
Abstract
A Recommender System (RS) provides personalized suggestions of objects of users’ interest or that they may like. Traditional RS techniques consider only aspects related to users and items to recommend and ignore contextual information. Context-Aware RS (CARS) consider information about the user’s context to improve the recommendation process. Time is adimension of context that has the advantage of being easy to collect, since almost any system can record the interaction timestamp. Moreover, time can serve as valuable input for improving recommendation quality. Therefore, this work aims to investigate how time is being applied in CARS and, for this purpose, we used a Systematic Mapping methodology. In total, 88 papers were considered to answer the research questions defined. Initially we observed that the papers’ distribution by year have been increased in the last years. As a result, we also defined seven categories of how CARS uses the time in recommendation process.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Recommender Systems (RS) are computational tools that supports users in finding items of their interest, especially when the amount of available items is huge. According to Burke [1] a RS is any system that provides personalized recommendation or that has the effect of guiding the user in a personalized way to interesting or useful items among several possible options.
Traditional RS consider only the users and available items, not taking into ac-count the context where these items are inserted [2]. Context is any information that can be used to characterize the situation of an entity [3]. An entity, in the domain of a RS, could be the users of the system or the items to be recommended.
Among possible context information, time is being explored in RS in several application domains, e.g., movie recommendation [4], tourism domain [5, 6], restaurants recommendation [7, 8] and in e-commerce [9, 10]. The recent interest in this area is observed by Campos et al. [11] in their state-of-the-art review.
This work aims to identify how time is used in Context-Aware RS (CARS) of diverse application domains. For this purpose, the methodology chosen is a bibliographic study through a systematic mapping defined by Petersen et al. [12].
The paper is organized as follows. Section 1 presents the introduction. In Sect. 2 the theoretical background is described. In Sect. 3 the related work is presented. Section 4 presents the Systematic Mapping Process. In Sect. 5 the classification of time is proposed, where we defined seven categories based on how the time is used in CARS. In Sect. 6 is presented the results of the Systematic Mapping and a discussion about these results. Section 7 contains the final remarks.
2 Theoretical Background
Recommender Systems (RS) algorithms are usually divided in the following approaches [13, 14]: Content-based, Collaborative Filtering, Knowledge-based and Hybrid.
According to Lops et al. [15], Content-based approach is the one that recommends to the user items similar to what he had interest in the past. It consists of comparing the similarity between an item and the user’s interests. This approach is strongly related to Information Retrieval area, due to the fact that the item and the user’s interests are usually represented by a set of keywords [13]. The main advantages of this approach are: (a) it does not need an active community of users to recommend and (b) the possibility to recommend new items in the system that any user used or rated. The main drawbacks are the User Cold Start (new users in the system do not have a defined profile) and the Overspecialization (user can always receive items very similar to what he already saw).
In Collaborative Filtering approach, user receives as recommendation items that users with similar tastes had interest in the past, i.e., it is the automatization of the word-of-mouth process [16]. This approach assumes that people who have had similar preferences in the past tend to agree in the future [14]. As this approach considers only users with similar tastes to recommend and not the items description, the main advantage of this approach are the serendipity (phenomenon of finding valuable or agreeable things not sought for) and that the quality of the item is considered (not only its description). The main drawbacks of this approach are the need of an active community to recommend, the User Cold-Start (new users will not receive recommendation because not rated any item yet), the Item Cold-Start (new items will not be recommended because were not rated by anyone yet) and the difficulty to recommend to users with unusual interests (called black sheep).
Knowledge-based approach recommends items to users based on the knowledge the system has about how the item’s characteristics matches the user needs and how useful this item would be [17]. This approach is mostly used together with others approach aiming to improve recommendation quality or to avoid some drawback. Knowledge-based RS are developed where the knowledge about the domain is available in some structured machine-readable form, e.g., an ontology [13]. The main advantage of this approach is that it usually improve recommendation quality when applied together with others approaches. The main drawback of this approach is that it needs the knowledge acquire and representation, and it is not always possible.
