
Abstract
In this paper, we present the indoor 3D pipeline of an assistive system for visually impaired people, whose goal is to scan the environment, extract information of interest and send it to the user through haptics and sounds. The particularities of indoor scenes, containing man-made objects, with many planar faces, led us to the idea of developing the 3D object recognition algorithms around a planar segmentation, based on normal vectors. The 3D pipeline starts with acquiring depth frames from a range camera and synchronized IMU data from an inertial sensor. The pre-processing stage computes normal vectors in the 3D points of the scanned environment and filters them to reduce the noise from the input data. The next stages are planar segmentation and object labeling, which divides the scene into ground, ceiling, walls and generic objects. The whole 3D pipeline works in real-time on a consumer laptop at approximately 15 fps. We describe each step of the pipeline, with the focus on the labeling stage, and present experimental results and ideas for further improvements.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The research in the sensory substitution domain has experienced a spectacular growth in recent years. In particular, the plethora of available consumer 3D cameras has led to an increased interest for the development of new computer vision based assistive systems. In this context, we propose fast algorithms on the CPU and GPU for the basic labeling of indoor scenes, with the purpose of helping visually impaired people navigate in unknown environments. There are two main technologies that estimate the distance from camera to surrounding objects: structured light and time-of-flight (ToF). Both technologies have a series of limitations, such as sensor error which increases with the distance to the objects and the impossibility of estimating the depth for reflective surfaces or for highly illuminated scenes. Another category of 3D cameras is the one based on stereovision. However, in indoor scenes, where there is a lack of texture (for example, in case of walls or big objects that have the same color), the structured light or ToF cameras are more reliable. In the first stage of the project we evaluated a series of acquisition devices, based on their capabilities and their form factor and we decided to choose the Structure Sensor camera, due to its reduced dimensions, light weight and its acceptable performance, which is similar to that of Kinect version 1.
The system acquires depth images from the Structure Sensor and information about camera rotation from an inertial sensor (LPMS). The information obtained from the two devices is synchronized based on the timestamps of the frames. The pre-processing stage computes normal vectors in the 3D points of the point cloud. The point cloud is obtained by transforming positions (x, y, depth) from the depth map in the camera space, based on the camera’s intrinsic parameters. A very important step in the pipeline is the segmentation of the scene into planar surfaces. The output of the segmentation is afterwards merged into objects that are labeled based on their geometric properties. The steps of the pipeline are detailed in Sect. 3.
In the following section, we provide a short survey of indoor labeling methods. Next, the algorithms of our pipeline are described in detail. In the last sections, we present experimental results and draw the conclusions.
2 State of the Art
Most assistive systems for visually impaired people acquire images from a video camera and process them by employing geometric based heuristics or through machine learning.
Stoll et al. [1] perform a simple conversion of depth images into sounds: they down-sample the depth map by averaging the values of the pixels from a neighborhood. Each cell in the new depth map is encoded into a sound which is loud if the object is close and soft if the object is far away. Blessenohl et al. [2] employ geometric heuristics based on local normal vectors for ground and wall detection. Taylor et al. [3] perform edge detection, planar segmentation, and then identify ground and walls with simple heuristics. Liu et al. [4] propose an obstacle detection method for RGB-D images which identifies the ground with a multi-scale voxel plane segmentation. Next, the obstacles are detected through region-growing and by using context information.
