
Abstract
The reconstruction of complex 3D objects from video sequences captured by surveillance, smartphone, and other cameras is a common technique in Hollywood blockbusters and TV series. Unfortunately, the automatic or interactive 3D object reconstruction from this kind of videos is not yet possible in the real world. Enabling computers to recognize the actual 3D shape of objects from complex video sequences, we developed a bio-inspired processing architecture, motivated by findings in the area of human object recognition. By utilizing viewpoint-specific object recognition, changes in position and size of the object of interest in video sequences can be eliminated to a great extent. The result is a representation, comprised of multiple pictures showing 2D projections of the object of interest (OOI) from different viewpoints. Based on this representation, a 3D point cloud (PC) from the object can be obtained. After a detailed description of our architecture and its similarities to the human view-combination scheme, we demonstrate its potency by reconstructing several OOI from complex video sequences. Because some processing modules of the architecture cannot yet be fully automatized, we introduced interactive modules instead. Thus the prototypical implementation of our approach could be realized. Based on the resulting PC, we evaluate our architecture and consider more analogies between human and computer vision, which improve image-based 3D reconstruction.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
In London, UK, we are being filmed by at least 300 different surveillance cameras on a daily basis [18]. With surveillance playing such a big part in our lives, non-experts usually believe that video-based 3D reconstruction of e.g. a bag someone is carrying is already possible in a similar manner as in blockbusters and TV series. Even with state of the art technologies, however, these tasks are usually still tough, especially if the videos are showing moving objects in their natural context. With the nowadays exponentially increasing amount of video sequences uploaded to video-sharing platforms the ability to reconstruct 3D objects from any videos would offer a valuable addition to existing methods of exploring and utilizing these large databases for a multitude of implementations. In contrast to the computer, the recognition of the 3D shape of an OOI within video sequences is quite easy for humans, even if the videos do not show the OOI from every side, or if the OOI is partially occluded.
For the purpose of enabling computers to reconstruct 3D models of any OOI, which is shown from all angles, in their natural environment in one or several video sequences, we developed, implemented and evaluated a bio-inspired processing architecture. With our general architecture for deriving 3D models from video sequences, we are moving computer vision from controlled environments with specific data sets, conditions, setups, etc., into real world scenarios. The real world scenarios present challenges, such as semantic object recognition, which are not yet completely solvable with fully-automatic approaches. Thus, to facilitate a prototypical implementation of our process architecture, some of the processing modules of our architecture are interactive.
One or several video sequences showing the same OOI from different specific viewpoints suffice as input data, for our proposed bio-inspired architecture. The extraction of all viewpoint-specific representations of a certain OOI is the essential part of our architecture. Therefore, 2D object recognition algorithms are applied for recognizing the OOI and separating it from the background in every frame. As a result, multiple 2D viewpoint-specific representations of the 3D OOI are extracted from the input data. Using multiple view geometry (MVG) algorithms, these viewpoint-specific representations are used for creating solid viewpoint-invariant geometrical watertight 3D models. These models are beneficial for many technical use cases, e.g. in any computer-aided design (CAD) task [13, 19], but on the other hand, these models do not reflect the representation of 3D objects in the brain [6, 25]. From viewpoint-specific representations of an OOI, any MVG algorithm, such as structure from motion (SfM) algorithms, calculates the corresponding 3D PC as the basis for the virtual meshed 3D model. It should be noted that so far the generation of virtual viewpoint-invariant 3D models is only inspired by their technical use cases since current psychophysical evidence suggests that “humans encode 3D objects as multiple viewpoint-specific representations that are largely 2D” [6]. Apart from that, some other theories promote the usage of viewpoint-invariant representations in the human brain, such as viewpoint-invariant 3D model representations [15] or combinations of viewpoint-invariant geon structural descriptions [11]. Independent of their overall conclusion, most theories suggest viewpoint-invariant representation at some stage in the process, such that the low-level modules of our architecture emulate the visual information processing in the human brain on a high-level basis.