Hybrid approach combines two or more approaches to recommend items to users. Its goal is to gather the advantages of each approach and tries to avoid its drawbacks [1]. Some examples of this combination are [1]: Feature augmentation, where one approach is applied first and the result is applied in the next. Switching, where there is an alternation between the approaches and the RS has criteria to decide which one to use. Mixed, where the approaches are used separately and the result of each one appears in the same ranking, but this hybridization is most used if it is practical to make large number of recommendations simultaneously.
CARS considers context information where the item is going to be consumed, beyond the information already used by traditional approaches. According to Adomavicius and Tuzhilin [18], there are three paradigms in which context can be part of the recommendation process: Contextual Pre-Filtering, Contextual Post-Filtering and Contextual Modeling. In Contextual Pre-Filtering contextual information drives data selection or data construction for that specific context and then traditional approaches are used. In Contextual Post-Filtering initially traditional approaches are used without any contextual information, and then the resulting set of recommendations is adjusted for each user using the contextual information. In Contextual Modeling contextual information is used directly in the recommendation technique as part of rating/usefulness estimation.
Context dimensions are categories of contextual information, where each of them are defined by set of attributes, in different levels of granularity. For example. Location is a context dimension that could assume values like Brazil (less granular) or “200 Paulo Malschitzki Street, Joinville” (more granular). There are different set of dimensions that could represent context [19,20,21]. In this work, we follow Schmidt et al. [22] that defines the following dimensions:
-
Information on the user, e.g., users’ habits, users’ emotional state, etc.;
-
User’s social environment, e.g., co-location with others users, social interaction in social networks, etc.;
-
User’s tasks, e.g., general goals, whether it is a defined task or random activity, etc.;
-
Location, e.g., absolute position, whether the user is at home or office, etc.;
-
Physical conditions, e.g., noise, light, etc.;
-
Infrastructure, e.g., network bandwidth, type of device, etc.;
-
Time, that could be categorical, e.g., Time of the day (Morning, Afternoon, Evening), or continuous, e.g., a timestamp like “June 1st, 2016 at 17:14:36”.
According to Adomavicius and Tuzhilin [18], depending on the application domain and the available data, at least some contextual information might be useful to improve the recommendation process. Among all context dimensions, time has an advantage to be easy to capture, considering that almost every device has a clock that could capture the timestamp when an interaction occurs. Besides that, works in this area showed that the context of time has potential to improve recommendation quality [11]. This kind of RS is called Time-Aware Recommender Systems (TARS).
According to Campos et al. [11], time dimension can be represented in continuous format (e.g., as a timestamp like “June 1st, 2016 at 17:14:36”) or in categorical format (e.g., Days_of_the_week = {Monday, Tuesday, Wednesday, …, Sunday} or Time_of_the_day = {Morning, Afternoon, Evening}.
3 Related Work
In order to understand the TARS field, this work conducts a systematic research and analysis of papers to identify how the time is used in Context-Aware RS in several application domains. We identified two works that also uses literature review with similar objectives: Pereira et al. [23] and Campos et al. [11].
Pereira et al. [23] executes a systematic mapping to identify which context dimensions are used in Context-Aware RS in e-learning domain. This study considered 30 papers and showed that the most used context dimension in this domain is Information on the user (with 22 papers), followed by Infrastructure (with 14 papers). Time appears in the 4th place, with 8 papers. This studied also identified that time is represented in this 8 papers as Timetable or Time interval, both as continuous format.
Campos et al. [11] presents a literature review of Time-Aware RS.In this research it is explained the main recommendation strategies and algorithms using time, and evaluation methods to this kind of RS. Then, the authors proposed a framework on how to evaluate Time-Aware RS.
The work of Pereira et al. [23] is limited to recommendation in e-learning environments, while Campos et al. [11] is more focused to evaluation of Time-Aware RS, although it makes a review of the main algorithms of the area. In this way, this paper presents a Systematic Mapping looking to identify how the time is used in Context-Aware RS in several application domains (not only e-learning) and thus describe the area. It is worth saying that, on how the time is used in RS, classification of Time-Aware RS is proposed based on the works studied and is a contribution of this work.
