
Abstract
This paper reviews the checkered history of predictive distributions in statistics and discusses two developments, one from recent literature and the other new. The first development is bringing predictive distributions into machine learning, whose early development was so deeply influenced by two remarkable groups at the Institute of Automation and Remote Control. As result, they become more robust and their validity ceases to depend on Bayesian or narrow parametric assumptions. The second development is combining predictive distributions with kernel methods, which were originated by one of those groups, including Emmanuel Braverman. As result, they become more flexible and, therefore, their predictive efficiency improves significantly for realistic non-linear data sets.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
References
Burnaev, E., Vovk, V.: Efficiency of conformalized ridge regression. In: JMLR: Workshop and Conference Proceedings, COLT 2014, vol. 35, pp. 605–622 (2014)
Burnaev, E.V., Nazarov, I.N.: Conformalized Kernel Ridge Regression. Technical report arXiv:1609.05959 [stat.ML], arXiv.org e-Print archive, September 2016. Conference version: Proceedings of the Fifteenth International Conference on Machine Learning and Applications (ICMLA 2016), pp. 45–52
Chatterjee, S., Hadi, A.S.: Sensitivity Analysis in Linear Regression. Wiley, New York (1988)
Cox, D.R.: Some problems connected with statistical inference. Ann. Math. Stat. 29, 357–372 (1958)
Dawid, A.P.: Statistical theory: the prequential approach (with discussion). J. Royal Stat. Soc. A 147, 278–292 (1984)
Dawid, A.P., Vovk, V.: Prequential probability: principles and properties. Bernoulli 5, 125–162 (1999)
Efron, B.: R. A. Fisher in the 21st century. Stat. Sci. 13, 95–122 (1998)
Gneiting, T., Katzfuss, M.: Probabilistic forecasting. Ann. Rev. Stat. Appl. 1, 125–151 (2014)
Goldberg, P.W., Williams, C.K.I., Bishop, C.M.: Regression with input-dependent noise: a Gaussian process treatment. In: Jordan, M.I., Kearns, M.J., Solla, S.A. (eds.) Advances in Neural Information Processing Systems 10, pp. 493–499. MIT Press, Cambridge (1998)
Henderson, H.V., Searle, S.R.: On deriving the inverse of a sum of matrices. SIAM Rev. 23, 53–60 (1981)
Knight, F.H.: Risk, Uncertainty, and Profit. Houghton Mifflin Company, Boston (1921)
Le, Q.V., Smola, A.J., Canu, S.: Heteroscedastic Gaussian process regression. In: Dechter, R., Richardson, T. (eds.) Proceedings of the Twenty Second International Conference on Machine Learning, pp. 461–468. ACM, New York (2005)
McCullagh, P., Vovk, V., Nouretdinov, I., Devetyarov, D., Gammerman, A.: Conditional prediction intervals for linear regression. In: Proceedings of the Eighth International Conference on Machine Learning and Applications (ICMLA 2009), pp. 131–138 (2009). http://www.stat.uchicago.edu/~pmcc/reports/predict.pdf
Montgomery, D.C., Peck, E.A., Vining, G.G.: Introduction to Linear Regression Analysis, 5th edn. Wiley, Hoboken (2012)
Platt, J.C.: Probabilities for SV machines. In: Smola, A.J., Bartlett, P.L., Schölkopf, B., Schuurmans, D. (eds.) Advances in Large Margin Classifiers, pp. 61–74. MIT Press (2000)
Schweder, T., Hjort, N.L.: Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions. Cambridge University Press, Cambridge (2016)
Shen, J., Liu, R., Xie, M.: Prediction with confidence–A general framework for predictive inference. J. Stat. Plann. Infer. 195, 126–140 (2018)
Shiryaev, A.N.:
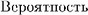 (Probability), 3rd edn.