Lai et al. [5] use sliding window detectors on the pixels in a RGB-D image and combine the results with geometric properties for object indoor labeling. Wang et al. [6] tackle the problem of insufficient 3D training data for machine learning detection algorithms and propose a Support Vector Machine (SVM) based scheme to transfer 2D existing image labels to point clouds. Kim et al. [7] propose the use of Conditional Random Fields (CRF) over voxels obtained from a 3D point cloud. Anand et al. [8] extract geometric features from processed 3D point clouds and use a maximum-margin learning method [9] for contextually guided semantic labeling and object search. Lai et al. [10] introduce the HLP3D classifiers and use Markov Random Fields (MRF) to detect both small objects and large furniture. Wang et al. [11] perform a graph-based planar segmentation and train cascade decision trees to detect ground, walls and tables. The See ColOr system [12] uses a detecting and tracking hybrid algorithm that learns the properties of natural objects through a training phase. Huang et al. [13] build patches from a 3D point cloud and use geometric features such as coplanarity and color coherence for the grouping of patches into objects. Deng et al. [14] propose the incorporating of global co-occurrence constraints, relative height relationship constraints and local support relationship constraints into a CRF for semantic segmentation of RGBD images. Gupta et al. [15] perform contour detection, bottom-up grouping, object detection and scene classification by training an additive kernel SVM. Yang et al. [16] use both geometric modeling and machine learning for indoor scene understanding. Usually, artificial intelligence-based systems have a better accuracy, but require a lot of manually annotated training data and introduce a heavy computational load.
3 3D Processing Algorithms
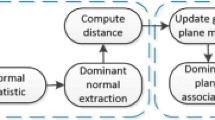
The proposed workflow is described in Fig. 1 and detailed in this section.

Workflow of our 3D processing
3.1 Pre-processing
As previously mentioned, the input from structured light cameras is noisy and contains areas with un-sampled pixels. Therefore, the filtering of the input data is of utmost importance. The problem of the un-sampled pixels can be solved with an inpainting algorithm [17]. Several inpainting methods have been implemented and tested, but were not included in the final pipeline, because the obtained improvements were too small in comparison with the computational load.
The normal estimation is the basis for the planar segmentation. The point cloud obtained from a depth camera is organized, in the sense that there is a one to one correspondence between the pixels in the depth map and the points in the point cloud. The camera intrinsic parameters allow for the computation of a 3D point in camera space, from the pixel position in image space. In this paper, we use the terms ‘pixel’ and ‘point’ interchangeably, due to this correspondence. If two points are neighbors in image space, then they are also neighbors in camera space, if their depths do not vary considerably. This property of the point cloud allows for a very fast estimation of the normal vector of each point in the depth map. In the simplest estimation algorithm, the normal is computed as the cross product of two tangential vectors which are determined based on finite differences. The first tangential vector connects the left neighbor and right neighbors of the current point. The second tangential vector connects the bottom neighboring point with the upper one.
The noise of the depth map makes it impossible to use only the closest neighbors in the normal estimation. Therefore, several improvements are proposed. First, we perform the computation of the tangential vectors on a sparse multi-scale neighboring window. This method uses pixels from different distances on the X and Y axes, averaging the length of the obtained tangential vectors and computing sample normals as cross product over these averages. The sparse neighborhood allows for a fast computation, while the multi-scale sampling reduces the noise. The normal filtering is also performed on a neighboring window. The algorithm analyses all the normals inside a neighborhood of the current point. The filter rejects normal samples based on the average inside that neighborhood and on the standard deviation. The final normal is obtained as a Gaussian weighted sum of the normal vectors that were not rejected [18].
3.2 Planar Segmentation
The planar segmentation consists of two steps: a region growing step that connects pixels with the same properties in initial surfaces and a region merging step that combines initial surfaces with similar statistic properties into bigger surfaces.
Region Growing.
The region growing method performs a scanline traversal of all the pixels in the depth map. The current pixel is investigated, in comparison with its upper-left, upper, upper-right and left neighbors. A cost function is computed for each neighbor, based on the depth and normal vector. The cost function represents a weighted sum of the difference in depth between the current pixel and its neighbor and the difference in normal between the current pixel and the surface containing the neighbor. This cost also takes into account the depth error of the acquisition device, which increases with the distance to the camera. After computing the similarity costs of the pixel with its neighbors, we determine the neighbor with the minimum associated cost. If this minimum cost is lower than a given threshold, the current pixel is added to the region containing the correspondent neighbor. During the region growing step we also determine the adjacency of the surfaces. Two surfaces are considered adjacent if at least two pixels, one from the first surface and one from the second surface, are neighbors, and their depth values do not differ significantly.
Region Merging.