4 Methodology: Systematic Mapping Process
In this work was executed a Systematic Mapping based on Petersen et al. methodology [12]. This methodology is frequently used in medical research, but can be applied in others domains too, allowing a structured research (that could be replicated) and quantitative results in order to answer the research questions [12]. That’s why the results of a systematic mapping are usually represented by visual charts and maps of the desired domain.
The essential steps of the Systematic Mapping, as seen in Fig. 1, are [12]: (1) Definition of Research Questions, where are defined the research goal and results in the Review Scope. (2) Conduct Search, where all potentially relevant papers are identified. (3) Screening of papers, based on selection criteria only papers relevant to the research remains. (4) Keywording using Abstracts, where researchers look for keywords and concepts that reflects the contribution of the each paper and the set of keywords from different papers are combined together to develop a high level understanding about the nature and state of the field. (5) Data Extraction and Mapping of Studies, based on the classification made in step 4 the papers are categorized and relevant information are extracted and represented visually.

Systematic Mapping process [12].
4.1 Research Questions
The Main Research Question (MRQ) that this work aims to answer is:
-
MRQ: How the time is used in Context-Aware Recommender Systems?
In order to answer the MRQ, three Secondary Research Questions (SRQ) where defined below. Answering all SRQ make this work answer the MRQ.
-
SRQ1: How recommender algorithms use time?
-
SRQ2: What are the differences about the use of time in different application domains?
-
SRQ3: What others context dimensions are used to be applied together with time dimension?
4.2 Conduct Search
Take into account the research questions, it was defined the main keywords related to this research. The identified keywords used as the search arguments are (time-aware OR context-aware) AND (“recommender system”). These search arguments were used in three Academic Search Engines (ASE): IEEE Xplorer, Scopus and Springer Link. These ASE were chosen because they have a huge amount of content in Computer Science and have the necessary search and filtering mechanisms.
The defined search arguments intent to find for papers about Time-Aware Recommender Systems or about Context-Aware Recommender Systems, that could use time dimension to recommend. This search argument were used in each one of three ASE, looking for papers that presents these keywords in the Title, Abstract or Keywords (also called Topic in some ASEs).
Three constrains were defined to filter more relevant papers to our research. These constrains are called Objective Criteria (OC). As the first OC was defined that we will consider only papers published in the last ten years from beginning of this work, i.e., from 2006 to 2016. As the second OC was defined that, we will consider only papers fully available to download. This constrain is also related to the ASE. The third OC is the language, where only papers in English were considered. This last constraint were applied manually by the authors, although some ASE allows to filter for language.
4.3 Screening of Papers
After conducing search on all ASE, Inclusion and Exclusion Criteria must be applied to obtain only papers relevant to answer the research questions. The Inclusion Criteria (IC) and Exclusion Criteria (EC) are:
-
IC1: Include only papers that aims to describe a strategy (i.e., algorithm, framework, method, model, etc.) to recommend.
-
EC1: Exclude papers that do not use time to recommend or do not explain how time is used.
-
EC2: Exclude duplicates or different papers related to the same work.
For a paper be considered for the research it must be accepted by IC1 and not be eliminated by EC1 neither EC2. The process was documented, registering which criterion eliminates each paper.
4.4 Classification Scheme and Data Extraction
After selecting all relevant papers, next step involves reading and classifying papers to answer the research questions. The results of this step are the categories defined in Sect. 5 and the charts and analysis in Sect. 6. The main data extracted of the papers were: (1) Publication Year; (2) Paper’s authors; (3) Application Domain; (4) If time is used as Categorical or Continuous; (5) how the time is applied (i.e., Pre-filtering, Post-filtering or Modeling); (6) In which use of time category the recommendation are classified; (7) what others dimensions are used in the recommendation process. First, only Abstracts was read, as directed by Petersen et al. [12]. But, when it was necessary, a superficial reading of the full paper was executed, trying to answer the research questions.
