discover. This is very difficult in the psychological sciences.
Bacon recognized that to make progress in generating knowledge, our findings need to be replicable—discoveries need to be repeated, and observations need to be made more than once—in order to safeguard that they aren’t a fluke. Generalizability falls right out of that—that we can replicate discoveries under different conditions. It’s clear that Bacon never saw psychology coming. Psychology is unique in that what we are trying to observation is the mind, but it is not a thing we can point to in the natural world or gauge with a direct sensor. It’s this fact that makes replicability and generalizability very difficult for the psychological science; defining measures of the mind is difficult because the mind, per se, has no physical referent. So make sacrifices are made in service of science, but at a disservice to developing useful technology.
The psychological sciences sacrifice generalizability in order to make measurements. We call this compromise “the laboratory”, or maybe experimental control. In the laboratory, how people experience stimuli and the conditions under which they experience them can be rigidly controlled. The laboratory itself is a test-medium, a metaphorical bath-tub full of water that people can be passed through to understand their qualities. Sometimes studies send people out into the world with technology to provide reports on how they’re feeling at random intervals during the day. This is a step closer to generalization. However, it is important to note that even then it’s those reports that are observed and neither actual feelings, nor any real behaviors are observed upon which their actual feelings and thoughts could be inferred. It’s this inability to measure real-behavior and the control exerted over experience, in service of measurement that constrains generalizable research. In turn, this makes it very difficult to lean on the knowledge created by to psychological sciences to create technology that might better the human condition. New measurement opportunities exist, however, in software environments. With these opportunities the field of HCI will take the lead in facilitating a deeper understanding of human behavior and cognition, and developing new, advanced technology that capitalizes on this understanding.
3 Software Is the New Human Measurement Medium
Alex (Sandy) Pentland at MIT’s Human Dynamics Lab did something very ambitious. He and his team led by Nadav Aharony instrumented research participants with mobile devices (e.g., smart phones) that captured how those participants interact with one another—when they were proximal to one another and how much time they spent in that state—and how they interacted with other social and marketing media. They sent these participants back into the “wild” and let them interact with one another and their phones. Ambition is a good thing and through their Friends and Family study, Dr. Pentland and his colleagues were able to track human behavior in the wild and predict things like social contagion (e.g., “meme” spread), buying preferences, and other great things [2]. Almost more important than their findings in the Friends and Family study and other notable investigations [3, 4] was what they were able to accomplish in terms of measuring real people, doing real things in the real-world. It’s also worth noting that was first accomplished by a few psychologists working with computer and data scientists and not psychologists alone, even though the same technology (e.g., Bluetooth-enabled phones with SDKs) was available many years earlier.
Dr. Pentland and his colleagues made real progress on the front of how to capture real world human behavior in the real world. His insight to use the technology that people bring with them into the real-world to enable real-world measurement was simple and elegant. This is extremely clever, in fact, because it highlights a thing about humans that is very important and often taken for granted: humans use tools. There are those that effectively argue that humans’ ability to be social and to use sociality itself as a tool to further their agendas is the sine qua non of the human condition [5]. This is probably true, but our knack for using and inventing new tools to shape our environment is part of a much older lineage and is likely convoluted with a number of other socio-cognitive feats that humans pride themselves on [6]. Software is a tool that people use to perform myriad tasks in myriad real-world environments and proving the value of exploiting software for the purpose of understanding people well is the very brilliant thing that Dr. Pentland demonstrated so well.
As of 2013, US persons spend an estimated average of 37 h per month using smartphone applications and browsers, another 27 h per month using the internet on personal computers, and 133 h per month watching live television [7]. Each of these environments are now mediated (almost fully) by some software interface. That’s nearly 40% of human waking hours plugged into virtual, but real, environments for entertainment, commerce, and productivity. More importantly, that’s nearly 40% of human endeavors that we can capture through software environments. So, why haven’t the psychological scientists seized on this opportunity?