2 Viewpoint-Specific Object Recognition for Deriving 3D Models from Videos
Our 3D reconstruction architecture [23] which is powered by viewpoint-specific object recognition consists of six processing modules (cf. Fig. 1) and can reconstruct a 3D model of an OOI from any video sequence, recorded by a normal monocular camera. The first four bio-inspired processing modules recognize the viewpoint-specific 2D projection of the OOI on each frame of every video sequence. They are functioning similarly to the main processing direction of the ventral stream pathway of the visual cortex [26, 27] and are responsible for the viewpoint-specific object recognition. Thus, these four modules are sequential, straightforward and bottom-up organized in our architecture. The following two processing modules reconstruct the viewpoint-independent virtual 3D model of the OOI by using the recognized 2D projection. These last two modules are mainly technically-inspired and can be compared with SfM approaches [13, 21]. The answer to why we motivated our architecture with the ventral visual stream [26, 27] of the visual cortex, which is associated with object recognition and not with the dorsal stream [26, 27], which is responsible for the spatial aspect “where” the object is located, is simple. The most relevant information for reconstructing a sole object is “what” the object looks like and not “where” the object is located. So the context around an object is irrelevant, in our opinion, for recognizing its 3D shape. Nevertheless, for recognizing the identity of objects, the real world context is relevant [16]. By recognizing and separating the OOI on every frame, where the OOI is visible, apriori real world knowledge is added to the video sequences.
I. Reading input videos as pixel cuboid translates the video sequences into a processable data format. In our case, video sequences of any format are translated into 3D cuboids of pixels \(C_1, C_2,\ldots C_n\), where n is the number of available video sequences \(S_1, S_2,\ldots S_n\) showing the OOI. For each \(i=1,\ldots ,n\), the dimensions of cuboid \(C_i\) are defined by the horizontal resolution \(h_i\), by the vertical resolution \(v_i\) and the number of frames \(f_i\) of each video sequence, thus \(C_i\) has \(h_i\times v_i\times f_i\) pixels. Furthermore, every pixel \(p_i (x,y,t)\) is given as a triple of the additive primary colors.
II. Annotating pixels of cuboids states, whether or not a pixel \(p_i (x,y,t)\) belongs to the OOI. Based on a pixel-accurate viewpoint-dependent object recognition in natural scenes, this module provides further information like whether the OOI is occluded and if parts of the OOI are outside the frame.
III. Annotation-based pixel nullification sets the pixels mark as not belonging to the OOI to null. Thus, this module returns the cuboids \(C_1, C_2,\ldots C_n\) represent the 2D projection of the OOI.
IV. Creating multiple pictorial representations is the processing module that extracts and crops all non-empty frames from the cuboids based on the minimum bounding rectangle. The resulting sequence of views \(V_1, V_2,\ldots ,V_z\) show the OOI from different viewpoints. The different projections are caused by the moving OOI and the moving camera. Note, the temporal ordering of the views gain further information and is also extracted.
V. Building a PC based on all views \(V_1, V_2,\ldots ,V_z\). Due to the prior bio-inspired modules I to IV, any MVG approach should be able to calculate a dense PC of the OOI based on the multiple pictorial representations. Thus this module is the interface between the bio-inspired and technologically-inspired modules for creating a 3D model.
VI. Meshing the PC creates the watertight surface of the OOI based on its PC. From the several different approaches that exist, we suggest the ball-pivoting algorithm by Bernardini et al. [2], because it does not interpolate points of the PC, thereby its preserving their position during meshing. However, unlike, for example, the Poisson meshing [12], the resulting mesh is mostly not watertight.

Overview of our bio-inspired architecture [23] for deriving 3D models powered by viewpoint-specific object recognition; consists of six modules: I reading input videos as pixel cuboid, II annotating pixels of cuboids—viewpoint-specific pixel-accurate recognition, III annotation-based pixel nullification, IVcreating multiple pictorial representations, V building a PC, and VI meshing PC. Non-filled modules are bio-inspired; gray marked modules are technology-inspired for creating 3D models.