The region growing step is very sensitive to noise, leading thus to an over-segmentation. The region merging step solves this problem to some extent. The region growing outputs 3D planar surfaces. These surfaces can be further merged based on their statistic properties. We compute the average normal and position of the surface, as the averages of all the points in the surface. The average normal vectors represent a good metric for the comparison of two surfaces. Another good metric for comparing two adjacent surfaces is the distance from the position of the camera, i.e., (0, 0, 0) in camera space, to the theoretic plane that contains the current surface. The equation of the plane containing a surface can be computed based on the average normal N̅ (x N , y N , z N ) and the average position P(x p , y p , z p ) of the points inside that surface.
The similarity cost between two surfaces, S 1 and S 2, is computed as a weighted sum of the difference in normal, C normal , and the difference in distance from the camera to the theoretic plane containing each surface, C dist . If this similarity cost is lower than a given threshold, then the surfaces are merged into a bigger surface. The region growing step is an iterative process, while this region merging is recursive, following a BFS traversal. A more detailed description of the segmentation algorithm, together with some experimental results, is given by Morar et al. [18].
3.3 Labeling
The input of the labeling stage consists of a vector of planar surfaces, an adjacency map for these surfaces, and a segmentation map, i.e. an array with the resolution of the depth image which contains for each pixel the ID of the surface it belongs to. In this step, we merge surfaces into objects and add them to one of the following categories: ground, ceiling, walls and generic objects. Next, we filter the objects that will be sent to sound and haptic encoding, based on user options.
Ground.
In world space coordinates, the ground stands on a horizontal plane which is positioned at the lowest y coordinate, in a system where the Y axis is oriented upwards. However, in camera space, the situation is a bit different, due to the orientation of the camera. The inertial sensor allows the computation of the normal vectors in world space. The normal of a horizontal surface in world coordinates is close to (0, 1, 0). If the dot product between the average world normal of a surface and the (0, 1, 0) vector is bigger than a given threshold, then that surface is considered horizontal.
For a stable ground detection, we employ inter-frame consistency and identify the most suitable ground candidates based on the ground surfaces detected in the previous frames. We compute a similarity cost between each horizontal surface and the ground surfaces obtained in the previous frame. This cost depends on the difference in normal, the intersection of the surfaces and the difference in distances from the camera to the planes containing the surfaces. The intersection of the surfaces is computed based on the number of pixel pairs (P 1, P 2), both having the same x and y coordinates in image space, one belonging to the surface from the current frame and the other to the surface from the previous frame. This intersection cost is normalized with the number of pixels contained by each surface, as in [18]. If the similarity cost for a horizontal surface and one of the ground surfaces from the previous frame is smaller than a threshold, then the current horizontal surface is marked as a candidate for ground.
The next step is the detection of the first ground region. We consider the ground to belong to the horizontal plane with the biggest distance to the camera, d max . The distance d for a region R is computed in camera space, based on its average position, (x R , y R , z R ), and the reference vertical normal for the current frame, N̅v (x Nv , y Nv , z Nv ):
N̅v is the vertical normal in world space, i.e., (0, 1, 0), multiplied by the camera orientation matrix obtained from the IMU. d is a signed distance, positive for horizontal regions below the (XOZ) plane and negative for the ones above (XOZ).
Figure 2 illustrates this heuristic: R 3 is detected as the first ground region, because it has the biggest distance, d 3, from the camera to its theoretic plane, P R3.

Example of horizontal regions (R 1, R 2, R 3) which enter the ground heuristic. Region R 3 is the best ground candidate (it has the lowest y coordinate, y 3, in world space, i.e., the biggest negative distance from the camera to its theoretic plane, P R3)
We then compute the difference between the d max and each of the distances from the camera to the planes corresponding to the other horizontal surfaces. If the difference is lower than a given threshold T Gstrict , then the current horizontal surface is also marked as belonging to the ground. The surfaces that were marked as ground candidates in the inter-frame consistency step have a high probability of belonging to the ground. Therefore, the conditions for these surfaces are a little bit more relaxed, with the use of the threshold T Grelaxed instead of T Gstrict . All the ground surfaces are merged into a single ground object and take the id of the ground object from the previous frame.