Since Dr. Pentland’s research, some psychologistshave started to capitalize on virtual mediums as ways to understand human behavior in real-world environments. In addition to getting increasingly clever about using mobile devices to administer questionnaire methods, and the like [8,9,10], they are also trying to understand publically available data in communities like Facebook and Twitter [11,12,13,14]. What they aren’t doing, however, highlights a missing voice at the table of the psychological sciences and a skill-set that is sorely missing from the field—that of the Human Computer Interface (HCI) researcher. What they aren’t doing is two-fold: (1) turning dynamic user activity data into models of human behavior and cognition and (2) using the design of software tools to solicit behavior from humans so that we can learn more from them. The third thing to note is that HCI researchers and practitioners are in the perfect position to make good on a deeper, generalized understanding of humans in ubiquitous software environments by developing technology that exploits this understanding to benefit everyone; they are best positioned to cover these gaps as they live in the bridge between software and humans, and in the bridge between software and the value that humans take from it.
4 Making Software a Sensor for Human Behavior
In the bulk of psychological research studies that have explored human behavior native to software environments, data collection is generally restricted to artifacts of software use, rather than the use itself. The difference is large and important. An artifact of software use might be subscribing to research participants’ Twitter, Instagram, or Facebook feed. These are the things that are left behind in software environments, and while they are descriptive of human behavior in these environments, at an aggregate level, they are not themselves behavior. Even in Dr. Pentland’s research, mobile devices were “instrumented” in so far as Bluetooth and sensor data (e.g., accelerometer, etc.) were recorded. However, participants purchasing history was collected through credit card statements given over by participants, and social media data was collected by opting into a Facebook “scraping” application [2].
By analogy, capturing artifacts of human behavior in software environments is like an archeological approach to studying to human behavior—we can learn from people by studying the tools, art, and literature they leave behind. However, the real opportunity for understanding the human mind or cognition in software environments is, by analogy, watching how the tools, art, and literature are made. This is a key philosophical and methodological gap that very often prevents research in the psychological sciences from meeting criteria for generalizability—artifacts are, by definition, firmly rooted within the context in which they emerge. The skills, processes, and behaviors that create artifacts are, however, portable and repurposed across contexts. Measuring the former, and not the latter is a road map toward generalizable scientific research that could culminate into technology for large-scale consumption and use.
In software environments, every action initiated by users and software (e.g., automation) can be logged and recorded, in real-time. So, rather than restricting data collecting to what people leave behind in software environments, we can collect on how users search through other Tweets before they respond or compose new content, or how much time they spend editing their profile. The question of how—the process—with which people use tools to perform tasks and how their immediate context shapes that process and informs the artifacts produced is the important one. It is process where information pertaining to learning, memory, attention, perception, reasoning, and decision-making lives; these are the hallmarks of cognition and how the mind works [15]. Can software act as a sensor to capture behavior rich enough to make strong inferences about the cognitive processes underlying that behavior?
A software sensors’ output is a software log—of user or system changes. Logging user activities for a variety of use-cases is not a new idea. From keystroke logging, to mouse logging, and click-counting, numerous studies have used this data for purposes ranging from usability analysis to workload monitoring [16,17,18,19]. Software development kits (SDKs) and application program interfaces (APIs) are now so commonplace, that virtually anyone with some competency in a relevant programming language can build “hooks” into an application, or “instrument” software, so that user activities can be collected. There are even myriad commercial and open-source approaches for collecting user activity logs. However, each of these approaches fall short of capturing cognition.
There are three reasons why approaches fall short of accurately capturing behavior: (1) specificity, (2) context, (3) labeling. Specificity refers to whether user activity logs contain sufficient information to capture behavior as it unfolds over time. By analogy: if user behavior is the signal, and software is the sensor, do the channels through which sensor data is collected have sufficient information to recreate behavior? Context refers to other information present at the time user behavior that is useful for isolating various behaviors. Sometimes in order to improve signal-to-noise-ratio (SNR), other information is needed to deconvolute one signal from another. Labeling refers to turning machine readable user activity logs into human readable logs. This is a problem of semantics—conceptually mapping user behavior activity to cognitive processes. Without a humanized understanding of the signal, we have no way of comparing different types of behavior and the various conditions under which it is samples. Without that we can’t understand humans in our own terms.
We take a signal processing approach to the problems described above. Over the course of nearly 5 years of research and development, we have made some progress in solving them, at least as they pertain to user activity modeling in graphic user interfaces (GUIs) for productivity applications. Our best guidance for aspiring psychological scientists within the field of HCI is to take the simile of software as a sensor very seriously.
-
1.