3 Related Work
Giving a brief overview, only the major topics: image segmentation and annotation tools, and image-based 3D reconstruction techniques are mentioned below.
Fully automatic and pixel-accurate OOI detection, as well as segmentation from images especially from image sequences, seems far from being solved. In general, it can be observed that the performance scores of segmentation algorithm drop significantly from easier data sets, i.e. showing the complete OOI, to natural data sets, i.e. showing a partially occluded OOI [4]. Even the run-time of segmentation methods [4] is, in our opinion, not applicable for high-resolution images. Overcoming the obstacle of inaccurate segmentation, interactive algorithms like interactive graph cut [5] are promising approaches.
Annotation tools for polygon-shaped labeling of OOI can be seen as an extension of interactive segmentation algorithms. Thus, existing video annotation tools could be used for the implementation of processing modules I and II of our proposed architecture. According to a review [8] of seven video annotation tools, only one tool, the Video and Image Annotation tool (VIA, provides pixel-accurate OOI annotations. The quite popular Video Performance Evaluation Resource (ViPER) [9] perform object labeling process which can be speeded up by an automatic linear 2D propagation of the annotations. Recently, we released an open source video annotation tool—iSeg [20]. It came with a novel interactive and semi-automatic segmentation process for creating pixel-wise labels of several objects in video sequences. The latest version of iSeg provides a semantic timeline for defining if an object is not, partially, or completely occluded in a certain frame.
In the wide research area of 3D reconstruction techniques, one can observe two main strategies, i.e. fully automatic reconstruction and interactive reconstruction. For our bio-inspired architecture, only those 3D reconstruction approaches are relevant that work with images or videos captured by monocular cameras.
Automatic reconstruction methods based on large image collections have been shown to produce sufficiently accurate 3D models [13, 21]. The photo explorer [24], as one of the first scalable 3D reconstruction application, uses an unstructured image collection of a scene and converts it to a 3D model. In near real-time, the probabilistic feature-based online rapid model acquisition tool [17] reconstructs freely rotatable objects, in front of a static video camera. This system guides the user with respect to the necessary manipulation, i.e. “please rotation of the object clockwise”, needed for the object reconstruction.
Often challenging for these automatic reconstruction techniques are the handling of delicate structures, textureless surfaces, hidden boundaries, illumination, specularity, and even dynamic or moving objects, etc., but they usually occur in natural video sequences. Motivated by these issues, Kowdle et al. [13] came up with a semi-automatic approach, which embeds the user in the process of reconstruction. Other interactive approaches are based on the presence of common geometric primitives, i.e. human-made architecture [1] for reconstruction. Usually, such approaches are designed out of automatic pre-processing steps followed by interactive processing steps.
All of the techniques as mentioned earlier have in common that the reconstructed 3D objects are monolithic and not semantically split into their parts or rather subparts. Today, monolithic 3D models are sufficient for indoor navigation, reconstruction of urban environments, etc., but for more complex tasks, the detailed reconstruction of objects including their subparts might be necessary [19]. As a consequence, further research in 3D reconstruction should also focus on semantic part detection in 3D models, as well as from the input data.
4 Analogies to the Ventral Stream
During the implementation of our bio-inspired architecture with all modules illustrated in Fig. 1, we recognize many analogies of our system to the view-combination scheme by Ullman [25].
Ullman stated, in the view-combination scheme, that “recognition by multiple pictorial representations and their combinations constitutes a major component of 3D object recognition” [25, p. 154] of humans and “unlike some of the prevailing approaches...object recognition...is simpler, more direct, and pictorial in nature. ” [25, p. 154]. The first four processing modules I–IV of our bio-inspired architecture reduce the complexity of the input information, from unclassified pixels over segmented pixels to multiple pictorial representations without any contextual information (cf. [23, Fig. 3]). This process is similar to the statement that “cells along the hierarchy from V1 to V4 also show an increasing degree of tolerance for the position and size of their preferred stimuli” [25, p. 152]. “An object appears to be represented in IT by multiple units, tuned to different views of the object” [25, p. 152] describing the general idea of SfM, comparable to our processing module V.