5 Use of Time Categories
During the Systematic Mapping process, it was observed patterns of the use of time in the Recommender Systems (RS) studies. The works that use time in a similar way were grouped together, based on when the time appears in the recommendation process and how time affects the recommendation. Seven categories of how the time is used in RS were defined. The names to these categories were given by the authors of this paper trying to find the nomenclature that best represents each category. Using these categories, we aim to summarize how the time can be used in RS. The categories are:
-
Restriction: the time is used to restrict which items are recommended, take into account the available of items in a certain time and the user’s available time with time required to use the item. Examples: recommend only restaurants that are open when user’s going to have lunch [24].
-
Micro-profile: the user has different profiles for each time. Here, time is usually categorical. Thus the user has a profile for weekdays and a profile for weekends, or the user has a profile for morning, a profile for afternoon and another for evening. Example: recommend a mobile app to the user at Sunday morning based only in apps used by this user in past Sunday mornings [25].
-
Bias: time is the third dimension of a User x Item matrix. So, collaborative filtering has more information for identifying similar users and to predict user’s rating to a non-viewed item. Example: Koren [4] uses a similar strategy at the Netflix Grand Prize, where he proposes a Tensor Factorization strategy using a User x Item x Time tensor.
-
Decay: it uses time as a decay factor, in which old interactions are less important than new ones, but are not discarded. Example: in E-commerce, it considers items the user searched recently more important when deciding what products to recommend, and give older searches less impact at recommendation [26].
-
Time Rating: time supports the RS to understand user’s preferences, e.g., the more the user stays at the item, more he likes it. It means that time gives feedback to an item implicitly to a user, i.e., without need of user rate the item. Example: in Smart TVs, consider that TV programs the user watches more often and for longer are the ones he likes, helping the RS to find others programs to recommend [27].
-
Novelty: only new items will be recommended. The RS has a threshold and items older than a specific timestamp it will not recommended. Example: in news website, it’s better to recommend news of, at most, one day ago [28].
-
Sequence: the RS observe items that are usually consumed following a sequence. Thus, if the first of the sequence is consumed, the second should probably be consumed too. Example: in music recommendation, songs of the same album are most likely to be heard together, so if the user selects one of them, the next one should be recommended [29].
6 Results
The search for relevant papers, as described in Sect. 4, were done in June 2016. Table 1 show all selection process executed in this search. At beginning, 561 papers were accessed from the three ASE. After applying OC, 556 papers remains. From these papers, 333 papers matched IC1 and were keep. After applying EC1 e EC2, 88 papers that are relevant to this research were kept. In the next subsections the analysis of these 88 papers and the answers to the research questions are presented.
6.1 Analysis
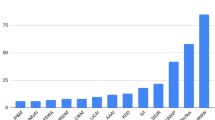
Figure 2 presents the distribution of the 88 papers by year. The results indicate that the use of time in recommender systems is a subject with increasing interest by researchers. The year of 2012 was the one with more papers published (16 papers), and from 2011 to 2015 the number of publications is almost uniform (between 13 and 16 papers). On 2016, the number of publications was less than the previous year, but it is necessary to observe that the research was executed in June 2016. The growing between 2006 and 2011 shows RSs considering context (time context, in this case), information that were not considered in the pioneering RS.

Papers distribution by year.
6.2 How Recommender Algorithms Uses Time?
In order to answer the Main Research Question (MRQ) and understand how the time is used in Context-Aware Recommender Systems, it was necessary to answer three Secondary Research Questions (SRQ). The first SRQ involves how recommender algorithms use time. In this sense, Fig. 3 presents which RS approach (described in Sect. 2) is used in Time-Aware RS. It is possible to observe Collaborative Filtering is the most used approach, appearing in 41% of all papers. This number probably bigger, because most of Hybrid algorithms combines Collaborative Filtering with other approach. All other approaches appear with almost the same percentage. It is worth pointing out that Knowledge-based approach is not as traditional as Collaborative Filtering or Content-based, but it is often used, maybe because many RSs use contextual information through ontology inference.

Recommender System approach used.
Figure 4 shows how time is represented in the analyzed papers, i.e., categorical or continuous (described in Sect. 2). It is possible to see that the majority represents time in Continuous format, with 63%, while only 37% represents it in a Categorical format.