Specificity is fundamentally a discrimination problem. If users are interacting with data analytics application, for example, we need to be able to understand how they interact (and across) different elements of that application in a software logging scheme if we are to replicate their actual behavior. We might think about this in the same terms we think about the sensitivity and discriminatory power of survey question items—whether each item uniquely captures specific information and their redundancy with other items. To illustrate, Google Analytics makes a good “straw-man”. Google Analytics (and other “tag” management interfaces) doesn’t require that all activities are uniquely, or fully specified. If only a subset of application features are reporting user activities, then we lose critical data for interpreting users’ choice of activity given the range of choices they have. In this respect, we need to capture all user activities, which includes both user events (e.g., inputs) as well as the elements with which those events are nested—this is the anatomy of an activity. This is critical for understanding decision-making, attention, which in turn are key for understanding how people experiment and learn [20, 21]. Put differently, if we’re to understand how a tool is used to perform a task, then we need to understand the degrees of freedom with which to the tool can be applied. With this information, however, then behavioral data can be used to inform decision science.
A second point about specificity: we need to be able to finely discriminate within elements. Google Analytics has a very simple Category-Action-Label-Value structure in their logging schema [22]. In the application of this schema, developers will apply category inputs that are either too granular (e.g., button label), or too general (e.g., “button”), depending on their needs. In many cases this makes it difficult to discern user activities between elements. This prevents us from being able to make a full and accurate account to collecting rich-enough user activity logs to be able to recreate human behavior in software environments.
We have made progress in addressing this gap as part of the Apache Software as a Sensor project. Our solution for both web and thick-client productivity applications is to simply log every user event, the target GUI element that event targeted, and how that GUI element is nested among others (e.g., Document Object Model). Our logging service—the User Analytic Logging Engine (UserALE)Footnote 1 collects all this data, cursor position, as well as key-strokes. This provides a comprehensive open-source data stream for replicating human behavior from logs collected in situ [23].
-
2.
Context aids in how to interpret user activity data. Context helps answer the question as to why users might have behaved a certain way and can often take the form of other data that can be fused with user activity data. For example, feedback to the user through a GUI can offer context for how users might engage in recursive behavior or how patterns of use might become more systematic overtime through feedback-driven reinforcement learning. Analogously, we might think about context as though they were independent variables or experimental factors, which given context to dependent variable behavior in an experimental design. Context is very difficult to capture in software, but far easier than capturing context in the real world.
In order to capture context effectively, we need access other data exposed to the user through the software. While this can be difficult given varied data formats used by applications, a key consideration that can help simplify data fusion is time. Like any sensor synchronization effort, developing a software sensor requires that each user activity log is accurately time-stamped so that other sources of data can be co-registered. In this respect, in order to be useful user activity logs need be represented as a time-series. This is relatively commonplace in any logging framework (system or user log frameworks). However, capturing both client-side timing, as well as a logging server clock time, provides a way of reconciling the timing of other data received from other services (e.g., context data) that may be operating on different clocks.
-
3.
Labeling, as noted, is a matter of semantics. How best to apply human-readable labels to user activity logs, is typically proscribed by the use-case for analyzing user activity logs. For example, in previous versions of UserALE, we experimented with labeling each user activity log with a corresponding analytic workflow process label, given that this version was developed for data analytic applications. The important thing to note here is that labels should be fluid—in order to make more generalized inferences from behavior in software behavior, we must be able to relabel data so that data collected from different use-cases can be analyzed together or at least compared (Fig. 1).
Fig. 1. 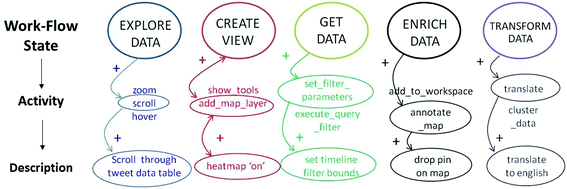
Semantic labels incorporated into logging schemas fail in implementation and scale

In the early version of the UserALE logging scheme we asked too much of developers: they were to assign mutually exclusive labels to each software event that ascribed semantic meaning relevant to users’ analytic workflow to each pair of user activity and the GUI element target. To our chagrin, we found that these labels were applied inconsistently by developers, making those semantic labels useless in analysis—user activity and target element data remained useful, however. Our insight, which we offer here, is that user activity logs should be collected and stored in a raw machine-readable format, which can then be labeled with human-readable logs ex post facto, and relabeled as needed through either manual or automated processes (e.g., Machine Learning). This provides a way to make logging more useful from an informational perspective and provides the ability to scale that real generalizable science requires. There are other advantages to collecting user activity log data in a portable, machine-readable data in formats, which we will discuss in other sections.