One can see a strong analogy between the bottom-up idea of the view-combination scheme and our architecture, up to processing module V including. The processing module VI might be a part of the top-down process, representing an internal object model. In our definition, however, it cannot be mapped to Ullman’s scheme.
5 Application of the Architecture
In order to evaluate the performance of our architecture, we processed two natural video sequences [14] showing a red car and four computer-generated video sequences [7, 10] showing a table and desk. Based on the artificial video sequences, we can evaluate the resulting virtual 3D models against a known ground truth. Using a ground truth allows us to analyze the performance on a quantitative level, although the artificial nature of the dataset calls for further investigation on how the results will generalize to real world scenarios. In contrast, for the natural video sequences, we do not have a ground truth. Thus, the performance evaluation can still be conducted on a qualitative level by visual inspection. Comparing both phases gives a comprehensive perspective on the general performance of our implementation and the applicability of the underlying architecture.
5.1 Natural Video Sequences
The qualitative analysis is conducted on natural, real-world video sequences, for which our bio-inspired architecture is designed. In our case, we choose the first two video sequences of a benchmark data set for evaluating visual analysis techniques for eye tracking data from video stimuli [14]. These two sequences show the same rigid OOI, a red car, driving along roads. Both video sequences provide a resolution of 1080p at a frame rate of 25 fps, and exemplary frames are shown in Fig. 2(a – b). With a duration of 25 s, the first sequence contains, in addition to object motion, camera movement. Furthermore, it also contains frames, where the OOI is partially occluded, completely occluded or off the frame. The second sequence, with a duration of 28 s, contains motion of the OOI only. The number plate of the car is blurred in each video sequence.
5.2 Computer-Generated Sequences
Video sequences, rendered on virtual 3D models of two indoor scenes, are used for quantitative analysis of the proposed architecture. Therefore, the RGB image sequences [7] of the living room—cf. Fig. 2(c – d)—and the office—cf. Fig. 2(e – f)—are converted to video sequences. The resulting video sequence provides, at a frame rate of 25 fps, a resolution of 640 \(\times \) 480 pixels and a duration of about 90 s. As rigid OOI, the table in the living room scene and the desk in the office scene are picked, which were on several frames partial occluded, complete occluded or from the frame. In these sequences, only camera movement occurs. As 3D ground truth for quantitative evaluation, the table is extracted from the geometry of the scene [10].

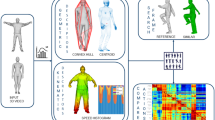
Exemplary frames of the six video sequences after being processed by the modules II, IV and V. Always two video sequences shown one OOI, here car, table and desk.(a), (b), (c), (d), (e), (f): recognized and annotated OOI in multiple frames; (g), (h), (i), (j), (k), (l): extracted viewpoint-dependent pixel-accurate pictorial representations of the OOI; (m), (n), (o), (p), (q), (r): resulting viewpoint-invariant PC; Note that (f) and (l) show only a partially visible OOI. *computer-generated video sequences rendered from virtual 3D models of indoor scenes.
5.3 Experimental Application
As illustrated by a yellow bounding polygon in Fig. 2(a – f), the OOI is recognized in an interactive process in all six video sequences, using our altered version of iSeg. After viewpoint-dependent recognition of the OOI, all sequences including their pixel-wise labels of the OOI are stored in our mkv-based exchange format [22], which provides the opportunity to visualize the recognized OOI. The video sequences, including the corresponding OOI annotations, can be found can be found at the project homepageFootnote 1.