Ceiling.
The heuristic for ceiling is very simple. All the surfaces with the average world normal close to (0, −1, 0) and a distance to the ground higher than a threshold are considered to belong to the ceiling object.
Walls.
The walls are usually big objects perpendicular to the ground. However, the region growing and merging algorithms could still lead to over-segmentation, especially when the walls are not perpendicular to the view direction. Therefore, in the first step of the wall detection we merge adjacent surfaces which are perpendicular to the ground into bigger vertical objects. The surfaces are merged only if their average normal vectors are similar and if the difference in distances from the camera to their corresponding theoretic planes is lower than a threshold. Since the normal is very sensitive to noise, even after a lot of filtering, the distance from the camera to the theoretic plane of a surface is also sensitive. Therefore, when comparing two adjacent surfaces that have similar orientation (similar average normal vectors), we don’t use their own normal vectors to compute the distance, but we obtain a combined normal, weighted based on the size of each surface. If N 1 is the normal of the first surface, which contains |S 1| pixels, and N 2 is the normal of the second surface, containing |S 2| pixels, then the average normal is computed as follows:
The next step in the wall detection is identifying the most probable wall candidates based on interframe consistency. A similarity cost is computed for each vertical object from the current frame with all the wall objects from the previous frame. If the minimum cost is lower than a given threshold, then the current vertical object takes the ID of the wall object from the previous frame corresponding to this minimum cost and is added to the most probable wall candidates. The heuristic for walls is also very simple. If the size of a vertical object or if its height is big enough, then that object is considered a wall. We compute the width and height in camera space of each vertical object, based on the bounding box in image space. We determine the bottom-left and upper-right corners of the bounding box and compute the 3D positions of these points, C 1(x c1, y c1, z avg ) and C 2(x c2, y c2, z avg ), taking into account the average depth of the object, z avg . The difference on the Y axis, |y c1− y c2|, represents the height of the object in camera space. The width is computed differently. For example, a wall that is not perpendicular to the camera direction could have a very small width in image space, even if in reality it would have a big width, unfolded on the Z axis in camera space. We therefore compute the width of the object based on the difference of C 1 and C 2 on the X axis, but also on the difference between the maximum and minimum depth values of the object:
In order to avoid cases when the bounding box is too large compared to the object, for example because of some outliers, we weight these dimensions with the ratio between the actual size of the object, i.e., its number of contained pixels, and the area of the image space bounding box. Similar to the ground heuristic, vertical objects that were labeled as wall candidates in the inter-frame consistency phase have a high probability of belonging to the wall class. Therefore, their conditions for size and height are more relaxed than for the other vertical objects.
Generic Objects.
All remaining surfaces are merged into generic objects, based on their adjacency. Here, the only condition for uniting two adjacent surfaces is their depth intervals [z min , z max ] not to be disjoint. Next, we apply an inter-frame consistency step for the generic objects in order to propagate the IDs of the objects from the previous frame.
Figure 3 presents the output of the pre-processing, segmentation and labeling.

Output of the steps in the pipeline: the normal map (bottom-left), the output of the planar segmentation, where each region is colored based on its ID (bottom-right), the output of the labeling, where each object is colored based on its ID (upper-right) and the output of the labeling, where each object is colored based on its type: red for ground, yellow for ceiling, green for wall and blue for generic object (upper-left). (Color figure online)
Filtering of Objects.
The labeling algorithm could lead to a lot of generic objects and walls, that must be encoded into sounds and haptics. If the obtained processed scene is too complex, the user might get disoriented by the multitude of audio or haptic signals. Therefore, in a configuration step, the user can choose the maximum number of objects to be encoded and decide how these objects should be selected. In the filtering phase, we compute the importance of each generic object as a weighted sum of its size, average depth, and deviation from the view direction. The weights are established by the user. Thus, the biggest objects, or the closest ones, or the objects closest to the direction where the user is looking, could be chosen for encoding.