Making inferences about the mind-at-work is about capturing a human process. Currently, the psychological sciences largely constrain themselves to capturing the outputs of human process—performance metrics, work products, and artifacts left in the wake of process. The information from process is much richer and ripe for modeling behavior in such a way as to make inferences about cognition clearer and a path toward generalization and invention more navigable.
The first step to achieving an understanding of how people use software tools in service of understanding what how reveals about cognition is capturing process-level data through software instrumentation. Yes, this is possible. However, standard guidelines and design principles are needed for portable log formats that both meet requisite needs for specific use-cases, and yet at scale can accumulate into a large corpus of data for conducting scientific analyses. Of course, the next step is what to do with process data once you’ve collected it. Fortunately, there has been some progress made there, too.
5 Modeling and Making Sense of Process
Software logs in service of capturing cognition (at least as proscribed above) contain three different kinds of information—time, space, and opportunity. Formally speaking, software user activity logs are categorically specified, sequential event data, nested within a time-series. Time indicates when events took place as well as the distance between one step in a sequence and the next. Space indicates where in the GUI users’ efforts were allocated, or rather what element of the GUI effort was directed toward. Finally, opportunity indicates where users did not go or where they could go next. These are all essential elements of modeling user activities from which inferences about cognition or, more coarsely mental states can be made. There is much work left to do in order to get cognition from behavior. However, below we describe a few approaches that are different in how they use this information to understand people.
One approach we’ve seen is a frequentist accounting of what humans do. Here we refer to “click-counting” or other aggregations of specific user interactions within GUIs that are expressed as a rate, count, mean or variance [17, 24,25,26,27,28]. These approaches are very often used to infer “cognitive states”Footnote 2 such as stress (an arousal/anxiety state), frustration, or cognitive load [29] (the extent to which some task requires mental effort beyond the implicit task demands). The information we are using to compute metrics (e.g., click-rate) that we might use to infer cognitive state can be said to implicate time and space in GUIs. However, the use of time and space information is used strictly for aggregation. What we are really modeling in this way is simply user effort out, not process. Sometimes metrics like these are useful when we need a continuous data stream to correlate with some other measure as it pertains to an evaluation. But, this approach aggregates otherwise rich data into oblivion, sacrificing a true accounting of human behavior in service of performance metrics. We advocate for a different approach—one where you can model human behavior and have your metrics, too.
If software is a sensor for human processes, then models are different perspectives of what that signal looks like, emphasizing different dimensions. Purely aggregative approaches can be said to be models only in so far as we are fitting a simplified (or fused) data stream into a simple distribution of values and describing that distribution with simple measures of central tendency and distributional width. By definition, aggregation reduces the amount information into a single dimension. We advocate that researchers not start with this step, but rather start by building rich models of behavior that account for space, time and opportunity, then follow by aggregating model features to produce continuous metrics for whatever purpose. Below is an example:
Rather than purely emphasizing the amount of activities users pour into a GUI, we sought to understand how users’ effort was distributed across different elements in the GUI, in time, and how these different allocations changed throughout tasks with analytic (productivity) applications. We envisioned these allocations as states of a human-computer system, or different strategies users might take to interacting with the applications, where we could observe those states changing into others: a Markovian process. The trouble with Markov Models is that they are typically one-off—each different user by application pairing represents a different system that needs to be modeled separately. This would result in “apples to oranges” comparisons between users, which means that we wouldn’t have sufficient context to understand what those states mean. So, we adapted a Bayesian approach to Hidden Markov Models [30] to suite our needs. The result was a Beta-Process Hidden Markov (BPHMM) modeling approach that is largely unsupervised and allows us to assign each user to states within a global library of states that characterize how an entire ensemble of users allocate effort across the application. The result was pretty interesting (Fig. 2).

“Wiggle” game used in BPHMM pilot
In a pilot study, using a rudimentary user activity logging schema applied to a simple video game (something like Bejeweled). Our research participants (users) were told that in the game could acquire points, and their goal was to figure out how to acquire as many points as they could, but we did not tell them how to acquire points. They were tasked to explore how to put together different user activities and elements and learn the rule of the game through trial and error. We then applied this modeling technique to user activity data collected, in situ, during their task.
