
Abstract
The current web APIs are end-user centric as they mostly focus on the end results. In this paper, we break this paradigm for one class of scientific workflow problems —machine translation, by designing an API that caters not only to the end users but also allows researchers to find bugs in their systems by exposing the ability to programmatically manipulate the results. Moreover, it follows an easy to replicate workflow based mechanism, which is built on the concept of microservices.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Machine translation (MT) systems are one of the scientific workflows which are extensively used by the researchers and industry; and they comprise of multiple components such as NER Engine, Lexical Transfer, Transliteration, etc. However, the existing systems follow a monolithic design that are not only static in nature but are difficult to debug.
We introduce a service-oriented architecture (SOA) for building scalable, distributed MT systems using composable distributed objects— microservices hosted in easily deployable containers. Our approach exposes components in these workflows through a simple API allowing the end users to easily construct and experiment with new systems. Our architecture builds on the approaches AnnoMarket [3], LetsMT! [5], and NLPCurator [8] by exposing microservices that not only allow access to intermediate results within a workflow, but also allow their modification. Moreover, our approach does not restrict microservices to a specific set of tools as they can be dynamically added at any point of time, during MT’s life-cycle. Besides this, our proposed is not only limited to MT workflows, but can be easily adopted to any generic workflow.
In this paper, we describe our architecture and demonstrate its application to existing MT pipelines for a certain set of Language Pairs from Sampark [1]Footnote 1.
2 System Design and Architecture
The existing MTs’ design are inspired from monolithic architecture that use well-factored, independent modules within a single application. However, these modules are tightly coupled to a code base [7] and in most cases, are not amenable for reuse. Further, it may not be possible to build new workflows using existing modules developed by different sources due to software dependency conflicts and incompatible interfaces between them. We take a service-oriented architecture (SOA) based micro-distributed approach (microservice [4]) that bundles multiple independent tasks that are easy to deploy, scale and test. For example, in our system, the Urdu POS Tagger is one such microservice. We thwart the problem of monolithic approach by encapsulating the modules inside containers, which run as microservices and interact via the RESTful API. These microservices can be deployed on a cluster of inter-connected machines either in a public or a private cloud. Resource allocation and load balancing can be done at the granularity of microservices leading to a truly scalable distributed architecture.
2.1 The RESTful API
REpresentational State Transfer (REST) is an architectural style inspired by the web. This architecture provides many implementation options [6] including HTTP which uses verbs to easily state and formulate microservices as resources. We expose a simple, yet powerful API to end users where, whatever the translation task, queries are represented as HTTP POST requests of the form:

For example, to get the output up to running the Shallow Parser in our Hindu-Urdu pipeline, the POST request is structured as http://$a/hin/urd/1/10. If additional parameters are required, we pass them as additional POST parameters. Information about available language pairs in the entire system is exposed at http://$a/langpairs. The number of modules for a particular language pair are accessible via a simple GET request to http://$a/$b/$c, and the sequence of modules is available at http://$a/$b/$c/modules. A simple GET request to http://$a/$b/$c/translate should suffice, if the user wants a translation without the knowledge of submodules. All responses by the serverFootnote 2 are in JSON format.

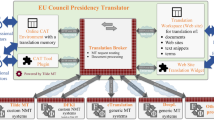
An overview of the system architecture
2.2 Architecture Walkthrough
Our system architecture comprises of containers. We deploy our system using Docker Swarm Footnote 3 with the help of a multi-host Overlay Footnote 4 network. Each node in this cluster is either a microservice, or a load balancer for multiple instances of a single microservice (Fig. 1). For example, for an MT system with X well defined, isolated modules, we use at least \(X+1\) containers in the setup. The additional container hosts the public API end point. This container also holds the information about the next set of pre-defined/default modules of that scientific workflow. But the system is flexible enough to allow user to override the sequence with the route /translate/graph. All other microservices are oblivious of their position in the workflow sequence. Inside each container, the developers can write the submodules in any programming language, which are glued together and exposed as a single microservice using an HTTP server created using a REST wrapper (we use the Mojolicious FrameworkFootnote 5). A generic, minimal working setup has been further explained at https://github.com/nehaljwani/ddag-sample.