4 Experimental Results
We evaluated the output of the system in rudimentary scenarios, indoor rooms with only boxes, hallways, and then we increased the complexity by adding other generic objects, such as static and even dynamic human beings. The number of objects and their position was visually inspected and compared to the real scene. We also achieved a qualitative evaluation on an indoor video of 230 frames, each with the resolution of 640 × 480. We performed a manual annotation one every ten frames from the video, obtaining 23 annotated frames. The results of the manual annotation were compared pixelwise with the results of the 3D pipeline. The configuration step, that filters the most important objects, was not included in the 3D pipeline. Table 1 presents the results of this evaluation. For each labeled pixel in the frames obtained with the automatic processing, we assessed whether its label type is similar with the one obtained from the manual annotation. For each object type, we measured the percentage this type was correctly detected, and the false positives, i.e., the percentage this type was wrongly labeled as another type. For example, the ceilings were correctly labeled in 98.24% of cases, and wrongly identified as walls for 0.26% pixels and as generic objects for 1.84% pixels.
In this evaluation, we counted only the true positives and the false positives. The false negatives were not determined because the 3D pipeline eliminates very small regions in the segmentation phase and very small objects in the labeling step. Therefore, the automatic processed frames contain less labeled pixels than the manual annotated ones. These elimination steps were introduced due to the fact that very small objects are not considered of interest for the encoding phase.
As can be observed from the table, the results are promising for true positives, especially for ground (99.43% accuracy), ceiling (98.24% accuracy) and walls (99.27% accuracy). However, the walls were wrongly identified as generic objects in 9.43% of the cases. The noisy input leads to small regions that cannot be included in the big vertical objects in the labeling step, and therefore, are not included into wall objects. This problem can be however reduced in the object filtering phase: parts of wall that are far away from the user or very small can be excluded from the output.
During the evaluation, other small issues were observed. The radial error of the acquisition device introduces some errors in the computation of the point cloud and of the normal vectors at the left and right borders of the image. These distortions affect the ground plane sometimes, and lead to some small parts of the ground not being included into the ground object, but considered as generic objects. These occasional errors could be reduced by adding a confidence parameter to each generic object: if a generic object has not been seen in at least a couple of consequent frames, then it is not reported at output. The last issue is the fact that objects and walls do not always hold the same unique ID throughout a whole video, but change it from time to time. This could be caused by the sudden movement of the camera, the drift in the IMU sensor, or the strict conditions for inter-frame consistency. A way of solving this problem, which was not introduced until now because of its memory requirements and time complexity, is global reconstruction. This small issue has not been addressed yet because the sound and haptic encoding do not necessarily require time-consistent objects.
The whole 3D pipeline runs at approximately 15 fps on an Intel Core i7-4720HQ Processor with a GTX 970M GPU, on a Windows 10 OS. The application was written in C++ using OpenGL. The pre-processing step is implemented in parallel on the GPU (with compute shaders), while the segmentation and labeling run on the CPU.
5 Conclusions
In this paper, we described a succession of innovative 3D video processing algorithms with the final goal of extracting objects of interest when navigating in an indoor environment.
In the future, we plan to combine information from the IMU with visual odometry, in order to obtain a robust camera motion estimation, to add a fast global reconstruction, and to try another segmentation, on the GPU, in order to reduce the CPU load. We also plan to expand the annotated data base and implement a benchmarking application for a more thorough evaluation of the pipeline’s accuracy and for comparisons with future similar methods. This initial pipeline is intended for navigation. However, in the future we plan to integrate an algorithm that recognizes objects [19], in order to obtain a semantic labeling that would allow the blind users not only to navigate, but also to perceive the environment.