Our models illustrate how user behavior coalesce into strategies (states), emphasizing different patterns of use of each of the different elements in the game. Strategies can be described in a multinomial plot describing the relative probability of observing each availability, relative to one another. These states are bounded by time, and while the modeling solution produces a single global state-space across users, each users’ transition probability between the various state remains unique (Fig. 3).

BPHMM example usage state
This isn’t cognition either, but it is a solution for accurately accounting for how users make use of the space in applications, how that usage changes with time, and importantly, what features of GUIs users did and didn’t use (opportunity). We were able to compute metrics describing the distributional aspects of each the states. We computed a measure of each states’ kurtotic qualities—whether effort was distributed across different elements or focused on specific elements. Classifying states in this way, we then tabulated the percentage of time users spent in one type of state or another. For our purposes at the time, we hypothesized that users who spent the most in states emphasizing a single activity (GUI element) didn’t really evidence an understanding of how different activities fit together to produce points. Our results indicate that our hypotheses was not false. Almost unequivocally, participants who were incorrect in reporting the rule for getting points they were tasked to discover spent their time in these states [30]. The time users spent in these states was also correlated with their post-task reports of workload and mental effort (cognitive load), and the likelihood that participants transitioned from these states to other states of this kind reported less of a proclivity for exploring complex problem (need for cognition). Finally, we found that the predictive power of this metric over self-reported task difficulty exceeded that of simple activity-rate calculations.
In our current work, we’re focusing on a different dimension of user process: sequence. Specifically, we are using extensible graph models and methods derived from genetic subsequence analysis to understand how users individually and en masse chain activities together to complete tasks with data analysis applications. Using graph metrics like betweenness-centrality and others, we are able to show how various features of GUIs are centroids of use, gating the flow of user effort from one part of the application space to others. This modeling approach has been reduced to practice and embedded in the open-source Apache Software as a Sensor project. At present, we’re replicating and extending our state- and sequence-based findings in actual data analytic applications that people use [31], as well as finding other applications for the rich data in user activity logs to improve signal to noise ratio in other sensor data (e.g., physiological data) [32] (Fig. 4).

The “Bowie” plot for visualizing graph workflow metrics
State and sequence are different and powerful modeling approaches for understanding behavior, but they aren’t quite cognition either. It’s worth asking what will cognition look like? Will we know it when we see it? We believe it will take many forms. The brain is a complex system of many networks composed of the same sub-networks. The overarching network of activity in the brain is constantly adapting with new sensory inputs modifying previous network states and shaping or biasing the basis for future network states [33, 34]. Behavioral models of cognition will likely look similar because job number 1 of the brain is to coordinate behavior.
What is presently missing from our ability to model behavior and make strong inferences about cognition is context. Context—information users are exposed to during software use—is the hardest thing to capture in software environments, for both technical reasons and because it’s very difficult to label context in order to understand whether it represents, for example, feedback from some other process and whether that feedback was reinforcing or whatever. But with context, we can turn models of user activity into the basis for decision- and learning-science. Context gives use stimulus-response cases for why users change their frequency of use of certain aspects of application space. It gives us change-points within a time-series, and a way of inferring whether a selection between different elements of a GUI represents an opportunity taken or simple habit. That being said, the corpus of signal processing and modeling approaches at our disposal today is probably sufficient for capturing cognition, even while our ability to capture and effectively label context is not.
6 HCI Will Lead Progress Toward Cognitive Modeling
We believe that the psychological sciences will not naturally move to a methodological framework for capturing human behavior process from software environments, even though they are increasingly apt to explore human behavioral artifacts in these environments. Their widespread inclusion of neurotechnologies and mobile devices is evidence of their readiness to adopt new technology [35, 36], but evidence is lacking to suggest that they themselves innovate new technologies in support of scientific inquiry. This is mostly due to the fact that historical trends in the psychological sciences promote training targeted at producing more psychologists that will practice in academic environments. Outside of industry, these psychologists will be reinforced based on a throughput of research studies at small scales to support a steady stream of publications that in turn provide a commodity for advancement, etc. Promising new trends see the psychological sciences selecting new students and post-docs with programming skills in Python, Ruby, and other languages that lend themselves well to building technology that will shape research methods to come. But, they are not there yet.