Time format.
It was also analyzed how time is applied in recommendation process, and could be Pre-Filtering, Post-Filtering or Modeling (this distinct process are described in Sect. 2). Figure 5 shows that Modeling is the most common application way (44% of the papers), followed by Post-Filtering (31%) and Pre-Filtering (25%).

Time application.
Another analysis were made considering the use of time, i.e., how the time influences the recommendation process. To do this analysis, seven categories were observed and are explained in more detail in Sect. 4. Figure 6 shows how the papers analyzed in the work uses time, take into account the categories defined in the Sect. 6. Some papers use of time in more than one way, because of this there are more 88 papers listed in the chart. We can see that Restriction is the most common use of time (in 29 papers), followed by Micro-profile (24 papers) and Bias (19 papers).

Use of time.
6.3 What Are the Differences About the Use of Time in Different Application Domains?
To answer SRQ2, about the difference between the use of time in different application domains, first there is a need to define the applications domains identified in the analyzed papers. The applications domains identified are:
-
Generic: works not related to a specific application domain. These works just propose an algorithm that could be applied in any domain.
-
Apps: recommendation of applications that the user may be interested, like walking apps, weather apps, investing apps, etc. The apps include mobile apps or web apps.
-
E-commerce: recommendation of products in electronic commerce sites.
-
E-learning: recommendation of learning materials to support learning process in e-learning environments.
-
Scientific Events: presents recommendation of presentations to watch in a scientific event, e.g., an academic conference.
-
Multimedia: recommendation of multimedia resources, e.g., music, movies, videos, images, etc.
-
Museum: recommendation of artwork or others exhibitions to visitors inside a museum.
-
News: recommendation of news to users.
-
Points-of-Interest: recommendation of points-of-interest, e.g., touristic attractions, events, shows, restaurants, hotels, etc. These papers are usually related to tourism.
-
Advertising: recommendation of advertisement to the user, similar to ads recommended in social networks and search engines that are based on user behavior.
-
Social Network: recommendation of content (e.g., posts) or other users (e.g., new friends) in social networks.
-
Walking route: papers that presents recommendation of routes to walking, from the actual position.
-
Others: this category represents application domains that appear in just one paper. In summary, there are seven applications domains joining in this category: physical activity recommendation, movie sessions recommendation, recommendation in sharing economy app, social events recommendation, cook recipes recommendation, sales recommendation in a mall and tasks recommendation.
Figure 7 shows that the most common application domain is Multimedia (with 16 papers), followed by Point-of-Interest (with 15 papers) and Apps recommendation (with 13 papers).

Application domains.
The application domains aforementioned were analyzed separately to understand how the time is used in each of them. Figure 8 shows the analysis about the time format, i.e., how the time is represented in each domain. The chart shows that continuous format overcome categorical in all domains, being in equal of greater number in each of them.

Domain vs. time format.
Figure 9 shows the comparison of each of the 13 application domain with how the time is applied. It is possible to observe that, depending on the application domain one paradigm is more used than the others, but there is not one that dominates the others for all domains. For example: in Apps recommendation, Pre-Filtering is most common way to apply the time, while in Point-of-Interest recommendation the most common is Post-Filtering and in Multimedia recommendation Modeling is the most used. It is important to analyze and use this information to implement a new RS for a determined domain.

Domain vs. contextual paradigm.
It was also analyzed the application domain with the Use of Time category defined in Sect. 5. Figure 10 shows this analysis. It is possible to observe that certain domains have higher trend to use the time according to some of the defined categories. For example: in Point-of-Interest recommendation the most common use of time category is Restriction, maybe due to this kind of recommendation worry whether the establishment possible to recommendation is open or closed at the time the user arrives there. In Apps recommendation the most common category is Micro-Profile, due the strategy of this domain of comparing the current time of the user (e.g., time of the day, day of the week, month of the year, season, etc.) with that the user have done in similar conditions and so recommend more personalized to the user. In E-learning, the recommendation uses Decay (recommending more based on what the user last studied) and Restriction (recommending items with duration that matches the user available time).