3 The Client
We built a browser-based clientFootnote 6 for querying exposed pipeline components. After sending the input text to the tokenizer, the JavaScript callbacks asynchronously process each sentence in parallel. The client auto-detects the input language, maintains the ordering of input sentences, and provides two key features: direct editing of target translations using JQuery IME; and direct modification of intermediate pipeline outputs and resuming the pipeline which we call ResumeMTFootnote 7. This open sourceFootnote 8 client can be used for any language pair and is not necessarily limited to Indic Languages. The proposed APIFootnote 9 has also been integrated with Kathaa [2]Footnote 10, in a fashion where the Kathaa backend acts as a REST aggregator for all services, where, each node is processed independently.
4 Conclusion
We demonstrated an API with a browser based client as well as with a framework for creating workflows in NLP. Our approach is built on cloud-based services and an architecture that is not only easily deployable and distributed, but also resilient and composable for other NLP applications, and easier to maintain. In future, we will introduce a shared docker repository to host independent modules and a meta-language to automate the distributed setup based on a given configuration.
Notes
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
References
Sampark: Machine translation among Indian languages (2016). http://sampark.iiit.ac.in/sampark/web/index.php/content. Accessed 10 Feb 2016
Mohanty, S.P., Wani, N.J., Srivastava, M., Sharma, D.M.: Kathaa: a visual programming framework for NLP applications. In: Proceedings of the Demonstrations Session, NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego California, USA, 12–17 June 2016, pp. 92–96. The Association for Computational Linguistics (2016)
Tablan, V., Bontcheva, K., Roberts, I., Cunningham, H., Dimitrov, M.: AnnoMarket: an open cloud platform for NLP. In: Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 19–24. Association for Computational Linguistics, Sofia, Bulgaria, August 2013. http://www.aclweb.org/anthology/P13-4004
Thones, J.: Microservices. IEEE Software 32(1), 116 (2015). http://dx.doi.org/10.1109/MS.2015.11
Vasiļjevs, A., Skadiņš, R., Tiedemann, J.: Letsmt!: cloud-based platform for do-it-yourself machine translation. In: Proceedings of the ACL 2012 System Demonstrations, pp. 43–48. Association for Computational Linguistics, Jeju Island, Korea, July 2012. http://www.aclweb.org/anthology/P12-3008
Webber, J., Parastatidis, S., Robinson, I.: REST in Practice: Hypermedia and Systems Architecture, 1st edn. O’Reilly Media, Cambridge (2010). http://amazon.com/o/ASIN/0596805829/
Woods, D.: Enterprise Services Architecture. O’Reilly Media, Sebastopol (2003). https://books.google.co.in/books?isbn=0596005512, ISBN 10: 0596005512
Wu, H., Fei, Z., Dai, A., Sammons, M., Roth, D., Mayhew, S.: ILLINOISCLOUDNLP: text analytics services in the cloud. In: Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S. (eds.) Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC 2014), pp. 14–21. European Language Resources Association (ELRA), Reykjavik, Iceland, May 2014. aCL Anthology Identifier: L14–1504
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Wani, N.J., Mohanty, S.P., Purini, S., Sharma, D.M. (2017). Anuvaad Pranaali: A RESTful API for Machine Translation. In: Drira, K., et al. Service-Oriented Computing – ICSOC 2016 Workshops. ICSOC 2016. Lecture Notes in Computer Science(), vol 10380. Springer, Cham. https://doi.org/10.1007/978-3-319-68136-8_20
Download citation
DOI: https://doi.org/10.1007/978-3-319-68136-8_20
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-68135-1
Online ISBN: 978-3-319-68136-8
eBook Packages: Computer ScienceComputer Science (R0)