We believe that HCI researchers will pave the way to fully realize the opportunity for measuring human behavior in ubiquitous software environments, for a number of reasons. First, HCI researchers have motivation to capture human process given a field wide focus on human cognition, how humans digest information in digital environments, and how best to minimize and ameliorate the burdens placed on users by poorly engineered digital technology. Whereas, psychologists may settle for capturing artifacts of human behavior, a distinct focus on the process through which humans efficiently produce work is a hallmark of HCI. Second, HCI researchers have many of the requisite skill sets needed to build upon and improve apparatus for collecting data with the quality needed for high resolution behavioral modeling. Third, HCI researchers have been acquiring new skills related to large scale data analysis owing to growth in commercial tools for user event logging and the resultant blend between HCI and digital marketing enterprises.
Most importantly, HCI is a technology focused field. In addition to innovating new methods and techniques for understanding human in real-world environments, HCI researchers are best positioned to transition understanding into technology for widespread use. With access to users and their needs, HCI is positioned to become the new field of applied psychology. Rather than the clinician/practitioner model that currently occupies the largest segment of applied psychology, HCI would add a much needed segment of technologists. As these HCI technologists improve methods to capture and quantify behavioral process in service of developing technology, they will in turn be creating new methodologies and apparatus that improve the quality and generalizability of foundational research in the psychological sciences.
Notes
- 1.
For code, documentation and demonstrated of the Apache Software as a Sensor user activity logging capability, visit http://senssoft.incubator.apache.org.
- 2.
Cognitive States aren’t the same thing as cognition, which is how we process information, decide, select actions, not how we feel at any given time (affect has states) but it’s has a lot of domain relevance to HCI.
References
Bacon, F.: Novum Organum. Clarendon press, Oxford (1878)
Aharony, N., et al.: Social fMRI: investigating and shaping social mechanisms in the real world. Pervasive Mob. Comput. 7(6), 643–659 (2011)
Montjoye, Y.-A., Quoidbach, J., Robic, F., Pentland, A.: Predicting personality using novel mobile phone-based metrics. In: Greenberg, A.M., Kennedy, W.G., Bos, N.D. (eds.) SBP 2013. LNCS, vol. 7812, pp. 48–55. Springer, Heidelberg (2013). doi:10.1007/978-3-642-37210-0_6
Pentland, A.: Social Physics: How Good Ideas Spread-the Lessons from a New Science. Penguin, New York (2014)
Byrne, R., Whiten, A.: Machiavellian intelligence: Social Expertise and the Evolution of Intellect in Monkeys, Apes, and Humans. Oxford Science Publications, Oxford (1989)
Matsuzawa, T.: Primate foundations of human intelligence: a view of tool use in nonhuman primates and fossil hominids. In: Matsuzawa, T. (ed.) Primate Origins of Human Cognition and Behavior, pp. 3–25. Springer, Tokyo (2008)
Nielsen: The US Digital Consumer Report (2014). http://www.nielsen.com/us/en/insights/reports/2014/the-us-digital-consumer-report.html. Accessed 16 Oct 2015
Berkman, E.T., Graham, A.M., Fisher, P.A.: Training self-control: a domain-general translational neuroscience approach. Child. Dev. Perspect. 6(4), 374–384 (2012)
Berkman, E.T., Falk, E.B., Lieberman, M.D.: In the trenches of real-world self-control neural correlates of breaking the link between craving and smoking. Psychol. Sci. 22(4), 498–506 (2011)
Berkman, E.T., Lieberman, M.D.: What’s outside the black box?: The status of behavioral outcomes in neuroscience research. Psychol. Inq. 22(2), 100–107 (2011)
Falk, E.B., et al.: Social network structure modulates neural processes involved in successful communication and message propagation. In: 21st Annual Meeting of the Cognitive Neuroscience Society, Boston (2014)