(Probability), 3rd edn.  , Moscow (2004)
, Moscow (2004)Snelson, E., Ghahramani, Z.: Variable noise and dimensionality reduction for sparse Gaussian processes. In: Dechter, R., Richardson, T. (eds.) Proceedings of the Twenty Second Conference on Uncertainty in Artifical Intelligence (UAI 2006), pp. 461–468. AUAI Press, Arlington (2006)
Steinwart, I.: On the influence of the kernel on the consistency of support vector machines. J. Mach. Learn. Res. 2, 67–93 (2001)
Thomas-Agnan, C.: Computing a family of reproducing kernels for statistical applications. Numer. Algorithms 13, 21–32 (1996)
Vovk, V.: Universally consistent predictive distributions. Technical report. arXiv:1708.01902 [cs.LG], arXiv.org e-Print archive, August 2017
Vovk, V., Gammerman, A., Shafer, G.: Algorithmic Learning in a Random World. Springer, New York (2005)
Vovk, V., Nouretdinov, I., Gammerman, A.: On-line predictive linear regression. Ann. Stat. 37, 1566–1590 (2009)
Vovk, V., Papadopoulos, H., Gammerman, A. (eds.): Measures of Complexity: Festschrift for Alexey Chervonenkis. Springer, Heidelberg (2015)
Vovk, V., Petej, I.: Venn-Abers predictors. In: Zhang, N.L., Tian, J. (eds.) Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence, pp. 829–838. AUAI Press, Corvallis (2014)
Vovk, V., Shen, J., Manokhin, V., Xie, M.: Nonparametric predictive distributions based on conformal prediction. In: Proceedings of Machine Learning Research, COPA 2017, vol. 60, pp. 82–102 (2017)
Wasserman, L.: Frasian inference. Stat. Sci. 26, 322–325 (2011)
Zadrozny, B., Elkan, C.: Obtaining calibrated probability estimates from decision trees and naive Bayesian classifiers. In: Brodley, C.E., Danyluk, A.P. (eds.) Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), pp. 609–616. Morgan Kaufmann, San Francisco (2001)
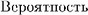 (Probability), 3rd edn.
(Probability), 3rd edn.  , Moscow (2004)
, Moscow (2004)Acknowledgements
This work has been supported by the EU Horizon 2020 Research and Innovation programme (in the framework of the ExCAPE project under grant agreement 671555) and Astra Zeneca (in the framework of the project “Machine Learning for Chemical Synthesis”).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
A Properties of the Hat Matrix
A Properties of the Hat Matrix
In the kernelized setting of this paper the hat matrix is defined as \(H=(K+aI)^{-1}K\), where K is a symmetric positive semidefinite matrix whose size is denoted \(n\times n\) in this appendix (cf. (10); in our current abstract setting we drop the bars over H and K and write n in place of \(n+1\)). We will prove, or give references for, various properties of the hat matrix used in the main part of the paper.
Numerous useful properties of the hat matrix can be found in literature (see, e.g., [3]). However, the usual definition of the hat matrix is different from ours, since it is not kernelized; therefore, we start from reducing our kernelized definition to the standard one. Since K is symmetric positive semidefinite, it can be represented in the form \(K=XX'\) for some matrix X, whose size will be denoted \(n\times p\) (in fact, a matrix is symmetric positive semidefinite if and only if it can be represented as the Gram matrix of n vectors; this easily follows from the fact that a symmetric positive semidefinite K can be diagonalized: \(K=Q'\varLambda Q\), where Q and \(\varLambda \) are \(n\times n\) matrices, \(\varLambda \) is diagonal with nonnegative entries, and \(Q'Q=I\)). Now we can transform the hat matrix as
(the last equality can be checked by multiplying both sides by \((XX'+aI)\) on the left). If we now extend X by adding \(\sqrt{a}I_p\) on top of it (where \(I_p=I\) is the \(p\times p\) unit matrix),
and set
we will obtain a \((p+n)\times (p+n)\) matrix containing H in its lower right \(n\times n\) corner. To find HY for a vector \(Y\in \mathbb {R}^n\), we can extend Y to \(\tilde{Y}\in \mathbb {R}^{p+n}\) by adding p zeros at the beginning of Y and then discard the first p elements in \(\tilde{H} \tilde{Y}\). Notice that \(\tilde{H}\) is the usual definition of the hat matrix associated with the data matrix \(\tilde{X}\) (cf. [3, (1.4a)]).