References
Stoll, C., Germain, R.P.: Navigating from a depth image converted into sound. Appl. Bionics Biomech. (2015)
Blessenohl, S., Morrison, C.,Criminisi, A., Shotton, J.: Improving indoor mobility of the visually impaired with depth-based spatial sound. In: IEEE International Conference on Computer Vision Workshop (2015)
Taylor, C.J., Cowley, A.: Parsing indoor scenes using RGB-D imagery. In: Robotics: Science and Systems (2012)
Liu, H., Wang, J., Wang, X., Qian, Y.: iSee: obstacle detection and feedback system for the blind. In: UbiComp/ISWC 2015 Adjunct, pp. 197–200 (2015)
Lai, K., Bo, L., Ren, X., Fox, D.: Detection-based object labeling in 3D scenes. In: International Conference on Robotics and Automation (2012)
Wang, Y., Ji, R., Chang, S.F.: Label propagation from imagenet to 3D point clouds. In: IEEE Conference on Computer Vision and Pattern Recognition (2013)
Kim, B.S., Kohli, P., Savarese, S.: 3D scene understanding by voxel-CRF. In: IEEE International Conference on Computer Vision (ICCV) (2013)
Anand, A., Koppula, H.S.: Contextually guided semantic labeling and search for three-dimensional point clouds. Int. J. Robot. Res. 32(1), 19–34 (2013)
Taskar, B., Chatalbashev, V., Koller, D.: Learning associative markov networks. In: International Conference on Machine Learning (2004)
Lai, K., Bo, L., Fox, D.: Unsupervised feature learning for 3D scene labeling. In: IEEE International Conference on Robotics and Automation (2014)
Wang, Z., Liu, H., Wang, X., Qian, Y.: Segment and label indoor scene based on RGB-D for the visually Impaired. In: Gurrin, C., Hopfgartner, F., Hurst, W., Johansen, H., Lee, H., O’Connor, N. (eds.) MMM 2014. LNCS, vol. 8325, pp. 449–460. Springer, Cham (2014). doi:10.1007/978-3-319-04114-8_38
Gomez, J.D.R., Bologna, G.: See ColOr: an extended sensory substitution device for the visually impaired. J. Assistive Technol. (2014)
Huang, H., Jiang, H., Brenner, C., Mayer, H.: Object-level segmentation of RGBD data. ISPRS Ann. Photogrammetry Remote Sens. Spat. Inf. Sci. II(3), 73–78 (2014)
Deng, Z., Todorovic, S., Latecki, L.J.: Semantic segmentation of RGBD images with mutex constraints. In: IEEE International Conference on Computer Vision (2015)
Gupta, S., Arbelaez, P., Girshick, R., Malik, J.: Indoor scene understanding with RGB-D images: bottom-up segmentation, object detection and semantic segmentation. Int. J. Comput. Vis. 112(2), 133–149 (2015)
Yang, S., Maturana, D., Scherer, S.: Real-time 3D scene layout from a single image using convolutional neural networks. In: IEEE International Conference on Robotics and Automation (2016)
Petrescu, L., Morar, A., Moldoveanu, F., Moldoveanu, A.: Kinect depth inpainting in real time. In: International Conference on Telecommunications and Signal Processing (2016)
Morar, A., Moldoveanu, F., Petrescu, L., Balan, O., Moldoveanu, A.: Time-consistent segmentation of indoor depth video frames. In: Accepted for publication at the International Conference on Telecommunications and Signal Processing (2017)
Petroniu, M., Trascau, M., Mocanu, I.: Object recognition with kinect sensor. In: 20th International Conference on Control Systems and Science, Bucharest (2015)
Acknowledgement
This work has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement 643636 (Sound of Vision research project – www.soundofvision.net).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Morar, A., Moldoveanu, F., Petrescu, L., Moldoveanu, A. (2017). Real Time Indoor 3D Pipeline for an Advanced Sensory Substitution Device. In: Battiato, S., Gallo, G., Schettini, R., Stanco, F. (eds) Image Analysis and Processing - ICIAP 2017 . ICIAP 2017. Lecture Notes in Computer Science(), vol 10485. Springer, Cham. https://doi.org/10.1007/978-3-319-68548-9_62
Download citation
DOI: https://doi.org/10.1007/978-3-319-68548-9_62
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-68547-2
Online ISBN: 978-3-319-68548-9
eBook Packages: Computer ScienceComputer Science (R0)