Domain vs. use of time.
6.4 What Others Context Dimensions Are Used to Be Applied Together with Time Dimension?
To answer the last SRQ were extracted from the papers which others context dimensions are used, based on the definition of Schmidt et al. [22] (described in Sect. 2). Figure 11 shows this analysis. It is possible to see that location appears in most papers (70 papers out of 88), followed by Information about the user (46 papers) and Social environment (24 papers). From the 88 papers, 10 use just time dimension or do not specify the others context dimensions used.

Others dimensions used together with time.
7 Conclusion
In this work, were executed a Systematic Mapping to investigate the Time-Aware Recommender Systems in several application domains. The goal of this work is identify how the algorithms of this area are used, answer the research question defined (How the time is used in Context-Aware Recommender Systems?). With this Systematic Mapping, we hope to support other researches to understand this research area and how the algorithms are being used.
The use of time (categories defined in Sect. 5) most common are Restriction, Micro-profiles and Bias. The format of time most used is continuous and the paradigm of time application most used is Modeling. The dimension most used together with time is location that appears in almost all papers. We consider that this fact occurs because nowadays it is easy to obtain user’s location using mobile devices.
One of the contributions of the present work, through the Systematic Mapping, is related to the fact that we have identified that depending on the application domain the way the time is applied is very distinct. This information can be useful for researchers who want to develop a RS’s in a specific domain (e.g. is it value to recommend an old new to users of a SR that recommend news?). Besides, it is possible to think in use the dimension time in a different way.
References
Burke, R.: Hybrid recommender systems: survey and experiments. User Model. User-adapt. Interact. 12, 331–370 (2002)
Verbert, K., Manouselis, N., Ochoa, X., Wolpers, M., Drachsler, H., Bosnic, I., Duval, E.: Context-aware recommender systems for learning: a survey and future challenges. IEEE Trans. Learn. Technol. 5, 318–335 (2012)
Dey, A.K.: Understanding and using context. Pers. Ubiquit. Comput. 5, 4–7 (2001)
Koren, Y.: The bellkor solution to the netflix grand prize. Netflix Prize Doc. 81, 1–10 (2009)
Anacleto, R., Figueiredo, L., Almeida, A., Novais, P.: Mobile application to provide personalized sightseeing tours. J. Netw. Comput. Appl. 41, 56–64 (2014)
Baltrunas, L., Ludwig, B., Peer, S., Ricci, F.: Context relevance assessment and exploitation in mobile recommender systems. Pers. Ubiquit. Comput. 16, 507–526 (2012)
Bedi, P., Richa, S.: User interest expansion using spreading activation for generating recommendations. In: 2015 International Conference on Advances in Computing Communication Informatics, ICACCI 2015, pp. 766–771 (2015)
Chu, C.H., Wu, S.H.: A Chinese restaurant recommendation system based on mobile context-aware services. In: Proceedings of IEEE International Conference on Mobile Data Management, vol. 2, pp. 116–118 (2013)
Blanco-Fernández, Y., López-Nores, M., Pazos-Arias, J.J., García-Duque, J.: An improvement for semantics-based recommender systems grounded on attaching temporal information to ontologies and user profiles. Eng. Appl. Artif. Intell. 24, 1385–1397 (2011)
Haddad, M.R., Baazaoui, H., Ziou, D., Ghezala, H.B.: A model-driven approach for context-aware recommendation (2012)
Campos, P.G., Díez, F., Cantador, I.: Time-aware recommender systems: a comprehensive survey and analysis of existing evaluation protocols. User Model. User-adapt. Interact. 24, 67–119 (2014)