Using these files, pixel nullification generates a viewpoint-dependent pictorial representation, as seen in Fig. 2(g – l). Note that in case the OOI does not occur on a frame, no pictorial representation is created. Out of the multiple viewpoint-dependent pictorial representations of the recognized OOI, a SfM software [28] computes the PC of the OOI, show in Fig. 2(m – r).
In order to evaluate whether viewpoint-dependent pixel-accurate object recognition improves 3D reconstruction from videos, we also compute the corresponding PC based on the complete, non-nullified frames, where the OOI occurs. Therefore, the stored OOI annotations are only used to assess whether or not the OOI is on a frame. The resulting PC are illustrated in Fig. 3.

Resulting viewpoint-invariant PC if non pixel-accurate pictorial representations of the OOI (a) car, (b) table, and (c) desk are used for computing the PC; one could recognize that without viewpoint-dependent pixel-accurate object recognition more than just the OOI is represented by the PC.
Obtaining measurements of the accuracy of the proposed architecture, the resulting PC of the table, and in Fig. 2(o – p) as well as the result PC without pixel-accurate object recognition, see Fig. 3(b), is compared to the ground truth. Therefore a ground truth PC with 10, 000 vertices was derived from the model of the table. Using the open source software CloudCompare, the PC are aligned to the ground truth PC. In order to get meaningful information from the dense PC, the resulting PC and the PC of the ground truth are compared with the resulting cloud defined as the reference, as seen in Fig. 4.

Point cloud comparison between the ground truth PC and the resulting PC with and without pixel-accurate object recognition. Note that for the comparisons, the resulting PC is defined as reference; the global coordinate system is scaled on meters.
6 Results
A first qualitative analysis is conducted by focusing on the last row of Fig. 2. Here, our architecture can reconstruct PC of the OOI. Furthermore, the resulting PC still show an enormous amount of noise, both within the volume of the OOI and also externally, such that it would be even hard for humans to guess the OOI from the PC if the color values of the cloud were omitted. In terms of the qualitative analysis on whether or not pixel-accurate object recognition boosts 3D reconstruction, the last row of Fig. 2 is compared with the PC of Fig. 3. This shows that the PC of the car generated from the natural video sequences does not provide a viewpoint-independent 3D model of the car. Instead, it only provides a 3D model of the scene, in which the car is being driven. Focusing on the computer-generated scene, the OOI are represented in the PC by more points. Thus, the reconstruction result without pixel-accurate object recognition delivers denser PC representation of the OOI.
Due to the missing ground truth, the quantitative analysis can only be done on the artificial, computer-generated video sequences. As seen in Fig. 4, the distribution of cloud to cloud absolute distance between corresponding points is almost identical with a mean value \(\mu \,\approx \,0. 03\) m at a standard deviation \(\sigma \,\approx \,0. 018\) m. It is striking that by the direct comparison of the PC heat maps, the PC generated by pixel-accurate object recognition, cf. Fig. 4(a), indicates a larger difference to the ground truth.
7 Discussion
In considering the qualitative performance of our bio-inspired architecture using viewpoint-specific object recognition as the key feature, we show that our architecture works exceptionally well. Focusing on the computer-generated video sequences only, one can see that pixel-accurate object recognition indicates a slightly lower performance in accuracy compared to the ground truth, as well as in a number of points in the PC. In our opinion, this effect is caused by i) the number of insufficient feature points within the extracted pictorial representation from the artificial video sequences and ii) due to the static scene without any OOI movement. These circumstances explain the potency of our architecture on the nature video sequences, where the car is only reconstructed successfully with viewpoint-dependent pixel-accurate object recognition. As a consequence, our approach could be improved by more sophisticated image features, which generate a high number of features even on textureless and/or shiny surfaces. Finally, note that the 3D reconstruction without pixel-accurate object recognition does not reconstruct the OOI separately, but rather it reconstructs the OOI and the scene jointly. Thus, the OOI must be recognized again, but now in 3D space, before one can start any OOI meshing.