When discussing (11), we used the fact that the diagonal elements of H are in [0, 1). It is well-known that the diagonal elements of the usual hat matrix, such as \(\tilde{H}\), are in [0, 1] (see, e.g., [3, Property 2.5(a)]). Therefore, the diagonal elements of H are also in [0, 1]. Let us check that \(h_i\) are in fact in the semi-open interval [0, 1) directly, without using the representation in terms of \(\tilde{H}\). Representing \(K=Q'\varLambda Q\) as above, where \(\varLambda \) is diagonal with nonnegative entries and \(Q'Q=I\), we have
The matrix \((\varLambda +aI)^{-1}\varLambda \) is diagonal with the diagonal entries in the semi-open interval [0, 1). Since \(Q'Q=I\), the columns of Q are vectors of length 1. By (32), each diagonal element of H is then of the form \(\sum _{i=1}^n \lambda _i q_i^2\), where all \(\lambda _i\in [0,1)\) and \(\sum _{i=1}^n q_i^2 = 1\). We can see that each diagonal element of H is in [0, 1).
The equality (11) itself was used only for motivation, so we do not prove it; for a proof in the non-kernelized case, see, e.g., [14, (4.11) and Appendix C.7].
Proof of Lemma 2
In our proof of \(B_i>0\) we will assume \(a>0\), as usual. We will apply the results discussed so far in this appendix to the matrix \(\bar{H}\) in place of H and to \(n+1\) in place of n.
Our goal is to check the strict inequality
remember that both \(\bar{h}_{n+1}\) and \(\bar{h}_i\) are numbers in the semi-open interval [0, 1). The inequality (33) can be rewritten as
and in the weakened form
follows from [3, Property 2.6(b)] (which can be applied to \(\tilde{H}\)).
Instead of the original hat matrix \(\bar{H}\) we will consider the extended matrix (31), where \(\tilde{X}\) is defined by (30) with \(\bar{X}\) in place of X. The elements of \(\tilde{H}\) will be denoted \(\tilde{h}\) with suitable indices, which will run from \(-p+1\) to \(n+1\), in order to have the familiar indices for the submatrix \(\bar{H}\). We will assume that we have an equality in (34) and arrive at a contradiction. There will still be an equality in (34) if we replace \(\bar{h}\) by \(\tilde{h}\), since \(\tilde{H}\) contains \(\bar{H}\). Consider auxiliary “random residuals” \(E:=(I-\tilde{H})\epsilon \), where \(\epsilon \) is a standard Gaussian random vector in \(\mathbb {R}^{p+n+1}\); there are \(p+n+1\) random residuals \(E_{-p+1},\ldots ,E_{n+1}\). Since the correlation between the random residuals \(E_i\) and \(E_{n+1}\) is
(this easily follows from \(I-\tilde{H}\) being a projection matrix and is given in, e.g., [3, p. 11]), (35) is indeed true. Since we have an equality in (34) (with \(\tilde{h}\) in place of \(\bar{h}\)), \(E_i\) and \(E_{n+1}\) are perfectly correlated. Remember that neither row number i nor row number \(n+1\) of the matrix \(I-\bar{H}\) are zero (since the diagonal elements of \(\bar{H}\) are in the semi-open interval [0, 1)), and so neither \(E_i\) nor \(E_{n+1}\) are zero vectors. Since \(E_i\) and \(E_{n+1}\) are perfectly correlated, the row number i of the matrix \(I-\tilde{H}\) is equal to a positive scalar c times its row number \(n+1\). The projection matrix \(I-\tilde{H}\) then projects \(\mathbb {R}^{p+n+1}\) onto a subspace of the hyperplane in \(\mathbb {R}^{p+n+1}\) consisting of the points with coordinate number i being c times the coordinate number \(n+1\). The orthogonal complement of this subspace, i.e., the range of \(\tilde{H}\), will contain the vector \((0,\ldots ,0,-1,0,\ldots ,0,c)\) (\(-1\) being its coordinate number i). Therefore, this vector will be in the range of \(\tilde{X}\) (cf. (31)). Therefore, this vector will be a linear combination of the columns of the extended matrix (30) (with \(\bar{X}\) in place of X), which is impossible because of the first p rows \(\sqrt{a}I_p\) of the extended matrix.
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Vovk, V., Nouretdinov, I., Manokhin, V., Gammerman, A. (2018). Conformal Predictive Distributions with Kernels. In: Rozonoer, L., Mirkin, B., Muchnik, I. (eds) Braverman Readings in Machine Learning. Key Ideas from Inception to Current State. Lecture Notes in Computer Science(), vol 11100. Springer, Cham. https://doi.org/10.1007/978-3-319-99492-5_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-99492-5_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-99491-8
Online ISBN: 978-3-319-99492-5
eBook Packages: Computer ScienceComputer Science (R0)