Falk, E.B., Way, B.M., Jasinska, A.J.: An imaging genetics approach to understanding social influence. Front. Hum. Neurosci. 6, 168 (2012)
Bayer, J., et al.: Facebook in context(s): measuring emotional responses across time and space. New Media Soc. 1461444816681522 (2016)
Schmaelzle, R., et al.: Brain connectivity dynamics during social interaction reflect social network structure. bioRxiv. 096420 (2017)
Neisser, U.: Cognition and Reality: Principles and Implications of Cognitive Psychology. WH Freeman/Times Books/Henry Holt & Co., New York (1976)
Boi, P., et al.: Reconstructing user’s attention on the web through mouse movements and perception-based content identification. ACM Trans. Appl. Percept. (TAP) 13(3), 15 (2016)
Durkee, K.T., et al.: System decision framework for augmenting human performance using real-time workload classifiers. In: 2015 IEEE International Multi-disciplinary Conference on Cognitive Methods in Situation Awareness and Decision. IEEE (2015)
Holzinger, A.: Usability engineering methods for software developers. Commun. ACM 48(1), 71–74 (2005)
Preece, J., Rombach, H.D.: A taxonomy for combining software engineering and human-computer interaction measurement approaches: towards a common framework. Int. J. Hum Comput Stud. 41(4), 553–583 (1994)
Rolls, E.T.: Memory systems in the brain. Annu. Rev. Psychol. 51(1), 599–630 (2000)
Glimcher, P.W., Fehr, E.: Neuroeconomics: Decision Making and the Brain. Academic Press, London (2013)
Google, I.: Anatomy of events. https://support.google.com/analytics/answer/1033068?hl=en#Anatomy. Accessed 27 Feb 2017
Apache, User Analytic Logging Engine (UserALE.js), The Apache Software Foundation
Hill, R.G., Sears, L.M., Melanson, S.W.: 4000 clicks: a productivity analysis of electronic medical records in a community hospital ED. Am. J. Emerg. Med. 31(11), 1591–1594 (2013)
Rodrigues, M., Gonçalves, S., Carneiro, D., Novais, P., Fdez-Riverola, F.: Keystrokes and clicks: measuring stress on e-learning students. In: Casillas, J., Martínez-López, F., Vicari, R., De la Prieta, F. (eds.) Management Intelligent Systems. AISC, vol. 220, pp. 119–126. Springer, Heidelberg (2013). doi:10.1007/978-3-319-00569-0_15
Xu, K., et al.: Analytic provenance for sensemaking: a research agenda. IEEE Comput. Graph. Appl. 35(3), 56–64 (2015)
Brown, J., et al.: Characterizing mission and user context for proactive decision support. In: Proceedings of the Human Factors and Ergonomics Society Annual Meeting. Sage Publications (2016)
Jones, R.M., et al.: Using cognitive workload analysis to predict and mitigate workload for training simulation. Procedia Manuf. 3, 5777–5784 (2015)
Ayres, P., Paas, F.: Cognitive load theory: new directions and challenges. Appl. Cognitive Psychol. 26(6), 827–832 (2012)
Mariano, L.J., et al.: Modeling strategic use of human computer interfaces with novel hidden Markov Models. Front. Psychol. 6 (2015)
Poore, J., et al.: Modeling strategic use of human computer interfaces II: addressing critical methodological shortcoming in understanding human behavior in ubiquitous software environments (In Preparation)
Poore, J.C., et al.: Operationalizing engagement with multimedia as user coherence with context. IEEE Trans. Affect. Comput. 8, 95–107 (2016)
Buzsaki, G.: Rhythms of the Brain. Oxford University Press, Oxford (2009)
Buzsáki, G., Draguhn, A.: Neuronal oscillations in cortical networks. Science 304(5679), 1926–1929 (2004)
Ochsner, K.N., Lieberman, M.D.: The emergence of social cognitive neuroscience. Am. Psychol. 56(9), 717 (2001)
Lieberman, M.D.: A social cognitive neuroscience approach. Soc. Judgm. Implicit Explicit Process. 5, 44 (2003)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Poore, J., Vincent, E., Mariano, L. (2017). Software as a Medium for Understanding Human Behavior. In: Kurosu, M. (eds) Human-Computer Interaction. User Interface Design, Development and Multimodality. HCI 2017. Lecture Notes in Computer Science(), vol 10271. Springer, Cham. https://doi.org/10.1007/978-3-319-58071-5_5
Download citation
DOI: https://doi.org/10.1007/978-3-319-58071-5_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-58070-8
Online ISBN: 978-3-319-58071-5
eBook Packages: Computer ScienceComputer Science (R0)