The resulting PC of the OOI are still quite sparse and cannot be meshed into watertight models, yet. This fact might be generated by the transition of the bio-inspired processing modules I–IV into the technologically-inspired module VI. The module V is somehow both and appears in slightly altered versions in human [6, 25, 26] and computer [13, 28] vision. To accompany this transition, the bio-inspired and technically-inspired modules should be interconnected in module V. Therefore the module VI should be replaced with a top-down approach, e.g. a wireframe [30] or a CAD [29] model-based object fitting based on the created PC. The resulting architecture can derive a complete meshed CAD-ready 3D model from video sequences. In our opinion, such a top-down implementation of module VI is possible due to an incredibly huge knowledge database containing generic 3D models. However, by reflecting the conceptual idea of Biederman [3], i.e. that any 3D object can be described by a set of geometrical primitives, symmetry relations and some kind of grammar, it might be possible to generate 3D models from PC, without huge databases.
In conclusion, viewpoint-dependent object recognition, embedded in our architecture, significantly improves 3D object recognition from one or several video sequences. Hence, 3D reconstruction becomes possible even if the camera and the OOI are moving. The creation of a CAD-ready 3D model for technical use, which can be applied for simulation tasks and reverse engineering, is not yet possible since the resulting 3D PC are sparse and not noise-free. For implementing our architecture as a fully automatic process, the problem of pixel-accurate OOI recognition and annotation must be solved.
References
Arikan, M., Schwärzler, M., Flöry, S., Wimmer, M., Maierhofer, S.: O-Snap: optimization-based snapping for modeling architecture. ACM Trans. Graph. 32(1), 6:1–6:15 (2013)
Bernardini, F., Mittleman, J., Rushmeier, H., Silva, C., Taubin, G.: The ball-pivoting algorithm for surface reconstruction. Trans. Vis. Comput. Graph. 5(4), 349–359 (1999)
Biederman, I.: Recognition-by-components: a theory of human image understanding. Psychol. Rev. 94(2), 115–147 (1987)
Borji, A., Cheng, M.M., Jiang, H., Li, J.: Salient object detection: a benchmark. Trans. Image Process. 24(12), 5706–5722 (2015)
Boykov, Y., Jolly, M.P.: Interactive graph cuts for optimal boundary and region segmentation of objects in N-D images. In: ICCV, pp. 105–112. IEEE (2001)
Bulthoff, H.H., Edelman, S.Y., Tarr, M.J.: How are three-dimensional objects represented in the brain? Cereb. Cortex 5(3), 247–260 (1995)
Choi, S., Zhou, Q.Y., Koltun, V.: Robust reconstruction of indoor scenes. In: CVPR, pp. 5556–5565. IEEE (2015)
Dasiopoulou, S., Giannakidou, E., Litos, G., Malasioti, P., Kompatsiaris, Y.: A survey of semantic image and video annotation tools. In: Paliouras, G., Spyropoulos, C.D., Tsatsaronis, G. (eds.) Knowledge-Driven Multimedia Information Extraction and Ontology Evolution. LNCS, vol. 6050, pp. 196–239. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-20795-2_8
Doermann, D., Mihalcik, D.: Tools and techniques for video performance evaluation. In: ICPR, vol. 4, pp. 167–170. IEEE (2000)
Handa, A., Whelan, T., McDonald, J., Davison, A.: A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In: ICRA, pp. 1524–1531. IEEE (2014)
Hummel, J.E., Biederman, I.: Dynamic binding in a neural network for shape recognition. Psychol. Rev. 99(3), 480–517 (1992)
