
Abstract
The notion of comparable corpora rests on our ability to assess the difference between corpora which are claimed to be comparable, but this activity is still art rather than proper science. Here I will discuss attempts at approximating the content of corpora collected from the Web using various methods, also in comparison to traditional corpora, such as the BNC. The procedure for estimating the corpus composition is based on selecting keywords, followed by hard clustering or by building topic models. This can apply to corpora within the same language, e.g., the BNC against ukWac as well as to corpora in different languages, e.g., webpages collected using the same procedure for English and Russian.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
- 2.
http://www.comp.leeds.ac.uk/biosystems/neuroscience.shtml from the time it was collected for ukWac.
- 3.
As done, for example, in [10].
- 4.
The Oxford Russian Dictionary, for example, translates
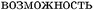
by possibility, opportunity, means, resources. Unlike the Giza++ dictionary, this does not cover the full range of probable translation equivalents and does not estimate their frequency.
- 5.
The ids are from the BNC index [12].
- 6.
Lemmatisation of term elements in Russian affects the syntactic pattern of the composite term [18].

References
Adafre, S., de Rijke, M.: Finding Similar Sentences Across Multiple Languages in Wikipedia. In: Proceedings 11th EACL, pp. 62–69. Trento (2006)
Babych, B., Hartley, A.: Meta-Evaluation of Comparability Metrics using Parallel Corpora. In: Proceedings CICLING, (2011)
Baroni, M., Bernardini, S.: Bootcat: Bootstrapping Corpora and Terms from the Web. In: Proceedings of LREC2004. Lisbon (2004). http://sslmit.unibo.it/~baroni/publications/lrec2004/bootcat_lrec_2004.pdf
Baroni, M., Bernardini, S., Ferraresi, A., Zanchetta, E.: The WaCky wide web: a collection of very large linguistically processed web-crawled corpora. Lang. Resour. Eval. 43(3), 209–226 (2009)
Blancafort, H., Daille, B., Gornostay, T., Heid, U., Mechoulam, C., Sharoff, S.: TTC: Terminology Extraction, Translation Tools and Comparable Corpora. In: Proceedings EURALEX2010. Leeuwarden (5–6 July 2010)
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent Dirichlet allocation. J. Mach. Learning Res. 3, 993–1022 (2003)
Chang, J., Boyd-Graber, J., Wang, C., Gerrish, S., Blei, D.M.: Reading Tea Leaves: How Humans Interpret Topic Models. In: Proceedings Neural Information Processing Systems (2009)
Eisele, A., Chen, Y.: MultiUN: A multilingual Corpus from United Nations Documents. In: Proceedings of the Seventh Conference on International Language Resources and Evaluation (LREC’10). Valletta, Malta (2010). http://www.euromatrixplus.net/multi-un/
Joho, H., Sanderson, M.: The SPIRIT collection: an overview of a large web collection. SIGIR Forum 38(2), 57–61 (2004)
Kilgarriff, A.: Comparing corpora. Int. J. Corpus Linguistics 6(1), 1–37 (2001)
Koehn, P.: Europarl: A Parallel Corpus for Statistical Machine Translation. In: Proceedings MT Summit 2005 (2005). http://www.iccs.inf.ed.ac.uk/pkoehn/publications/europarl-mtsummit05.pdf
Lee, D.: Genres, registers, text types, domains, and styles: clarifying the concepts and navigating a path through the BNC jungle. Lang. Learning Technol. 5(3), 37–72 (2001). http://llt.msu.edu/vol5num3/pdf/lee.pdf
Li, B., Gaussier, E.: Improving Corpus Comparability for Bilingual Lexicon Extraction from Comparable Corpora. In: Proceedings COLING’10. Beijing, China (August 2010)
Och, F.J., Ney, H.: A systematic comparison of various statistical alignment models. Comput. Linguistics 29(1), 19–51 (2003)
Rayson, P., Berridge, D., Francis, B.: Extending the Cochran Rule for the Comparison of Word Frequencies Between Corpora. In: Proceedings 7th International Conference on Statistical Analysis of Textual Data (JADT 2004), pp. 926–936. Louvain-la-Neuve (2004)
Sharoff, S.: Creating general-purpose corpora using automated search engine queries. In: Baroni, M., Bernardini, S. (eds.) WaCky! Working Papers on the Web as Corpus. Gedit, Bologna (2006). http://wackybook.sslmit.unibo.it
Sharoff, S.: In the garden and in the jungle: Comparing genres in the BNC and Internet. In: Mehler, A., Sharoff, S., Santini, M. (eds.) Genres on the Web: Computational Models and Empirical Studies, pp. 149–166. Springer, Berlin (2010)
Sharoff, S., Kopotev, M., Erjavec, T., Feldman, A., Divjak, D.: Designing and evaluating a Russian tagset. In: Proceedings of the Sixth Language Resources and Evaluation Conference, LREC 2008. Marrakech (2008)
Steinbach, M., Karypis, G., Kumar, V.: A Comparison of Document Clustering Techniques. In: KDD Workshop on Text Mining (2000)
Zhao, Y., Karypis, G.: Empirical and theoretical comparisons of selected criterion functions for document clustering. Machine Learning 55(3), 311–331 (2004)
Acknowledgments
The research leading to these results has received funding from the European Community’s Seventh Framework Programme (FP7/2007-2013) under Grant Agreement No 248005, project TTC.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this chapter
Cite this chapter
Sharoff, S. (2013). Measuring the Distance Between Comparable Corpora Between Languages. In: Sharoff, S., Rapp, R., Zweigenbaum, P., Fung, P. (eds) Building and Using Comparable Corpora. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-20128-8_6
Download citation
DOI: https://doi.org/10.1007/978-3-642-20128-8_6
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-20127-1
Online ISBN: 978-3-642-20128-8
eBook Packages: Computer ScienceComputer Science (R0)