Petersen, K., Feldt, R., Mujtaba, S., Mattsson, M.: Systematic mapping studies in software engineering. In: 12th International Conference on Evaluation Assessment in Software Engineering, vol. 17, p. 10 (2008)
Adomavicius, G., Tuzhilin, A.: Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 17, 734–749 (2005)
Ricci, F., Rokach, L., Shapira, B.: Introduction to recommender systems handbook. In: Ricci, F., Rokach, L., Shapira, B., Kantor, P.B. (eds.) Recommender System: Handbook, pp. 1–35. Springer, Heidelberg (2011)
Lops, P., de Gemmis, M., Semeraro, G.: Content-based recommender systems: state of the art and trends. In: Ricci, F., Rokach, L., Shapira, B., Kantor, P.B. (eds.) Recommender System: Handbook, pp. 73–105. Springer, Heidelberg (2011)
Jannach, D., Zanker, M., Felfernig, A., Friedrich, G.: Recommender Systems: An Introduction. Cambridge University Press, Cambridge (2011)
Felfernig, A., Friedrich, G., Jannach, D., Zanker, M.: Developing constraint-based recommenders. In: Ricci, F., Rokach, L., Shapira, B., Kantor, P.B. (eds.) Recommender System: Handbook, pp. 187–215. Springer, Heidelberg (2011)
Adomavicius, G., Tuzhilin, A.: Context-aware recommender systems. In: Ricci, F., Rokach, L., Shapira, B., Kantor, P.B. (eds.) Recommender System: Handbook, pp. 217–253. Springer, Heidelberg (2011)
Schilit, B., Adams, N., Want, R.: Context-aware computing applications. In: IEEE Workshop Mobile Computing Systems Applications, pp. 1–7 (1994)
Chen, G., Kotz, D.: A survey of context-aware mobile computing research (2000)
Zimmermann, A., Lorenz, A., Oppermann, R.: An operational definition of context. In: 6th International Interdisciplinary Conference Context 2007, vol. 1, pp. 558–571 (2007)
Schmidt, A., Beigl, M., Gellersen, H.W.: There is more to context than location. Comput. Graph. 23, 893–901 (1999)
Pereira, C.K., Campos, F., Braga, R., Ströele, V., David, J.M.N.: Elementos de Contexto em Sistemas de Recomendação no Domínio Educacional: um Mapeamento Sistemático. In: XIX Conferência International sobre Informática na Educ, vol. 19, pp. 10 (2014)
Gallego, D., Woerndl, W., Huecas, G.: Evaluating the impact of proactivity in the user experience of a context-aware restaurant recommender for android smartphones. J. Syst. Archit. 59, 748–758 (2013)
Rho, W.H., Cho, S.B.: Context-aware smartphone application category recommender system with modularized bayesian networks. In: 2014 10th International Conference on National Computation ICNC 2014, pp. 775–779 (2014)
Limbeck, P., Suntinger, M., Schiefer, J.: SARI OpenRec–Empowering recommendation systems with business events. In: 2nd International Conference on Advances Databases, Knowledge, Data Applications DBKDA 2010, pp. 111–119 (2010)
Vildjiounaite, E., Kyllönen, V., Hannula, T., Alahuhta, P.: Unobtrusive dynamic modelling of TV program preferences in a household. In: Tscheligi, M., Obrist, M., Lugmayr, A. (eds.) EuroITV 2008. LNCS, vol. 5066, pp. 82–91. Springer, Heidelberg (2008). doi:10.1007/978-3-540-69478-6_9
Montes-García, A., Álvarez-Rodríguez, J.M., Labra-Gayo, J.E., Martínez-Merino, M.: Towards a journalist-based news recommendation system: the wesomender approach. Expert Syst. Appl. 40, 6735–6741 (2013)
Pálovics, R., Benczúr, A.A.: Temporal influence over the Last.fm social network. Soc. Netw. Anal. Min. 5, 1–12 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
de Borba, E.J., Gasparini, I., Lichtnow, D. (2017). Time-Aware Recommender Systems: A Systematic Mapping. In: Kurosu, M. (eds) Human-Computer Interaction. Interaction Contexts. HCI 2017. Lecture Notes in Computer Science(), vol 10272. Springer, Cham. https://doi.org/10.1007/978-3-319-58077-7_38
Download citation
DOI: https://doi.org/10.1007/978-3-319-58077-7_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-58076-0
Online ISBN: 978-3-319-58077-7
eBook Packages: Computer ScienceComputer Science (R0)