Kazhdan, M., Hoppe, H.: ACM Trans. Graph. Screened poisson surface reconstruction 32(3), 29:1–29:13 (2013)
Kowdle, A., Chang, Y.J., Gallagher, A., Batra, D., Chen, T.: Putting the user in the loop for image-based modeling. Int. J. Comput. Vis. 108(1), 30–48 (2014)
Kurzhals, K., Bopp, C.F., Bässler, J., Ebinger, F., Weiskopf, D.: Benchmark data for evaluating visualization and analysis techniques for eye tracking for video stimuli. In: Workshop on BELIV, pp. 54–60. ACM (2014)
Marr, D., Nishihara, H.K.: Representation and recognition of the spatial organization of three-dimensional shapes. Proc. Roy. Soc. Lond. B: Biol. Sci. 200(1140), 269–294 (1978)
Oliva, A., Torralba, A.: The role of context in object recognition. Trends Cogn. Sci. 11(12), 520–527 (2007)
Pan, Q., Reitmayr, G., Drummond, T.: ProFORMA: probabilistic feature-based on-line rapid model acquisition. In: BMVC, pp. 112:1–112:11 (2009)
Pillai, G.: Caught on camera: You are filmed on cctv 300 times a day in london. International Business Times March 2012. www.ibtimes.co.uk/britain-cctv-camera-surveillance-312382
Schöning, J.: Interactive 3D reconstruction: new opportunities for getting CAD-ready models. ICCSW. OASIcs, vol. 49, pp. 54–61 (2015)
Schöning, J., Faion, P., Heidemann, G.: Semi-automatic ground truth annotation in videos: an interactive tool for polygon-based object annotation and segmentation. In: K-CAP, pp. 17:1–17:4. ACM (2015)
Schöning, J., Heidemann, G.: Evaluation of multi-view 3D reconstruction software. In: Azzopardi, G., Petkov, N. (eds.) CAIP 2015. LNCS, vol. 9257, pp. 450–461. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-23117-4_39
Schöning, J., Faion, P., Heidemann, G., Krumnack, U.: Providing video annotations in multimedia containers for visualization and research. In: WACV. IEEE (2017)
Schöning, J., Heidemann, G.: Bio-inspired architecture for deriving 3D models from video sequences. In: Chen, C.-S., Lu, J., Ma, K.-K. (eds.) ACCV 2016. LNCS, vol. 10117, pp. 62–76. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-54427-4_5
Snavely, N., Seitz, S.M., Szeliski, R.: Photo tourism: exploring photo collections in 3D. ACM Trans. Graph. 25(3), 835–846 (2006)
Ullman, S.: High-Level Vision: Object Recognition and Visual Cognition, 2nd edn. MIT press Cambridge, MA (1997)
Ungerleider, L.G.: “What” and “where” in the human brain. Curr. Opin. Neurobiol. 4(2), 157–165 (1994)
Ungerleider, L., Mishkin, M.: Two cortical visual systems. In: Ingle, D., Goodale, M., Mansfield, R. (eds.) Analysis Visual Behavior, pp. 549–586. MIT Press, Boston (1982)
Wu, C.: VisualSfM: a visual structure from motion system July 2017. http://ccwu.me/vsfm/
Xiang, Y., Mottaghi, R., Savarese, S.: Beyond PASCAL: a benchmark for 3D object detection in the wild. In: WACV, pp. 75–82. IEEE (2014)
Zhang, Z., Tan, T., Huang, K., Wang, Y.: Three-dimensional deformable-model-based localization and recognition of road vehicles. Trans. on Image Process. 21(1), 1–13 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Schöning, J., Heidemann, G. (2017). Ventral Stream-Inspired Process for Deriving 3D Models from Video Sequences. In: Battiato, S., Farinella, G., Leo, M., Gallo, G. (eds) New Trends in Image Analysis and Processing – ICIAP 2017. ICIAP 2017. Lecture Notes in Computer Science(), vol 10590. Springer, Cham. https://doi.org/10.1007/978-3-319-70742-6_7
Download citation
DOI: https://doi.org/10.1007/978-3-319-70742-6_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-70741-9
Online ISBN: 978-3-319-70742-6
eBook Packages: Computer ScienceComputer Science (R0)
